Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar
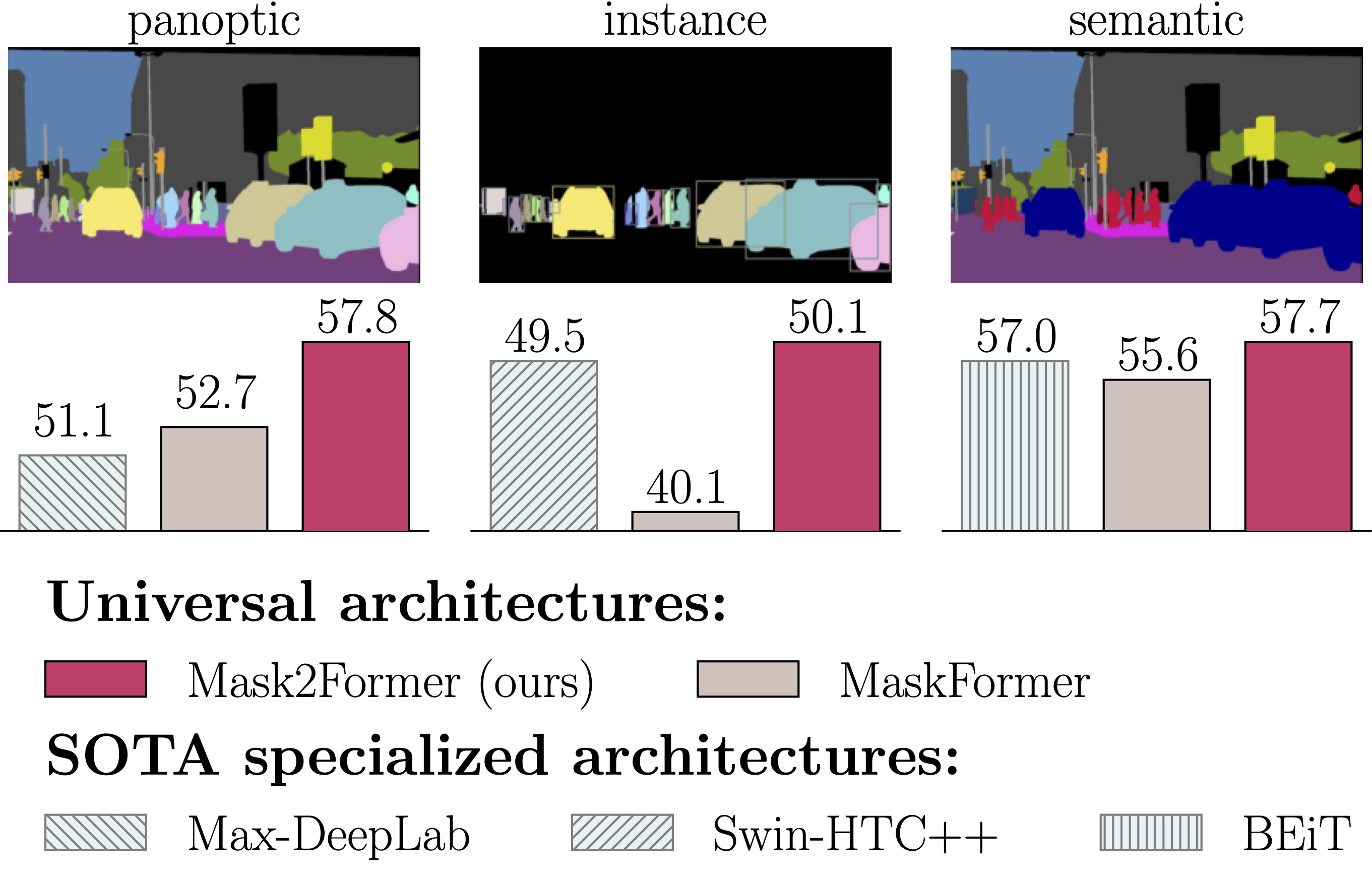
- A single architecture for panoptic, instance and semantic segmentation.
- Support major segmentation datasets: ADE20K, Cityscapes, COCO, Mapillary Vistas.
- Add Google Colab demo.
- Video instance segmentation is now supported! Please check our tech report for more details.
See installation instructions.
See Preparing Datasets for Mask2Former.
See Getting Started with Mask2Former.
Run our demo using Colab:
Integrated into Huggingface Spaces 🤗 using Gradio. Try out the Web Demo:
Replicate web demo and docker image is available here:
See Advanced Usage of Mask2Former.
We provide a large set of baseline results and trained models available for download in the Mask2Former Model Zoo.
Shield:
The majority of Mask2Former is licensed under a MIT License.
However portions of the project are available under separate license terms: Swin-Transformer-Semantic-Segmentation is licensed under the MIT license, Deformable-DETR is licensed under the Apache-2.0 License.
If you use Mask2Former in your research or wish to refer to the baseline results published in the Model Zoo, please use the following BibTeX entry.
@inproceedings{cheng2021mask2former,
title={Masked-attention Mask Transformer for Universal Image Segmentation},
author={Bowen Cheng and Ishan Misra and Alexander G. Schwing and Alexander Kirillov and Rohit Girdhar},
journal={CVPR},
year={2022}
}If you find the code useful, please also consider the following BibTeX entry.
@inproceedings{cheng2021maskformer,
title={Per-Pixel Classification is Not All You Need for Semantic Segmentation},
author={Bowen Cheng and Alexander G. Schwing and Alexander Kirillov},
journal={NeurIPS},
year={2021}
}Code is largely based on MaskFormer (https://github.com/facebookresearch/MaskFormer).