This API takes in the url of a webpage and css selector id of the content to be scrapped and returns the outer html text of the scrapped content. It is hosted in heroku and works using Puppeteer (to enable headless scraping) and ExpressJS (to serve the app).
| Reference | Detail |
|---|---|
| API Format | https://acciotables.herokuapp.com/?page_url=some_content&content_selector_id=some_content |
| Attributes | page_url : The URL of the webpage on which the content to be scrapped is available (in html encoded format) |
| content_selector_id : CSS Selector ID of a particular table or any html element (in html encoded format) | |
| Request Method | GET : GET methods means the API returns you something you ask |
| Response Type | text/html : Outer HTML content of the scrapped table (or any html element) |
Note: Since the API is deployed on Heroku, it might take a while to wake the web process if the webapp had been idle for last few minutes and needs to be moved from idle to running. Once it's up and running it will take a maximum of 4 seconds to produce the result.
- In order to scrap the following table from Football Reference's page, first we get the css selector id for the table.
- You can refer to my previous article on web scraping using RSelenium and Docker on using SelectorGadget to identify the css selector id for an html element.
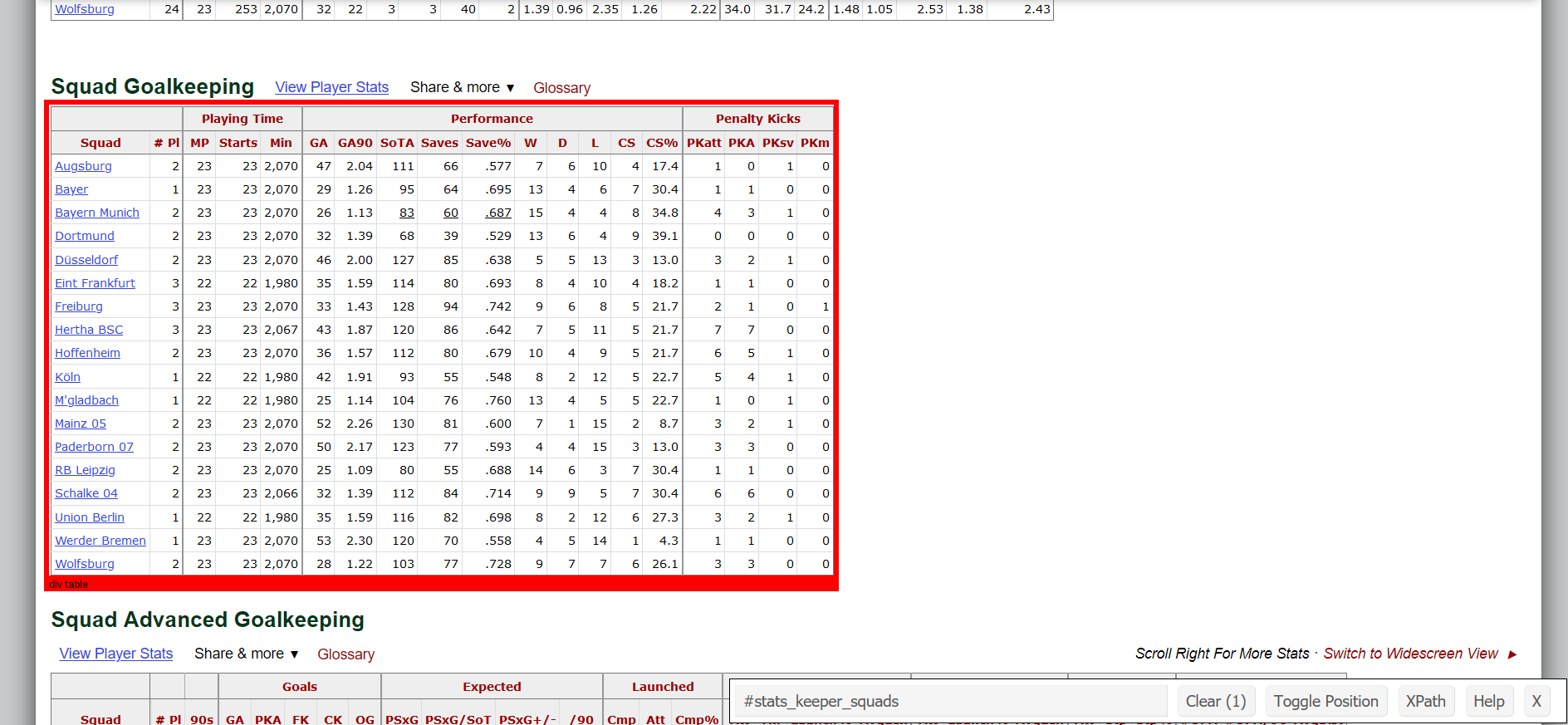
- From the above image we get to know that the css selector id for the "Squads Goalkeeping" table is #stats_keeper_squads.
