A PyTorch implementation of Transformers from scratch for Machine Translation on PHP Corpus dataset[1] (Czech->English) based on "Attention Is All You Need" by Ashish Vaswani et. al.[2]. The motive to create this repository is not to implement a state-of-the-art model for Machine Translation, but to get a hands-on experience in implementing the Transformer architecture from scratch.
Modification done over the baseline[2] :
- Increased the model depth and improved the validation loss as well as BLEU score with a small margin.
- Performed ablation study to check the effects of Label Smoothening, vector dimensioanlity, rescaling of word embedding, and varying the size of hidden layer in feed-forward network

- Download the data using scripts/download_data.sh.
Note: ExtractPHP.cs-en.csandPHP.cs-en.enfiles from the downloaded zip file and move them insidedata/
sh scripts/download_data.sh
- Install the requried libraries :
sh scripts/requirements.sh
- Train the model :
python3 train.py [-h] [--src_data SRC_DATA] [--tgt_data TGT_DATA]
[--batch_size N] [--d_model D_MODEL] [--n_layers N_LAYERS]
[--n_heads N_HEADS] [--ffn_hidden FFN_HIDDEN]
[--dropout DROPOUT] [--max_sent_len MAX_SENT_LEN]
[--init_lr INIT_LR] [--scheduler_factor SCHEDULER_FACTOR]
[--optim_adam_eps OPTIM_ADAM_EPS]
[--optim_patience OPTIM_PATIENCE]
[--optim_warmup OPTIM_WARMUP]
[--optim_weight_decay OPTIM_WEIGHT_DECAY] [--epoch EPOCH]
[--clip CLIP] [--seed SEED]
[--label_smooth_eps LABEL_SMOOTH_EPS]
[--early_stop_patience EARLY_STOP_PATIENCE]
- Run below code to plot Train/Valid Loss vs Epoch and save in results/ (This step can be done anytime after executing step 1 to see the progress of the graph):
python3 plot.py
- Use the saved checkpoints (saved_ckpt/best_model.pt) to translate sentences from unseen data (test set) :
python3 translate.py
| Parameters | Description | Value used in modified version | Value (in the paper) |
|---|---|---|---|
--src_data |
Location of the source data | -path- | -path- |
--tgt_data |
Location of the target data | -path- | -path- |
--epoch |
Number of epochs to train | 150 | N/A |
--batch_size |
Batch size | 32 | N\A |
--d_model |
Size of word embedding | 256 | 512 |
--n_layers |
Number of enc/dec layers | 7 | 6 |
--n_heads |
Number of attention heads | 8 | 8 |
--ffn_hidden |
Number of hidden units in FFN | 1024 | 2048 |
--dropout |
Dropout probability | 0.15 | 0.1 |
--max_sent_len |
Maximum length of sentence for train/valid/test | 50 | N/A |
--init_lr |
Initial Learning Rate | 1e-4 | N/A |
--scheduler_factor |
Factor with which LR will decreasing using scheduler | 0.9 | 0.9 |
--optim_adam_eps |
Adam epsilon | 5e-9 | 1e-9 |
--optim_patience |
Number of epochs optimizer waits before decreasing LR | 8 | N/A |
--optim_warmup |
Optimizer warmup | 16000 | 4000 |
--optim_weight_decay |
Weight decay factor for optimizer | 5e-4 | N/A |
--clip |
Gradient clipping threshold to prevent exploding gradients | 1.0 | N/A |
--seed |
Seed for reproducibility | 1111 | N/A |
--label_smooth_eps |
Hyper-parameter for label smoothening | 0.1 | 0.1 |
--early_stop_patience |
Patience for Early Stopping | 20 | N/A |
Transformer Architecture (model/):
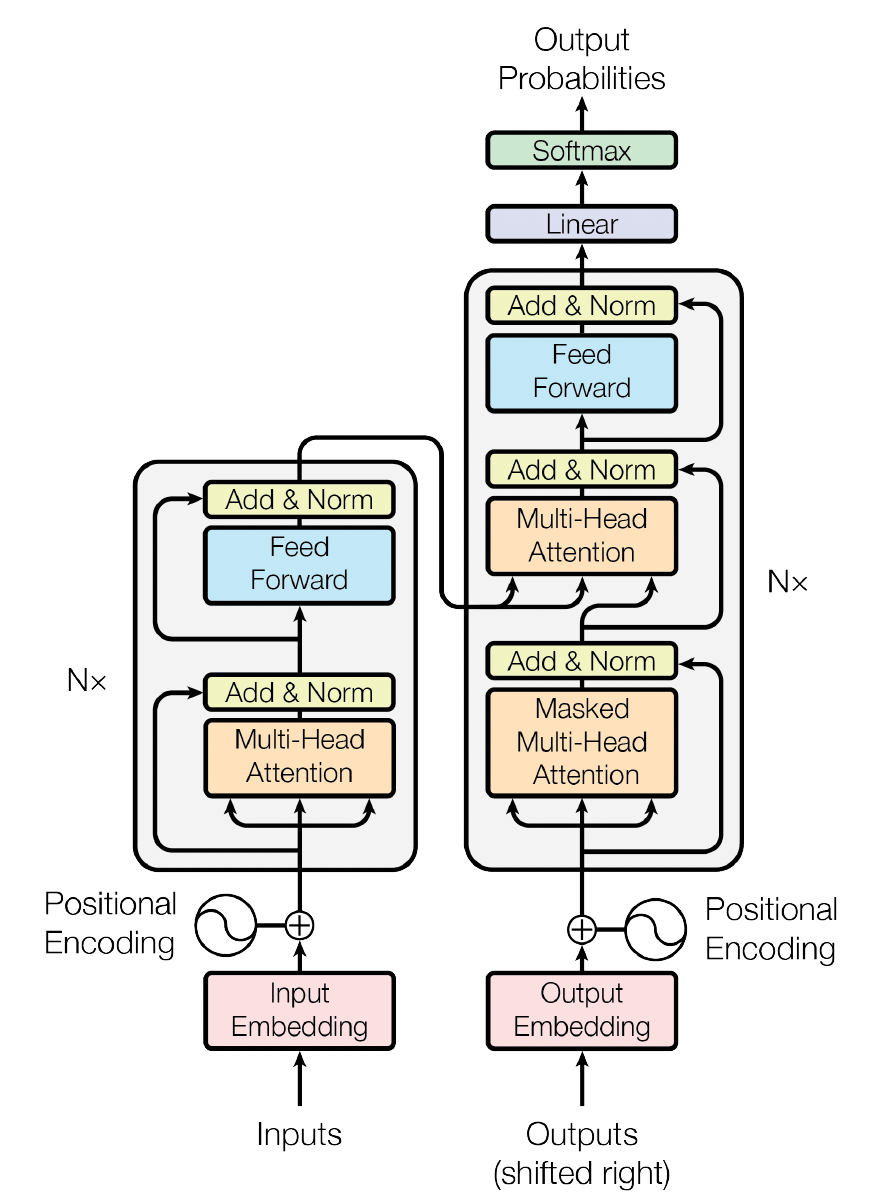
Multi Headed Attention Block in Encoder/Decoder (attention.py) :

