- DQN
- Vanilla policy Gradient
- Deep Deterministic Policy Gradient
- Twin Delayed Deep Deterministic Policy Gradient
- Soft Actor Critic
- Proximal Policy Optimization - CLIP
Article on deeper Look into policy gradients
| Algorithm | Discrete Env: LunarLander-v2 | Continuous Env: Pendulum-v0 |
|---|---|---|
| DQN | 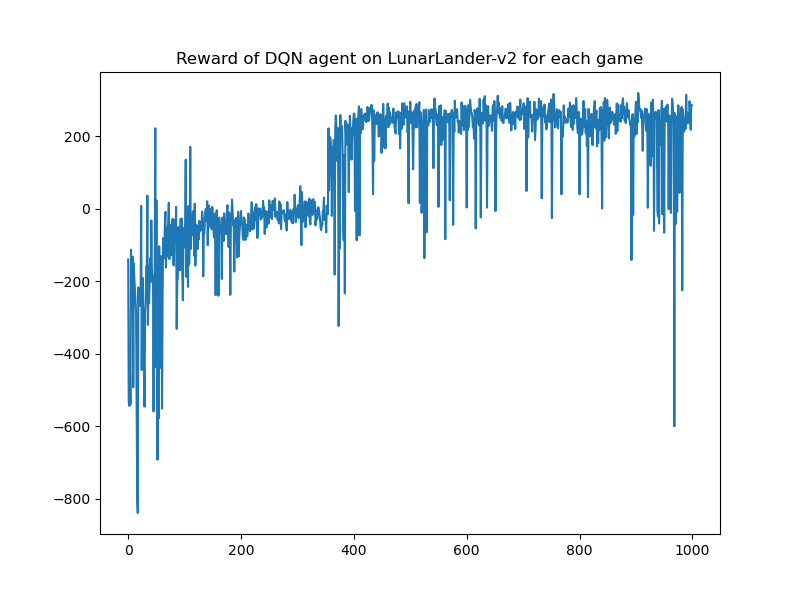 |
- |
| VPG | 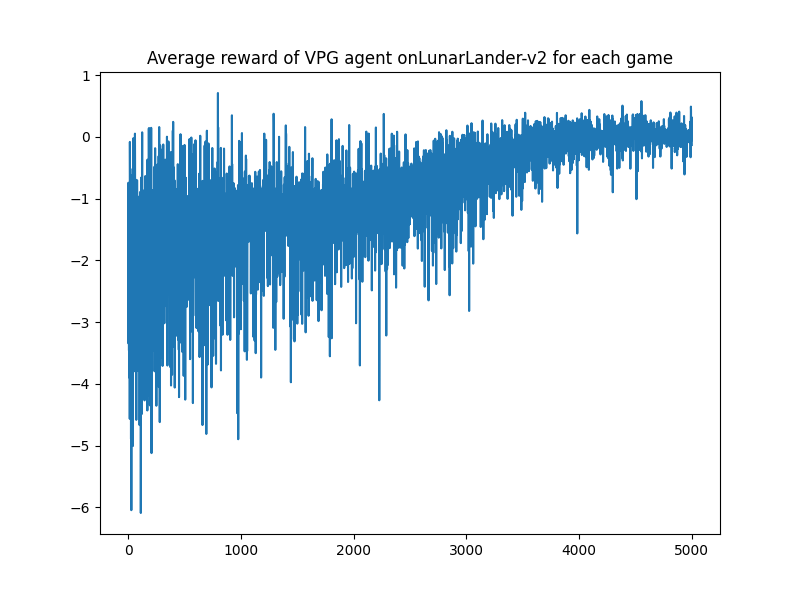 |
- |
| DDPG | - | 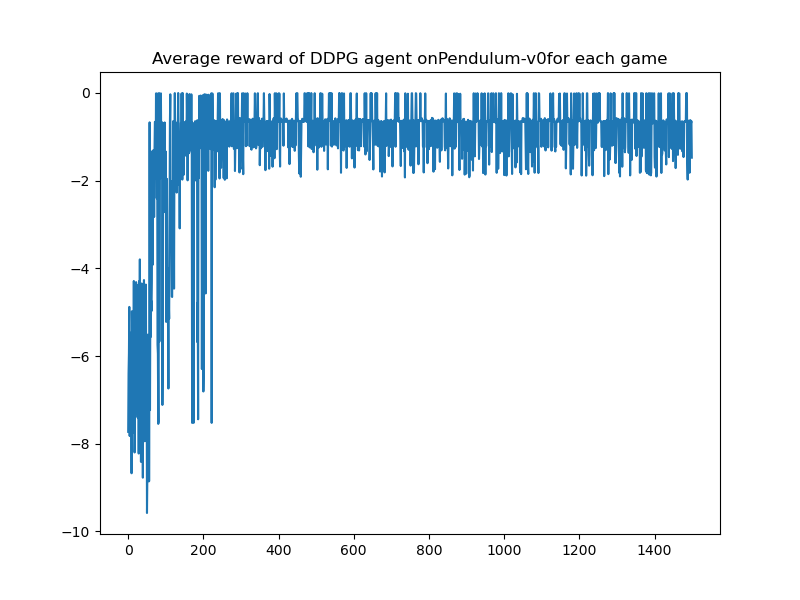 |
| TD3 | - | 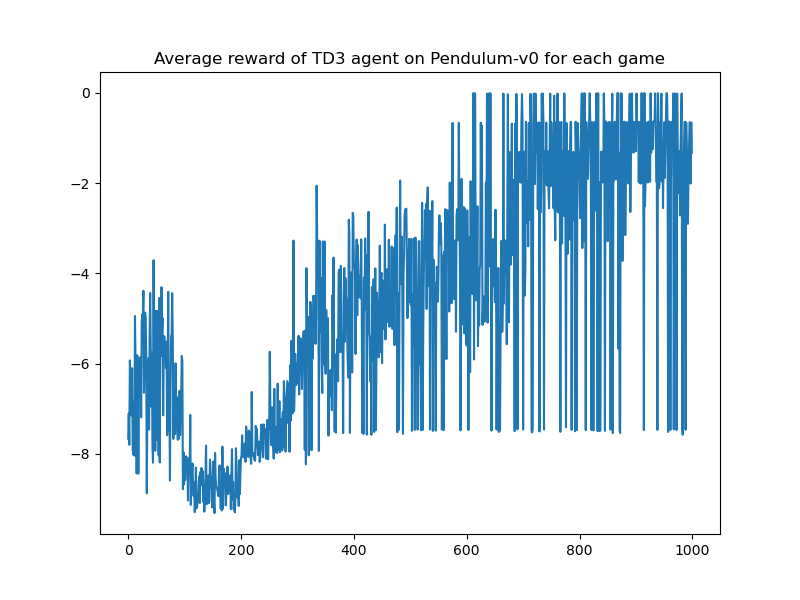 |
