English | 简体中文
2023/08 aarch64 add cmake and mperf, try -DMPERF_ENABLE=ON !
row-major matmul optimization tutorial
| backend | armv7 | aarch64 | aarch64-int8 | cuda | cuda-int4 | vulkan | x86 |
|---|---|---|---|---|---|---|---|
| support | ✔️ | ✔️ | ✔️ | ✔️ | - | ✔️ | ✅ |
All backends and corresponding tutorials
| backend | tutorial |
|---|---|
| aarch64 | GEMM 入门 |
| aarch64 | GEMM caching |
| aarch64-int8 | - |
| armv7 | ARMv7 4x4kernel 懒人优化小实践 |
| cuda | cuda 入门的正确姿势:how-to-optimize-gemm |
| cuda-int4 WIP | int4 炼丹要术 |
| vulkan | 如何火急火燎地上手 Vulkan |
Usage is similar for all backends:
- Open the backend directory to be used, and change the
OLDandNEWofmakefileto the same implementation for the first run, for example
$ cd aarch64
$ cat makefile
OLD := MMult_4x4_10
NEW := MMult_4x4_10
..- makefile
will compile and run the implementation whichNEWpoint at, and copyoutput_MMult_4x4_10.mtooutput_new.m`
$ make run
$ cat output_new.m- It may not be intuitive to look at the numbers directly, so draw a line chart
$ python3 -m pip install -r ../requirements.txt
$ python3 plot.pySpecific to each hardware, there are subtle differences:
NEWmay choose a different name- vulkan/int4 needs prerequisitions
A. Prepare armv7/aarch64 linux development environment, Raspberry Pi/rk3399/aws arm server are all fine.
B. By default ARCH := native, build and run directly
$ cd armv8 && make run
chgemm is an int8 gemm library.
- blue line is chgemm implementation
- orange line is aarch64 fp32 peak
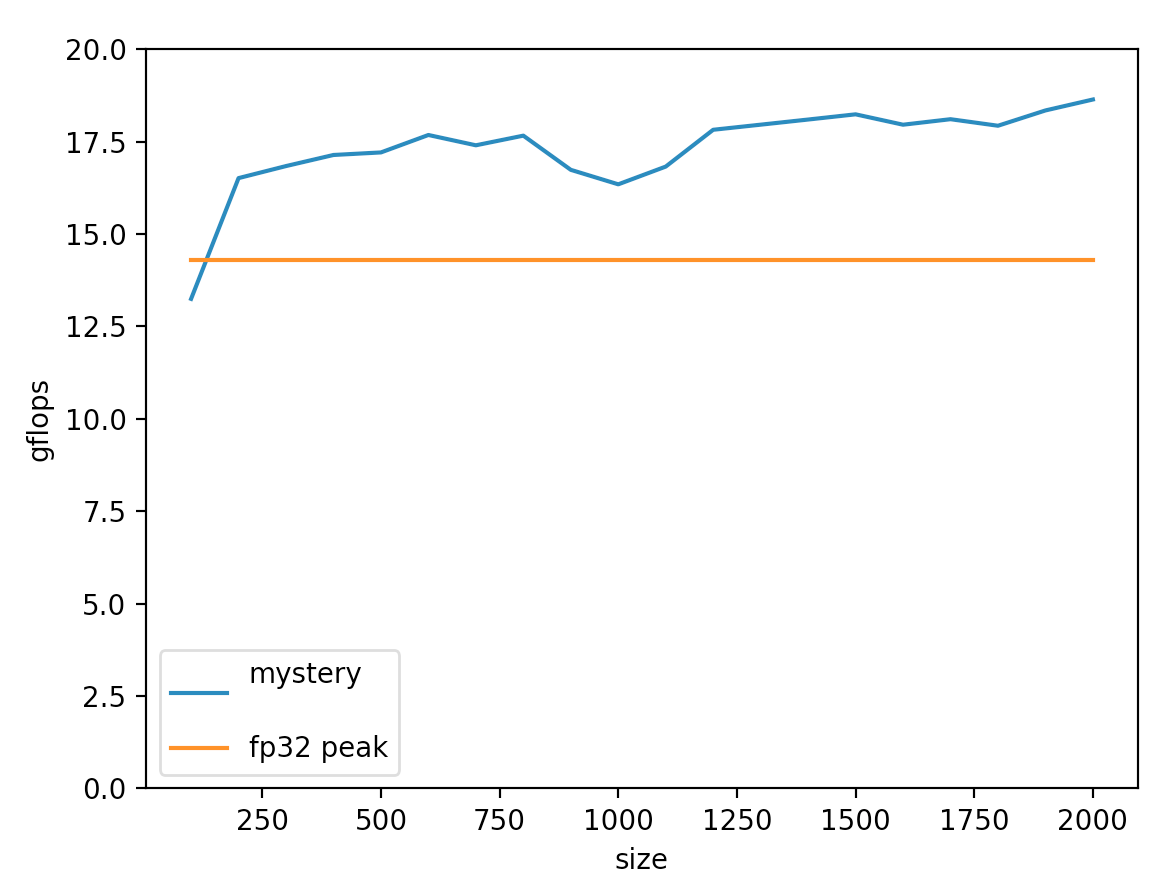

Compared to the code in this tutorial, the differences are:
- Dealing with the boundary problem, unlike the tutorial where only multiples of 4 are considered;
- Int8 reaches a maximum of 18.6 gflops (relative to the theoretical limit of fp32 is only 14.3 on RK3399, gemmlowp is about 12-14gflops);
- Based on symmetric quantization, input value range must be in [-127, +127], and -128 cannot appear;
- Built-in small example about how to integrate into android studio
chgemm has been merged into ncnn INT8 convolution implementation.
flame referenced by x86 is the original implementation, with some differences from this repo:
- The original is column-major
x86 SSEversion - Both are tutorials, and the
MMult_4x4_17.cwritten now can reach 70% of the armv8.1 CPU peak - The boundary problem is not dealt with now, only the case where MNK is a multiple of 4 is considered;
sub_kernelalso only writes the simplest kind of assembly. Practical needs a simple adjustment; - In terms of drawing,
octavewas discarded (it is too troublesome to configure the environment once for embedded devices), andpythonwas used instead.
This version is faster than NVIDIA cuBLAS
- green line is MMult_cuda_12 without tensorcore
- blue line is cuBLAS without tensorcore

- Need to install cuda driver and nvcc by yourself
- CPU OpenBLAS is required to be the baseline
$ apt install libopenblas-dev-
vulkan build depends on kompute API packaging, see vulkan build documentation for details
-
More about how to learn compute shader
WIP
-
megpeak: For measuring hardware limit performance, support arm/x86/OCL..
-
perf: Available in linux system tools, for system-level performance analysis and disassembly
-
YHs_Sample: dalao 's implementation
-
mperf: optimization tools