



The A* (A-star) algorithm is a popular pathfinding algorithm commonly used in robotics, games, and other applications where finding the shortest path between two points is necessary. A* is an extension of Dijkstra's algorithm with the added benefit of heuristic evaluation, making it more efficient for pathfinding in many cases. The effectiveness of A* heavily relies on the quality of this heuristic function - A good heuristic should be admissible (never overestimate the cost) to guarantee the optimality of the solution.
Common heuristics include Manhattan distance, Euclidean distance, and Chebyshev distance, which can be interchanged depending on the nature of the environment.
Also known as the L1 norm or taxicab distance, Manhattan distance is the sum of the absolute differences of the Cartesian coordinates. It measures the distance between two points along the grid lines.
For two points, x and y, the distance is given by:
\text{Manhattan Distance} = |x_1 - x_2| + |y_1 - y_2|It's ideal for grid-based environments where movement is restricted to horizontal, vertical, and diagonal directions with equal cost.
Also known as the L2 norm, Euclidean distance is the straight-line distance between two points in Euclidean space. It represents the length of the shortest path between the points.
For two points, x and y, the distance is given by:
\text{Euclidean Distance} = \sqrt{{(x_1 - x_2)^2 + (y_1 - y_2)^2}}Suitable for continuous environments where diagonal movement is allowed and the cost of diagonal movement is considered equal to the cost of horizontal or vertical movement.
Definition: Also known as the L∞ norm or chessboard distance, Chebyshev distance is the maximum of the absolute differences along each coordinate axis.
For two points, x and y, the distance is given by:
\text{Chebyshev Distance} = \max(|x_1 - x_2|, |y_1 - y_2|)Particularly useful in grid-based environments where diagonal movement is allowed, and the cost of diagonal movement is the same as the cost of horizontal or vertical movement.
Manhattan distance is faster to compute because it involves only absolute differences and additions. Euclidean distance provides a more accurate measure when diagonal movement is allowed, as it calculates the true straight-line distance.
Euclidean distance considers the actual geometric distance, while Chebyshev distance only considers the maximum coordinate difference. Chebyshev distance is less computationally intensive than Euclidean distance.
In grid-based environments with only horizontal, vertical, and diagonal movement, Manhattan and Chebyshev distances are often equivalent. Chebyshev distance is more general and can be applied in scenarios where diagonal movement is allowed.
The choice of heuristic depends on the characteristics of the environment and the allowed types of movement. If diagonal movement is restricted or has a different cost, Manhattan distance is often a good choice. For scenarios with diagonal movement and equal cost, Euclidean or Chebyshev distance can be considered based on computational efficiency. In summary, the selection of the appropriate distance measure depends on the specific characteristics of the environment and the movement constraints. Each distance metric has its strengths and is suitable for different scenarios within the context of pathfinding algorithms like A*.
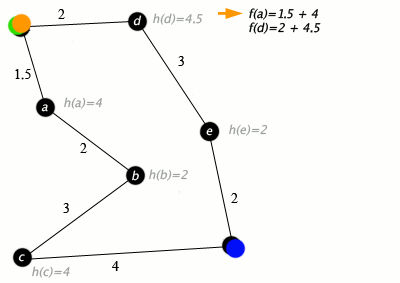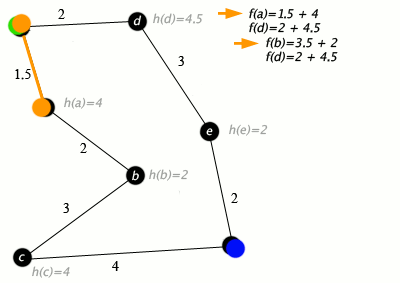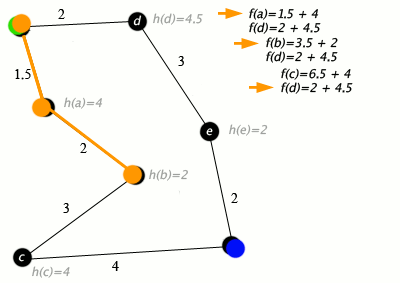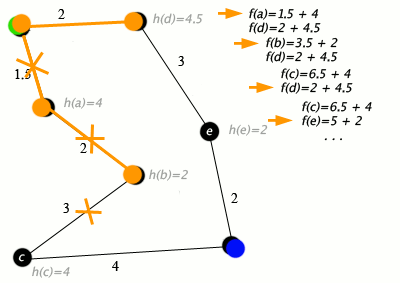
The objective of the pathfidner is to quite literally find the shortest path from a starting point to a goal point in a graph (or grid). A* uses a priority queue to efficiently select the node with the lowest total cost from the start to the current node, considering both the cost to reach the current node (g value) and the estimated cost to reach the goal from the current node (h value).
The graph is made up of nodes representing positions in the environment. Each node has coordinates, and in a grid-based scenario, nodes correspond to grid cells.
Define the connections between nodes. In a grid, nodes are typically connected to their adjacent neighbors.
- g (Cost from Start): The cost to reach a node from the start node.
- h (Heuristic Cost to Goal): An estimate of the cost from the current node to the goal. It is the heuristic function's role to provide this estimate.
- f (Total Cost): The sum of g and h. This is the value used to prioritize nodes in the priority queue.
- Priority Queue: Nodes are stored in a priority queue sorted by their f values. This ensures that nodes with lower total costs are explored first.
A* uses a heuristic function to estimate the cost from the current node to the goal. This function should be admissible (never overestimates) to guarantee the optimality of the solution.
Create the start node and add it to the open list (priority queue). Initialize g and h values of the start node. Set g to 0 for the start node.
While the open list is not empty: Pop the node with the lowest f value from the open list. If the current node is the goal, the path is found.
For each neighboring node (successor) of the current node: Calculate g and h values for the successor. If the successor is not in the open list, calculate f and add it to the open list. If the successor is in the open list and the new g value is lower, update g and f.
If the open list is empty, and the goal is not reached, there is no path.
- A* is complete and optimal when using an admissible heuristic.
- The algorithm may not perform optimally in certain scenarios, such as environments with very high-dimensional state spaces.
- Choosing an appropriate heuristic is crucial for the efficiency of the algorithm.
- A* is widely used and has many variations and optimizations, such as weighted A* and incremental search.
In summary, A* combines the benefits of both uniform cost search and greedy best-first search by using a heuristic function to efficiently explore the search space and find the shortest path. Its flexibility and effectiveness make it a popular choice for pathfinding applications.