Created by Hang Zhang
-
Please checkout our PyTorch implementation (recommended, memory efficient).
-
This repo is a Torch implementation of Encoding Layer as described in the paper:
Deep TEN: Texture Encoding Network [arXiv]
Hang Zhang, Jia Xue, Kristin Dana
@article{zhang2016deep,
title={Deep TEN: Texture Encoding Network},
author={Zhang, Hang and Xue, Jia and Dana, Kristin},
journal={arXiv preprint arXiv:1612.02844},
year={2016}
}
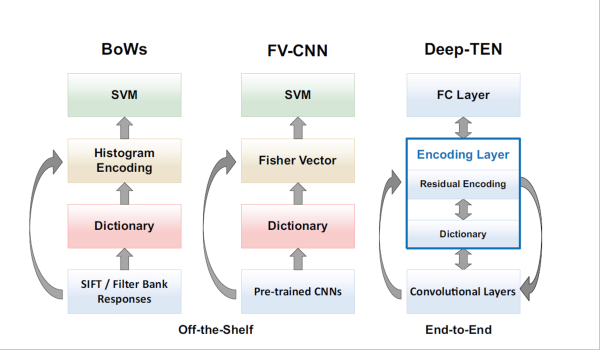
Traditional methods such as bag-of-words BoW (left) have a structural similarity to more recent FV-CNN methods (center). Each component is optimized in separate steps. In our approach (right) the entire pipeline is learned in an integrated manner, tuning each component for the task at hand (end-to-end texture/material/pattern recognition).
On Linux
luarocks install https://raw.githubusercontent.com/zhanghang1989/Deep-Encoding/master/deep-encoding-scm-1.rockspecOn OSX
CC=clang CXX=clang++ luarocks install https://raw.githubusercontent.com/zhanghang1989/Deep-Encoding/master/deep-encoding-scm-1.rockspec-
The Joint Encoding experiment in Sec4.2 will execute by default (tested using 1 Titan X GPU). This achieves 12.89% percentage error on STL-10 dataset, which is 49.8% relative improvement comparing to pervious state-of-the art 25.67% of Zhao et. al. 2015.:
git clone https://github.com/zhanghang1989/Deep-Encoding cd Deep-Encoding/experiments th main.lua -
Training Deep-TEN on MINC-2500 in Sec4.1 using 4 GPUs.
- Please download the pre-trained
ResNet-50 Torch model
and the MINC-2500 dataset to
mincfolder before executing the program (tested using 4 Titan X GPUs).
th main.lua -retrain resnet-50.t7 -ft true \ -netType encoding -nCodes 32 -dataset minc \ -data minc/ -nClasses 23 -batchSize 64 \ -nGPU 4 -multisize true
- To get comparable results using 2 GPUs, you should change the batch size and the corresponding learning rate:
th main.lua -retrain resnet-50.t7 -ft true \ -netType encoding -nCodes 32 -dataset minc \ -data minc/ -nClasses 23 -batchSize 32 \ -nGPU 2 -multisize true -LR 0.05\
- Please download the pre-trained
ResNet-50 Torch model
and the MINC-2500 dataset to
| Dataset | MINC-2500 | FMD | GTOS | KTH | 4D-Light |
|---|---|---|---|---|---|
| FV-SIFT | 46.0 | 47.0 | 65.5 | 66.3 | 58.4 |
| FV-CNN(VD) | 61.8 | 75.0 | 77.1 | 71.0 | 70.4 |
| FV-CNN(VD) multi | 63.1 | 74.0 | 79.2 | 77.8 | 76.5 |
| FV-CNN(ResNet)multi | 69.3 | 78.2 | 77.1 | 78.3 | 77.6 |
| Deep-TEN*(ours) | 81.3 | 80.2±0.9 | 84.5±2.9 | 84.5±3.5 | 81.7±1.0 |
| State-of-the-Art | 76.0±0.2 | 82.4±1.4 | 81.4 | 81.1±1.5 | 77.0±1.1 |
We thank Wenhan Zhang from Physics department, Rutgers University for discussions of mathematic models. This work was supported by National Science Foundation award IIS-1421134. A GPU used for this research was donated by the NVIDIA Corporation.