ECCV, 2024
Shaowei Liu
·
Zhongzheng Ren
·
Saurabh Gupta*
·
Shenlong Wang*
·

This repository contains the pytorch implementation for the paper PhysGen: Rigid-Body Physics-Grounded Image-to-Video Generation, ECCV 2024. In this paper, we present a novel training-free image-to-video generation pipeline integrates physical simulation and generative video diffusion prior.

- Clone this repository:
git clone --recurse-submodules https://github.com/stevenlsw/physgen.git cd physgen - Install requirements by the following commands:
conda create -n physgen python=3.9 conda activate physgen pip install -r requirements.txt
Run our Colab notebook for quick start!
-
Run image space dynamics simulation in just 3 seconds without GPU and any displace device and additional setup required!
export PYTHONPATH=$(pwd) name="pool" python simulation/animate.py --data_root data --save_root outputs --config data/${name}/sim.yaml
-
The output video should be saved in
outputs/${name}/composite.mp4. Try setnameto bedomino,balls,pig_ballandcarfor other scenes exploration. The example outputs are shown below:Input Image Simulation Output Video 



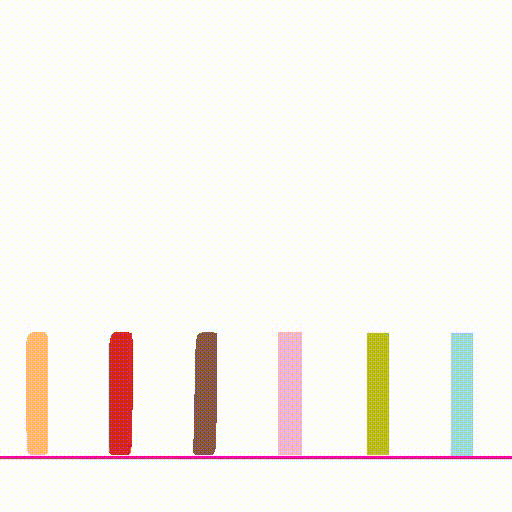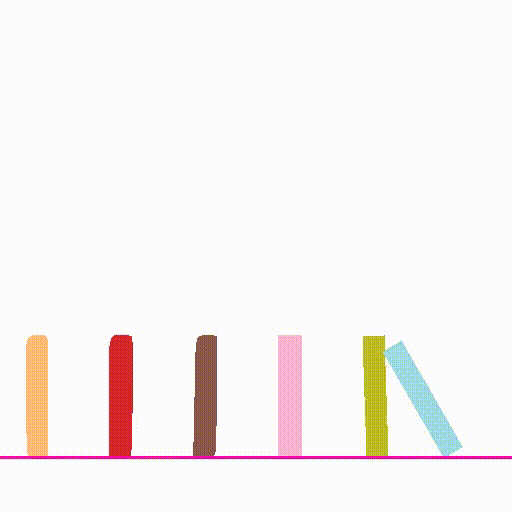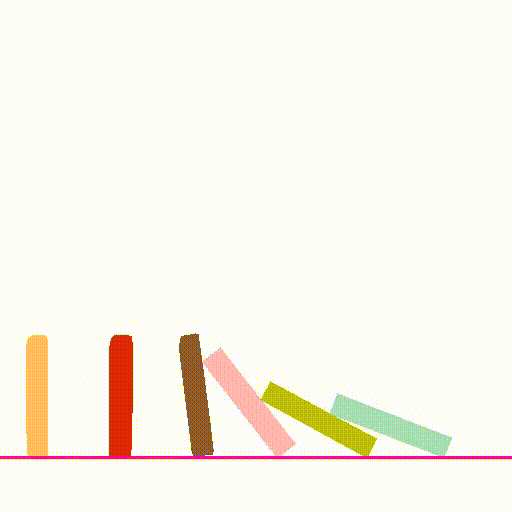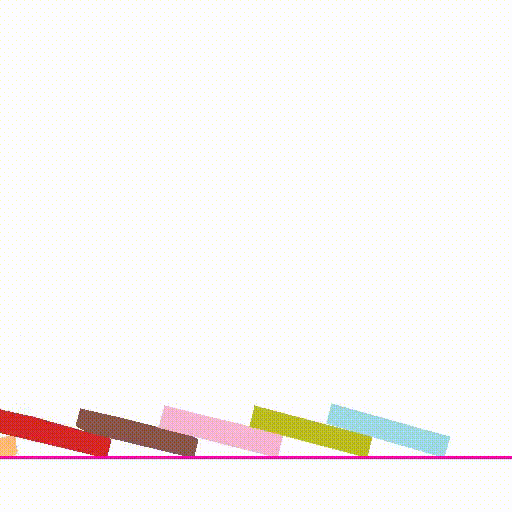