| SAC | - | 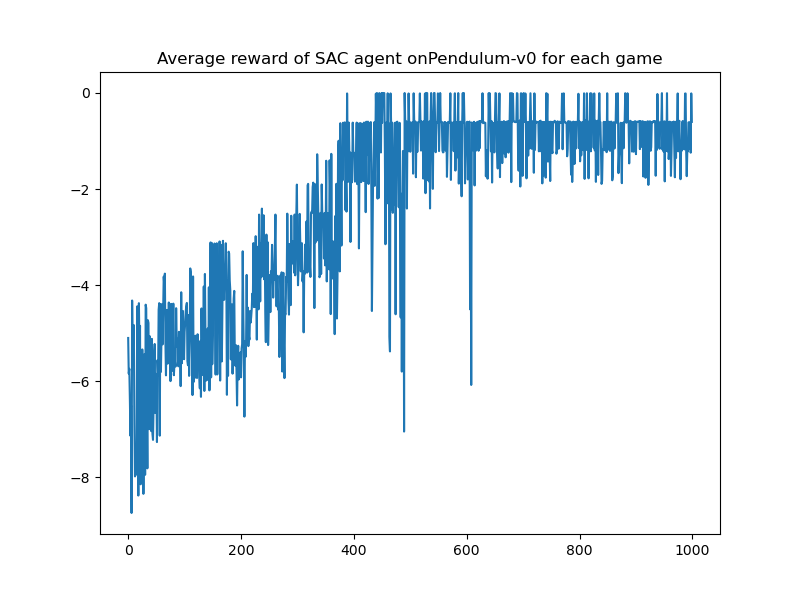 |
| PPO | - | 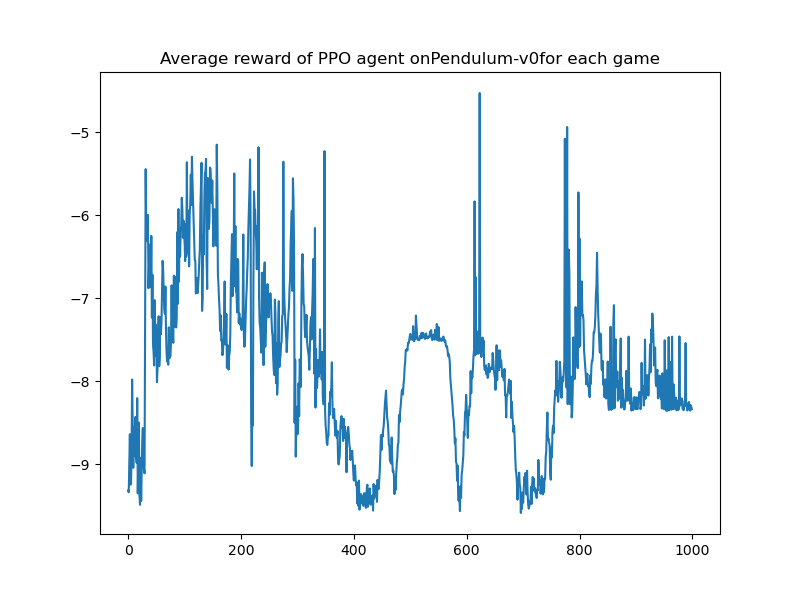 |
Just run the file/algorithm directly. There is no common structures between algorithms as I implemented them as I learnt them. Different algorithms are inspired from different sources.
- RL course by David Silver
- Lecture slides for above course
- Spinning up by OpenAI
- More exhaustive RL guide by Deeny Britz
- If time available I will add a simple program for elevator using RL.
- Better graphs