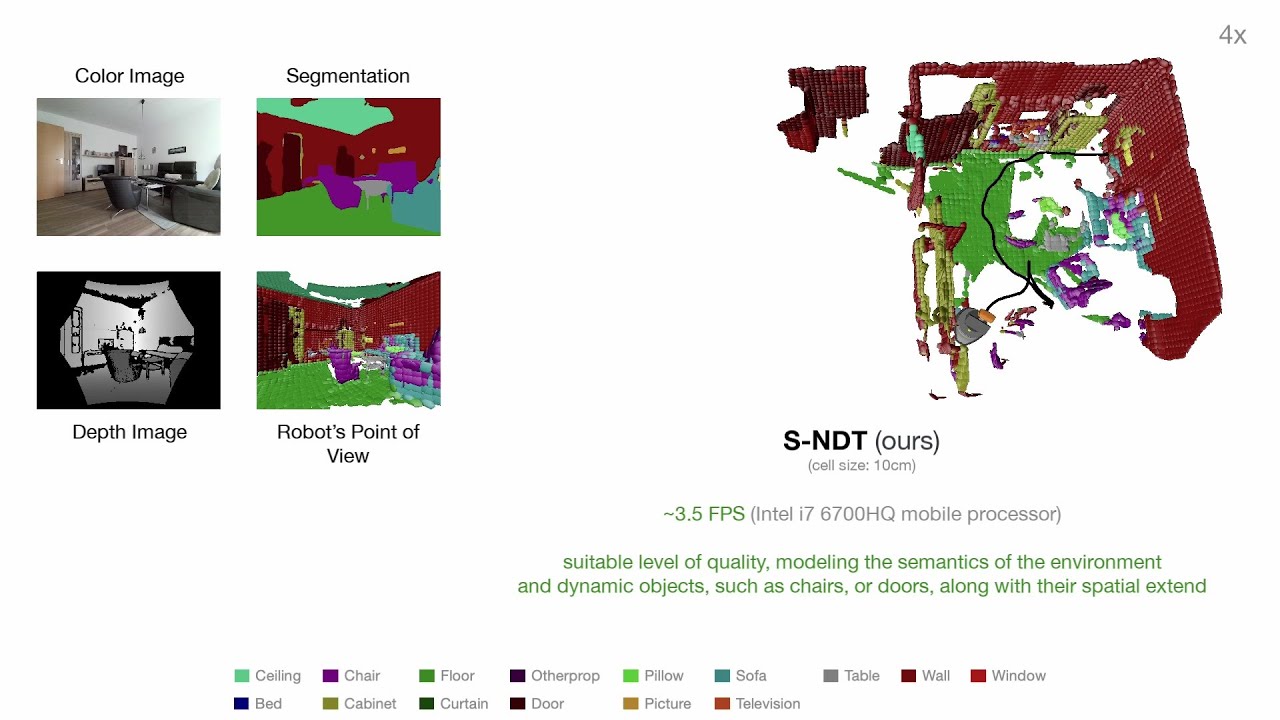
This repository contains the code to our paper "Efficient and Robust Semantic Mapping for Indoor Environments" (IEEE Xplore, arXiv).
(Click on the image to open YouTube video)
You may also want to have a look at our follow-up work: PanopticNDT
The source code and the network weights are published under BSD 3-Clause license, see license file for details.
If you use the source code or the network weights, please cite the following paper:
Seichter, D., Langer, P., Wengefeld, T., Lewandowski, B., Höchemer, D., Gross, H.-M. Efficient and Robust Semantic Mapping for Indoor Environments in IEEE International Conference on Robotics and Automation (ICRA), pp. 9221-9227, 2022.
BibTeX
@inproceedings{semanticndtmapping2022icra,
title = {{Efficient and Robust Semantic Mapping for Indoor Environments}},
author = {Seichter, Daniel and Langer, Patrick and Wengefeld, Tim and Lewandowski, Benjamin and H{\"o}chemer, Dominik and Gross, Horst-Michael},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2022},
volume = {},
number = {},
pages = {9221-9227}
}
@article{semanticndtmapping2022arXiv,
title = {{Efficient and Robust Semantic Mapping for Indoor Environments}},
author = {Seichter, Daniel and Langer, Patrick and Wengefeld, Tim and Lewandowski, Benjamin and H{\"o}chemer, Dominik and Gross, Horst-Michael},
journal = {arXiv preprint arXiv:2203.05836},
year = {2022}
}Note that the preprint was accepted to be published in IEEE International Conference on Robotics and Automation (ICRA).