- Please see perception/README.md for details.
| Input | Segmentation | Normal | Albedo | Shading | Inpainting |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
-
Simulation requires the following input for each image:
image folder/ ├── original.png ├── mask.png # segmentation mask ├── inpaint.png # background inpainting ├── sim.yaml # simulation configuration file
-
sim.yamlspecify the physical properties of each object and initial conditions (force and speed on each object). Please seedata/pig_ball/sim.yamlfor an example. Setdisplaytotrueto visualize the simulation process with display device, setsave_snapshottotrueto save the simulation snapshots. -
Run the simulation by the following command:
cd simulation python animate.py --data_root ../data --save_root ../outputs --config ../data/${name}/sim.yaml
-
The outputs are saved in
outputs/${name}as follows:output folder/ ├── history.pkl # simulation history ├── composite.mp4 # composite video |── composite.pt # composite video tensor ├── mask_video.pt # foreground masked video tensor ├── trans_list.pt # objects transformation list tensor
- Relighting requires the following input:
image folder/ # ├── normal.npy # normal map ├── shading.npy # shading map by intrinsic decomposition previous output folder/ ├── composite.pt # composite video ├── mask_video.pt # foreground masked video tensor ├── trans_list.pt # objects transformation list tensor
- The
perception_inputis the image folder contains the perception result. Theprevious_outputis the output folder from the previous simulation step. - Run the relighting by the following command:
cd relight python relight.py --perception_input ../data/${name} --previous_output ../outputs/${name}
- The output
relight.mp4andrelight.ptis the relighted video and tensor. - Compare between composite video and relighted video:
Input Image Composite Video Relight Video 




-
Download the SEINE model follow instruction
# install git-lfs beforehand mkdir -p diffusion/SEINE/pretrained git clone https://huggingface.co/CompVis/stable-diffusion-v1-4 diffusion/SEINE/pretrained/stable-diffusion-v1-4 wget -P diffusion/SEINE/pretrained https://huggingface.co/Vchitect/SEINE/resolve/main/seine.pt -
The video diffusion rendering requires the following input:
image folder/ # ├── original.png # input image ├── sim.yaml # simulation configuration file (optional) previous output folder/ ├── relight.pt # composite video ├── mask_video.pt # foreground masked video tensor
-
Run the video diffusion rendering by the following command:
cd diffusion python video_diffusion.py --perception_input ../data/${name} --previous_output ../outputs/${name}
denoise_strengthandpromptcould be adjusted in the above script.denoise_strengthcontrols the amount of noise added, 0 means no denoising, 1 means denoise from scratch with lots of variance to the input image.promptis the input prompt for video diffusion model, we use default foreground object names from perception model as prompt. -
The output
final_video.mp4is the rendered video. -
Compare between relight video and diffuson rendered video:
Input Image Relight Video Final Video 





We integrate the simulation, relighting and video diffusion rendering in one script. Please follow the Video Diffusion Rendering to download the SEINE model first.
bash scripts/run_demo.sh ${name}If you find our work useful in your research, please cite:
@inproceedings{liu2024physgen,
title={PhysGen: Rigid-Body Physics-Grounded Image-to-Video Generation},
author={Liu, Shaowei and Ren, Zhongzheng and Gupta, Saurabh and Wang, Shenlong},
booktitle={European Conference on Computer Vision ECCV},
year={2024}
}- Grounded-Segment-Anything for segmentation in perception
- GeoWizard for depth and normal estimation in perception
- Intrinsic for intrinsic image decomposition in perception
- Inpaint-Anything for image inpainting in perception
- Pymunk for physics simulation in simulation
- SEINE for video diffusion in rendering