- In order to scrap the table, all we need to do is call the API as
http://acciotables.herokuapp.com/?page_url=https://fbref.com/en/comps/22/Major-League-Soccer-Stats&content_selector_id=%23stats_keeper_squads. Note that # is replaced with its ASCII value %23 as URL's don't accept some symbols. Remember to swap # with %23 or refer to this page for more details for encoding other symbols. - The result is as follows: (we get the table in html format)
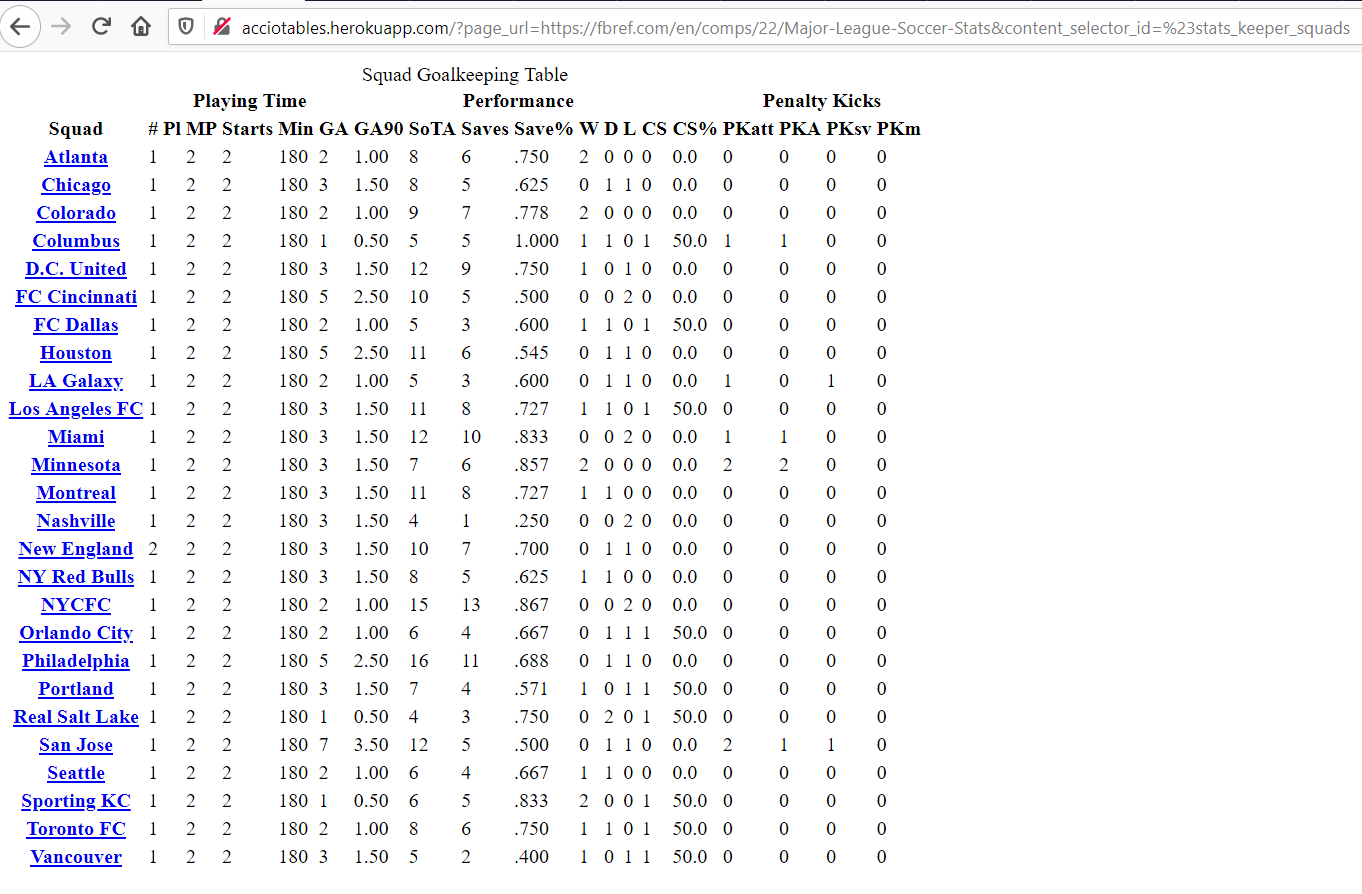
require(rvest)
require(dplyr)
page <- read_html("http://acciotables.herokuapp.com/?page_url=https://fbref.com/en/comps/22/Major-League-Soccer-Stats&content_selector_id=%23stats_keeper_squads")
table <- page %>% html_table()
table <- table[[1]]
print(table)import pandas as pd
url = "http://acciotables.herokuapp.com/?page_url=https://fbref.com/en/comps/22/Major-League-Soccer-Stats&content_selector_id=%23stats_keeper_squads"
df = pd.read_html(url,header=0)
print(df)