A collection of resources on Transformer in CV.
🐌 Markdown Format:
🌱: Novel idea📌: The first...- 🚀: State-of-the-Art
- 👑: Novel dataset/model
- 📚:Multiple Tasks
- A Comprehensive Survey on Applications of Transformers for Deep Learning Tasks [v1](2023.06.11)
- ⭐ Ultimate-Awesome-Transformer-Attention [Awesome Repo]
- [🧩Segmentation] Transformer-Based Visual Segmentation: A Survey [Awesome Repo] [v1](2023.04.19)
- Transformer models: an introduction and catalog [v1](2023.02.12) [v2](2023.02.16)
- [📚Multimodal] A survey of transformer-based multimodal pre-trained modals [v1](2023.01.01)
- [🧬Medical] Vision Transformers in Medical Imaging: A Review [v1](2022.11.18)
- A Comprehensive Survey of Transformers for Computer Vision [v1](2022.11.11)
- [🖊GNN] A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective [v1](2022.09.27)
- [🏃Action Recognition] Vision Transformers for Action Recognition: A Survey [v1](2022.09.13)
- [🌌Remote Sensing] Transformers in Remote Sensing: A Survey [v1](2022.09.02)
- [🧬Medical] Medical image analysis based on transformer: A Review [v1](2022.08.13)
- [📚Multimodal] Multimodal Learning with Transformers: A Survey [v1](2022.06.13)
- [🧬Medical] Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives [v1](2022.06.02) [v2](2022.06.03)
- [Tiny ImageNet] Vision Transformers in 2022: An Update on Tiny ImageNet [v1](2022.05.21) [Code]
- [📦3D Point Clouds] Transformers in 3D Point Clouds: A Survey [v1](2022.05.16)
- Transformer in Computer Vision: ViT and its Progress [v1](2022.05.12)
- [🧬Medical] A survey on attention mechanisms for medical applications: are we moving towards better algorithms? [v1](2022.04.26)
- Visual Attention Methods in Deep Learning: An In-Depth Survey [v1](2022.04.16) [v2](2022.04.21)
- [🧬Medical] Vision Transformers in Medical Computer Vision -- A Contemplative Retrospection [v1](2022.03.29)
- Transformers Meet Visual Learning Understanding: A Comprehensive Review [v1](2022.03.24)
- [🧬Medical] Transformers in Medical Image Analysis: A Review [v1](2022.02.24)
- [🧬Medical] Transformers in Medical Imaging: A Survey [Awesome Repo] [v1](2022.01.24)
- Video Transformers: A Survey [v1](2022.01.16)
- A Survey of Visual Transformers [v1](2021.11.11)
- Transformers in computational visual media: A survey [v1(Computational Visual Media)](2021.10.27)
- Survey: Transformer based Video-Language Pre-training [v1](2021.09.21)
- A Survey of Transformers [v1](2021.06.08) [v2](2021.06.15)
- Transformers in Vision: A Survey [v1](2021.01.04) [v2](2021.02.22) [v3(ACM Computing Surveys)](2022.01.06)
- A Survey on Visual Transformer [v1](2020.12.23) [v2](2021.01.15) [v3](2021.01.30) [v4](2021.08.12)
-
⏳Focused Topics «🎯Back To Top»
- [💬Image-to-text](arXiv preprint 2022) GIT: A Generative Image-to-text Transformer for Vision and Language, Susan Zhang et al. [Paper]
🌱 GIT: A Generative Image-to-text Transformer, which simplifies the architecture as one image encoder and one text decoder under a single language modeling task. And also scale up the pre-training data and the model size to boost the model performance.- 📚 Image Captioning, Video Captioning, Image QA, Video QA
- [💬Pre-trained Model](arXiv preprint 2022) OPT: Open Pre-trained Transformer Language Models, Susan Zhang et al. [Paper] [Code]
🌱 Open Pre-trained Transformers (OPT): a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which aims to fully and responsibly share with interested researchers.👑 OPT-175B is comparable to GPT-3 while requiring only 1/7th the carbon footprint to develop.