Computing Attention using Key, Query and Value (attention.py) :


Positional Encoding using sin/cos (position_encoding.py):
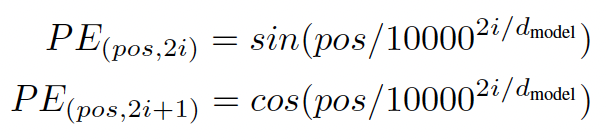
PHP Corpus Czech-English
| Total Sentences in Corpus | ~33,000 |
|---|---|
| Unique sentences with <50 words | 5464 |
| Train dataset | 4371 |
| Validation dataset | 874 |
| Test dataset | 219 |
- Source (Czech) language vocabulary size : 8891
- Target (English) language vocabulary size : 4564
As mentioned in the paper "Attention is All You Need" [2], I have used two types of regularization techniques which are active only during the train phase :
-
Residual Dropout (dropout=0.1) : Dropout has been added to embedding (positional+word) as well as to the output of each sublayer in Encoder and Decoder.
- Note : In order to deativate Dropout during
eval(), I have usednn.Dropout()instead ofnn.functional.dropout(Refer this link for more info) - I tried increasing the dropout parameter, however didn't see any considerable improvement.
- Note : In order to deativate Dropout during
-
Label Smoothening (eps=0.1) : One hot encoded labels encourages largest possible logits gaps to be fed to the softmax making the model less adaptive and too confident about its predictions leading to overfitting. However, label smoothening helps to avoid this by encouraging small logit gaps preventing overconfident predictions using smoothed labels.
-
Early Stopping (early_stop_patience=20) : To stop the training before the model starts to overfit. (This is just an additional technique used which has not been presented in the paper)
| Statistics | Value |
|---|---|
| Minimum validation loss | 3.95 |
| Validation set BLEU score | 23.2 |
| Time per epoch (seconds) | 45 |
| # of trainable parameters | 17,519,828 |

The model is able to exploit the use of attention mechanism to learn the context of the sentence well as it is able to pick the main words with high frequency from the source sentence and translate them correctly. However, it fails to perform well on low frequency words. Another observation is the that the dataset contains a lot of special characters in the sentences ("http: / /bugs.php.net /", "satellite_exception_id()") as it is based on a guide related to PHP computer scripting language. After these sentences are preprocessed and the special characters are removed before training the model, the data tends to loose its main context. This makes the training of the model more challenging.
Due to limited availibilty of GPU resources, I could only train the model for very less training data due to which the results are not satisfactory. However, I tried to get the learning curve and BLEU score as good as possible. Refer for information about how MT performs on low resources