Hello World, today (August 25, 2020). I trained an agent to play a navigate successfully a game called frozen lake
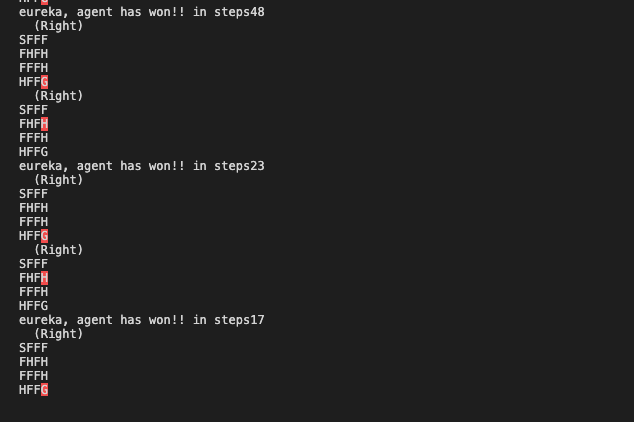
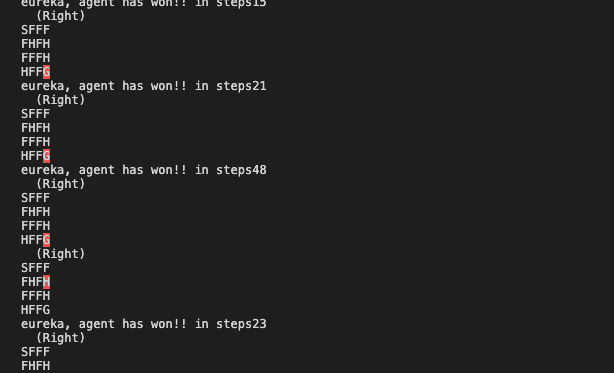
The game can be found at https://gym.openai.com/
DISCOVERIES:
learing rate:
setting learning rate at 0.1 the qtable change by very little and the accumulated reward was also low

setting learning rate at 0.7 increasing accumulated reward significantly , but the qtable changed rapidly

setting learning rate at 0.5 the agent achieve a good amount of accumulated reward and the q table changed rapidly