-
Clone repository:
# do not forget the '--recursive' ;) git clone --recursive https://github.com/TUI-NICR/semantic-mapping.git cd /path/to/this/repository
-
Set up anaconda environment including all dependencies:
# option 1: create conda environment from YAML file conda env create -f semantic_mapping.yaml conda activate semantic_mapping # option 2: create new environment (see last tested versions) conda create -n semantic_mapping python==3.8.12 anaconda==2021.11 conda activate semantic_mapping pip install onnx==1.11.0 pip install opencv-python==4.2.0.34 pip install tqdm==4.62.3 # ONNXRuntime with CUDA support conda install -c conda-forge cudnn==8.2.1.32 pip install onnxruntime-gpu==1.11.0 # finally, install our package for preparing and using the Hypersim dataset pip install ./lib/nicr-scene-analysis-datasets[with_preparation]
-
Prepare the Hypersim dataset:
# download and extract raw dataset (2x ~1.8TB) HYPERSIM_DOWNLOAD_PATH='./datasets/hypersim_preparation' wget https://raw.githubusercontent.com/apple/ml-hypersim/6cbaa80207f44a312654e288cf445016c84658a1/code/python/tools/dataset_download_images.py python dataset_download_images.py --downloads_dir $HYPERSIM_DOWNLOAD_PATH # prepare dataset (~157.5 GB, extract required data, convert to our format, blacklist some scenes/trajectories) python -m nicr_scene_analysis_datasets.datasets.hypersim.prepare_dataset \ ./datasets/hypersim \ $HYPERSIM_DOWNLOAD_PATH \ --additional-subsamples 2 5 10 20 \ --multiprocessing # just in case you want to delete the downloaded raw data (2x ~1.8TB) rm -rf $HYPERSIM_DOWNLOAD_PATH
For further details, we refer to the documentation of our nicr-scene-analysis-datasets python package.
-
Download pretrained model:
We provide the weights of our selected ESANet-R34-NBt1D (enhanced ResNet34-based encoder utilizing the Non-Bottleneck-1D block) trained on the Hypersim dataset. To ease both application and deployment, we removed all dependencies (PyTorch, ...) and provide the weights in ONNX format.Click here to download the model and extract it to
./trained_modelsor use:pip install gdown # last tested: 4.4.0 gdown 1zUxSqq4zdC3yQ4RxiHvTh8CX7-115KUg --output ./trained_models/ tar -xvzf ./trained_models/model_hypersim.tar.gz -C ./trained_models/The model was selected based on the mean intersection over union (mIoU) on the validation split: 0.4591184410660463 at epoch 498. On the test split, the model achieves a mIoU of 0.41168890871760977. Note, similar to other approaches, we only evaluate up to a reasonable maximum distance of 20m from the camera. For more detail, see
evaluate.py. -
Extract predicted semantic segmentation:
# use default paths (~74.3GB for topk with k=3) python predict.py \ --onnx-filepath ./trained_models/model_hypersim.onnx \ --dataset-path ./datasets/hypersim \ --dataset-split test \ --topk 3 \ --output-path ./datasets/hypersim_predictions # for more details, see: python predict.py --help
For the example above, the predicted segmentations are stored at
./datasets/hypersim_predictions/test/. See thesemantic_40_topksubfolder for the predicted topK segmentation outputs andsemantic_40/orsemantic_40_colored/for the predicted (colored) top1 labels. -
Run your semantic mapping experiments and store the results with the following folder structure:
path/to/results/ └── test ├── results1 │ ├── ai_001_010 │ │ ├── cam_00 │ │ │ ├── 0000.png │ │ │ ├── ... ├── results2 │ ├── ai_001_010 │ │ ├── cam_00 │ │ │ ├── 0000.png │ │ │ ├── ...You may have a look at
./lib/nicr-scene-analysis-datasets/nicr_scene_analysis_datasets/mira/_hypersim_reader.pyfor a starting point. This class shows, how the Hypersim dataset is processed in our pipelines. -
Run evaluation:
# use default paths python evaluate.py \ --dataset-path ./datasets/hypersim \ --dataset-split test \ --predictions-path ./datasets/hypersim_predictions [--result-paths path/to/results/test/results1 path/to/results/test/results2] # for more details, see: python evaluate.py --help
For the predicted segmentation of our ONNX model, you should obtain measures similar to:
miou_gt_masked: 0.41168890871760977 mean_pacc_gt_masked: 0.5683601556433829 invalid_ratio: 0.0 invalid_mean_ratio_gt_masked: 0.0 vwmiou_gt_masked: 0.41168890871760977 vwmean_pacc_gt_masked: 0.5683601556433829Check the created
results.jsonat the predictions folder for more measures (e.g../datasets/hypersim_predictions/test/semantic_40/results.json)