- [💬Image-to-text](arXiv preprint 2022) GIT: A Generative Image-to-text Transformer for Vision and Language, Susan Zhang et al. [Paper]
-
Theoretical Thinking «🎯Back To Top»
- (arXiv preprint 2023) Understanding Gaussian Attention Bias of Vision Transformers Using Effective Receptive Fields, Bum Jun Kim et al. [Paper]
🌱 This paper analyzes the behavior of ViTs using an effective receptive field and demonstrates ViTs acquire an understanding of patch order from the positional embedding that is trained to be a specific pattern during the training.
- (BMVC 2022) How to Train Vision Transformer on Small-scale Datasets?, Hanan Gani et al. [Paper] [Code]
🌱 This work shows that self-supervised inductive biases can be learned directly from small-scale datasets and serve as an effective weight initialization scheme for fine-tuning.
- (arXiv preprint 2022) Can CNNs Be More Robust Than Transformers?, Zeyu Wang et al. [Paper] [Code]
🌱 This paper proposed three highly effective pure CNN architecture designs without any attention-like operations for boosting robustness, yet simple enough to be implemented in several lines of code, namely a) patchifying input images, b) enlarging kernel size, and c) reducing activation layers and normalization layers.
- (CVPR 2022) Are Multimodal Transformers Robust to Missing Modality?, Mengmeng Ma et al. [Paper]
📌 The first comprehensively investigates the behavior of Transformers in the presence of modal-incomplete data.🌱 A principle method improves the robustness of Transformer models by automatically searching for an optimal fusion strategy regarding input data.
- (arXiv preprint 2021) Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer, Yifan Xu et al. [Paper]
🌱 Evo-ViT: a self-motivated slow-fast token evolution method for vision transformers, which conducts unstructured instance-wise token selection by taking advantage of the global class attention that is unique to vision transformers.🌱 Significantly reduce the computational costs of vision transformers while maintaining comparable performance on image classification.
- (ICCV 2021) An Empirical Study of Training Self-Supervised Vision Transformers, Xinlei Chen et al. [Paper]
🌱 Instability is a major issue that degrades accuracy, and it can be hidden by apparently good results.
- (ICCV 2021) Rethinking and Improving Relative Position Encoding for Vision Transformer, Kan Wu et al. [Paper] [Code]
🌱 image RPE (iRPE): New relative position encoding methods dedicated to 2D images which consider directional relative distance modeling as well as the interactions between queries and relative position embeddings in a self-attention mechanism.🌱 Simple, lightweight and can be easily plugged into transformer blocks.
- (arXiv preprint 2021) Early Convolutions Help Transformers See Better, Tete Xiao et al. [Paper]
🌱 Replace the ViT stem with a small number of stacked stride-two 3x3 convolutions.🌱 Dramatically increases optimization stability and also improves peak performance (by ~1-2% top-1 accuracy on ImageNet-1k), while maintaining flops and runtime.
- (arXiv preprint 2021) XCiT: Cross-Covariance Image Transformers, Alaaeldin El-Nouby et al. [Paper] [Code]
🌱 A "transposed" version of self-attention : operates across feature channels rather than tokens, where the interactions are based on the cross-covariance matrix between keys and queries.- 📚 Image Classification, Self-supervised Feature Learning, Object Detection, Instance Segmentation, Semantic Segmentation
- (arXiv preprint 2021) Transformer in Convolutional Neural Networks, Yun Liu et al. [Paper]
📌 First learns feature relationships within small grids by viewing image patches as tokens.🌱 Hierarchical MHSA (H-MHSA): computed in a hierarchical manner.🌱 Pluggable into any CNN architectures- 📚 Image Classification, Object Detection, Instance Segmentation
- (arXiv preprint 2021) Are Convolutional Neural Networks or Transformers more like human vision?, Shikhar Tuli et al. [Paper] [Code]
🌱 Understand Transformer
- (arXiv preprint 2021) KVT: k-NN Attention for Boosting Vision Transformers, Sachin Mehta et al. [Paper]
🌱 Select the top-k similar tokens from the keys for each query to compute the attention map, instead of involving all the tokens for attention matrix calculation.🌱 K-NN attention is powerful in distilling noise from input tokens and in speeding up training.
