Universal_NPU-CNN_Accelerator
hardware design of universal NPU (CNN accelerator) for various convolution neural networks
It can perform various cnns by calculating convolution for multiple clock cycles.
see here https://velog.io/@hyal/%EB%B2%94%EC%9A%A9%EC%A0%81%EC%9D%B8-NPU-%EA%B0%9C%EB%B0%9C%EA%B8%B00-%EB%93%A4%EC%96%B4%EA%B0%80%EA%B8%B0-%EC%95%9E%EC%84%9C (korean)
There are many modules for same function. This is because, I don't have any synthesis tool(vivado is not useful for asic design), so, I can't determine which is most efficient.
If you have suitable tools, such as design compiler or else, please give me timing, area and power reports of modules. It will be very helpful.
Descripton
Mechanism
The whole process is Modified Booth Algorithm -> Wallace Tree -> Relu -> Maxpooling.
Since you can already find plenty of information on the Internet and elsewhere about each step, I won't explain them.
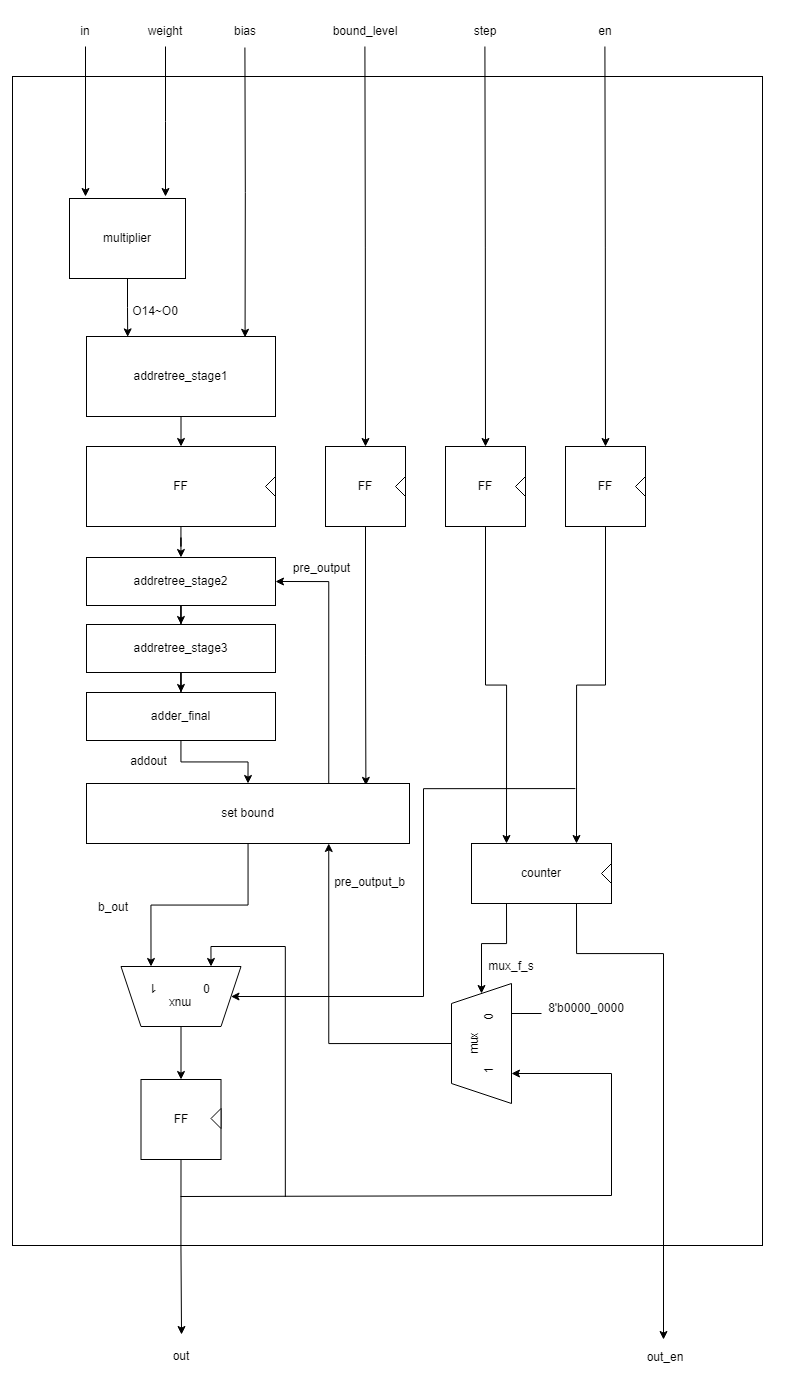
Mechanism for calculating a variety of CNN is so simple. The processing_element module can store its output in a flip-flop, so it can be used in the next clock.
Wallace tree (adder tree) receives previous output from flip-flop and adds it with current multiplication output.
As a result, the output becomes previous weight * previous input + current weight * current input + bias. It's a result of convolution has over 9 weights.
Input
| Input | Description |
|---|---|
| in | Port for input feature map. Each input data is 8bit, and this port receives 9 input datas every clock cycle. |
| weight | Port for weights of filters. Each weight is 8bit, and this port receives 9*8 weights every clock cycle. But it can only receive 9 weights per filter in a clock cycle. |
| bias | Port for biases of filters. Each bias is 16bit, and this port receives 8 biases every clock cycle. |
| bound_level | Port for setting a maximum value and step size of data. output (bound_level=n) = output (bound_level=0) * 2^n = original value * 2^(n-11) |
| step | Port for setting the period for convolution. If you set step=2, processing_element module will compute the convolution for 3 clock cycles, so it can be used to compute a filter with 27 weights. |
| en | Input data validation port |
| en_relu | Port for enabling relu function |
| en_mp | Port for enabling max pooling function |
Module
| Module | Description |
|---|---|
| tb_ap | testbench for ap module. |
| AP | Arithmetic part module. It's a top module of arithmetic part and contains 8 arithmetic_core modules. |
| arithmetic_core | arithmetic_core module contains PE(processing_element), relu and maxpooling module. Whole computation is done in this module. |
| arithmetic_core_mod | It's almost same with arithmetic_core, but it uses PE_m instead of PE. |
| PE | processing element module. It performs convoulution and contains many modules. |
| PE_m | It's almost same witn PE, but it can accept more unstable sigals. |
| relu | It performs relu function. |
| maxpooling | It performs maxpooling. |
| multiplier | It generates partial products from multiplicands and multipliers. |
| PPG | It generates 1 partial product from 1 multiplicand and 1 multiplier. |
| MBE_enc | It transforms a multiplier using modified booth algorithm |
| addertree_stage1 | First step of the wallce tree. |
| addertree_stage2 | Second step of the wallce tree. |
| addertree_stage3 | Third and fourth step of the wallce tree. |
| adder_final | Last step of the wallce tree. It contains half adder, full adder and carry look ahead adders. |
| Many types of adders | There are so many adders. IMPORTANT There are various adders for same function but have different structure. You have to choose from them to enhance efficiency. For example, adder_15to4, adder_15to4_mod and adder_15to4_mod2 are all adders for computing 15 inputs addition, but their architectures are quite different. |
Usage
- run generate_par.py (I use pycharm)
- simulate tb_ap
- run predict.py
If you want to use this module for other cnn model, you have to edit generate_par.py, tb_ap and predict.py for it.
Because control part is not implemented yet, it can't be done automatically.
CNN Model

layer0~3 are calculated by the accelerator.
Architecture
NPU & Arithmetic_part (overall structure)

arithmetic_core

processing_element

processing_element_mod
multiplier

adder_final

Relu

maxpooling
