V2X-Sim: Multi-Agent Collaborative Perception Dataset and Benchmark for Autonomous Driving [RA-L 2022]
Yiming Li, Dekun Ma, Ziyan An, Zixun Wang, Yiqi Zhong, Siheng Chen, Chen Feng
"A comprehensive multi-agent multi-modal multi-task 3D perception dataset for autonomous driving."

[2022-07] Our paper is available at arxiv.
[2022-06] 🔥 V2X-Sim is accepted at IEEE Robotics and Automation Letters (RA-L).
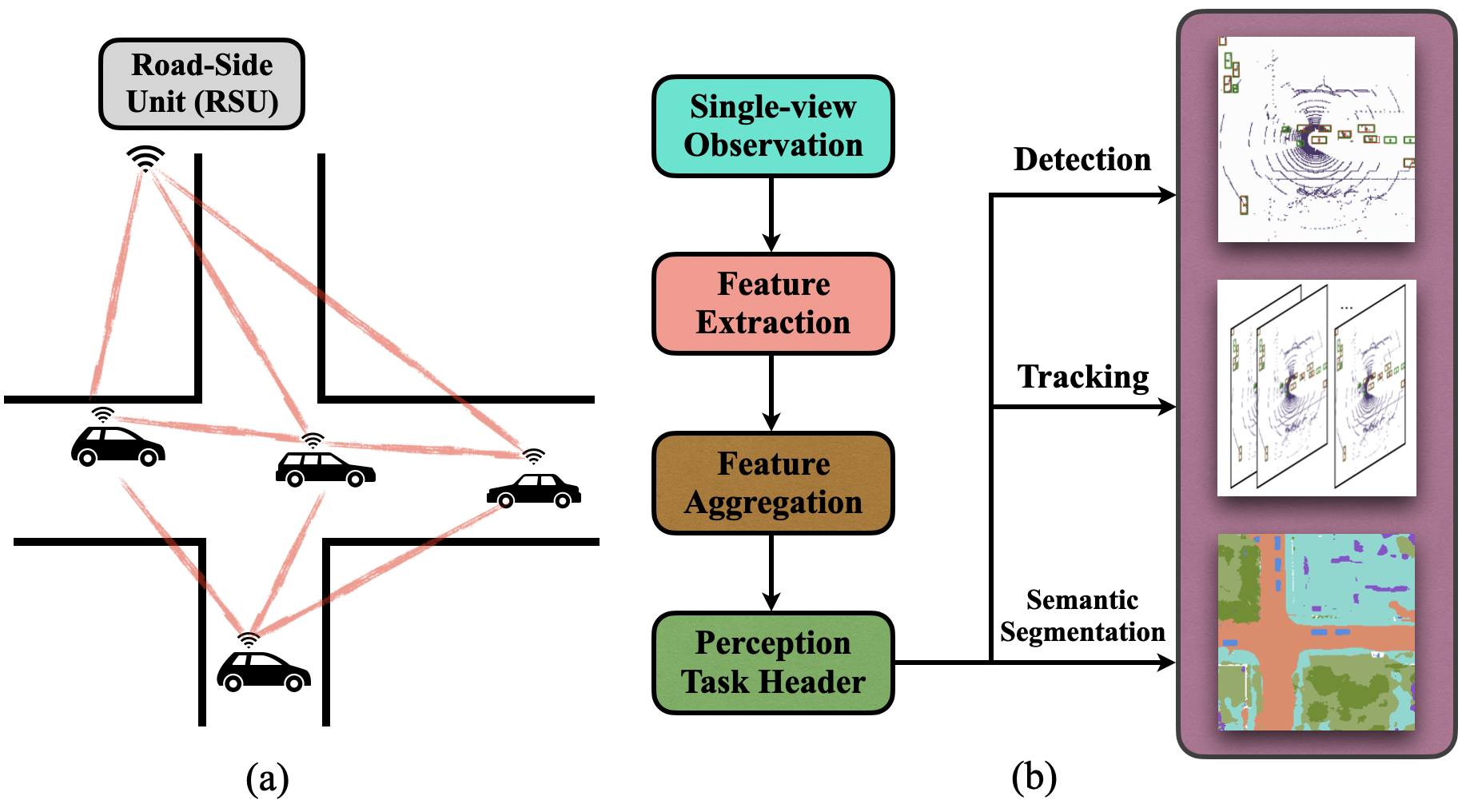
Vehicle-to-everything (V2X) communication techniques enable the collaboration between a vehicle and any other entity in its surrounding, which could fundamentally improve the perception system for autonomous driving. However, the lack of a public dataset significantly restricts the research progress of collaborative perception. To fill this gap, we present V2X-Sim, a comprehensive simulated multi-agent perception dataset for V2X-aided autonomous driving. V2X-Sim provides: (1) multi-agent sensor recordings from the road-side unit (RSU) and multiple vehicles that enable collaborative perception, (2) multi-modality sensor streams that facilitate multi-modality perception, and (3) diverse ground truths that support various perception tasks. Meanwhile, we build an open-source testbed and provide a benchmark for the state-of-the-art collaborative perception algorithms on three tasks, including detection, tracking and segmentation. V2X-Sim seeks to stimulate collaborative perception research for autonomous driving before realistic datasets become widely available.
Download links:
- Original dataset (you are going to parse this dataset yourself with
create_data.pyscripts for specific tasks): Google Drive (US) - preprocessed datasets for detection and segmentation tasks and model checkpoints: Google Drive (US)
You could find more detailed documents on our website!
V2X-Sim follows the same file structure as the Nuscenes dataset:
V2X-Sim
├── maps # images for the map of one of the towns
├── sweeps # sensor data
| ├── LIDAR_TOP_id_0 # top lidar data for the top camera, agent 0 (RSU)
| ├── LIDAR_TOP_id_1 # top lidar data for the top camera, agent 1
| ├── LIDAR_TOP_id_2 # top lidar data for the top camera, agent 2
| ...
├── v1.0-mini # metadata
| ├── scene.json # metadata for all the scenes
| ├── sample.json # metadata for each sample, organized like linked-list
| ├── sample_annotation.json # sample annotation metadata for each scene
| ...
For parsed detection and segmentation dataset, the file structure will be:
V2X-Sim-det / V2X-Sim-seg
├── train # training data
| ├── agent0 # data for RSU
| | ├── 0_0 # scene 0, frame 0
| | ├── 0_1 # scene 0, frame 1
| | | ...
| ├── agent1 # data for agent 1
| ...
| ├── agent5 # data for agent 5
├── val # validation data
├── test # test data
scene_50.mp4
scene_64.mp4
scene_72.mp4
Tested with:
- Python 3.7
- PyTorch 1.8.0
- Torchvision 0.9.0
- CUDA 11.2
We implement when2com, who2com, V2VNet, lowerbound and upperbound benchmark experiments on our datasets. You are welcome to go to README files in detection, segmentation and tracking to find them.
We are very grateful to multiple great opensourced codebases, without which this project would not have been possible:
If you find V2XSIM useful in your research, please cite:
@article{li2022v2x,
title={V2X-Sim: Multi-Agent Collaborative Perception Dataset and Benchmark for Autonomous Driving},
author={Li, Yiming and Ma, Dekun and An, Ziyan and Wang, Zixun and Zhong, Yiqi and Chen, Siheng and Feng, Chen},
journal={IEEE Robotics and Automation Letters},
volume={7},
number={4},
pages={10914--10921},
year={2022},
publisher={IEEE}
}