- (ICLR 2021) DeLighT: Deep and Light-weight Transformer, Sachin Mehta et al. [Paper] [Code]
🌱 A deep and light-weight transformer.🌱 (1) Within each Transformer block using a deep and lightweight transformation. (2) Across blocks using block-wise scaling.
- (arXiv preprint 2023) Understanding Gaussian Attention Bias of Vision Transformers Using Effective Receptive Fields, Bum Jun Kim et al. [Paper]
-
Backbone «🎯Back To Top»
-
(arXiv preprint 2021) Swin Transformer V2: Scaling Up Capacity and Resolution, Ze Liu et al. [Paper] [Code]
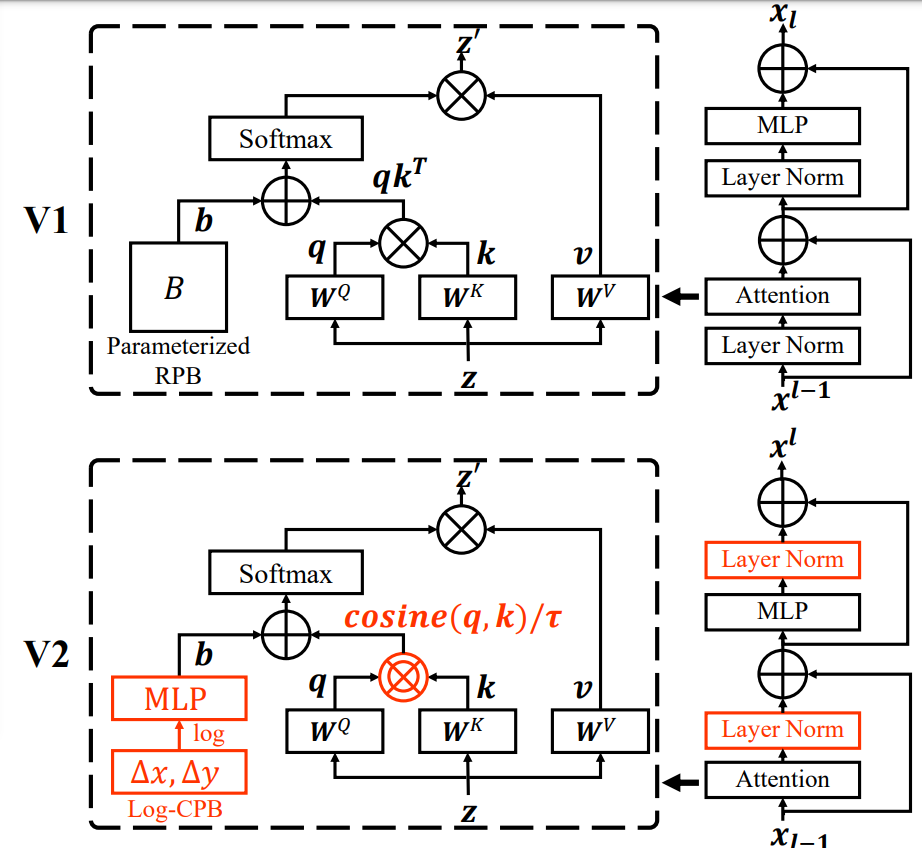
- 🚀 84.0% top-1 accuracy on ImageNet-V2 Image Classification; 63.1/54.4 box/mask mAP on COCO Object Detection; 59.9 mIoU on ADE20K Semantic Segmentation; 86.8% top-1 accuracy on Kinetics-400 Video Action Classification.
- 🌱 Scaling Swin Transformer up to 3 billion parameters; Making it capable of training with images/windows of up to 1,536×1,536 resolution; Achieving state-of-the-art accuracy on a variety of benchmarks.
-
(arXiv preprint 2021) Improved Robustness of Vision Transformer via PreLayerNorm in Patch Embedding, Bum Jun Kim et al. [Paper]
🌱 This paper examines the behavior and robustness of ViT in more detail with various image transforms.🌱 PreLayerNorm: modify patch embedding structure to ensure scale-invariant behavior of ViT, when the color scale changes in ViT's patch embedding.
-
(arXiv preprint 2021) UniNet: Unified Architecture Search with Convolution, Transformer, and MLP, Jihao Liu et al. [Paper]
🌱 The widely-used stridden convolution or pooling-based down-sampling modules become the performance bottlenecks when the operators are combined to form a network. Two novel context-aware down-sampling modules, which can better adapt to the global information encoded by transformer and MLP operators.📌 The first optimal combination of convolution, transformer and MLP to identify high-performance visual neural networks.🚀 Outperforms pure convolution-based architecture(EfficientNet), and pure transformer-based architecture(Swin-Transformer), on ImageNet classification, COCO object detection, and ADE20K semantic segmentation.
-
(arXiv preprint 2021) MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer, Sachin Mehta et al. [Paper]
🌱 MobileViT: a light-weight and general-purpose vision transformer for mobile devices, which presents a different perspective for the global processing of information with transformers.🌱 MobileViT significantly outperforms CNN- and ViT-based networks across different tasks and datasets.
-
(arXiv preprint 2021) DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification, Yongming Rao et al. [Paper] [Code] [Project]
🌱 A dynamic token sparsification framework which used to prune redundant tokens progressively and dynamically based on the input.🌱 To optimize the prediction module in an end-to-end manner, an attention masking strategy is used to differentiably prune a token by blocking its interactions with other tokens.🌱 This method greatly reduces 31%~37% FLOPs and improves the throughput by over 40% while the drop of accuracy is within 0.5% for various vision transformers.
-
(ICCV 2021) AutoFormer: Searching Transformers for Visual Recognition, Minghao Chen et al. [Paper] [Code]

(From: https://github.com/microsoft/AutoML/tree/main/AutoFormer)
📌 First effort to design an automatic search algorithm for finding vision transformer models.🌱 Without extra finetuning or retraining, the trained supernet is able to produce thousands of high-quality transformers by inheriting weights from it directly.
-
(ICCV 2021) Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Ze Liu et al. [Paper] [Code]

(From: https://github.com/microsoft/Swin-Transformer [2021/11/28])
🌱 A hierarchical Transformer which representation is computed with shifted windows.🌱 The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection.
- 📚 Image Classification, Object Detection, Instance Segmentation, Semantic Segmentation, Real-Time Object Detection
-
(ICCV 2021) Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet, Li Yuan et al. [Paper] [Code]
🌱 Tokens-To-Token Vision Transformer (T2T-ViT), which incorporates 1) a layer-wise Tokens-to-Token (T2T) transformation to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token (Tokens-to-Token), such that local structure represented by surrounding tokens can be modeled and tokens length can be reduced; 2) an efficient backbone with a deep-narrow structure for vision transformer motivated by CNN architecture design after empirical study.
-
(ICCV 2021) Vision Transformer with Progressive Sampling, Xiaoyu Yue et al. [Paper] [Code]
🌱 PS-ViT: an iterative and progressive sampling strategy to locate discriminative regions. At each iteration, embeddings of the current sampling step are fed into a transformer encoder layer, and a group of sampling offsets is predicted to update the sampling locations for the next step.
-
(ICCV 2021) Rethinking Spatial Dimensions of Vision Transformers, Byeongho Heo et al. [Paper] [Code]
🌱 Spatial dimension reduction is beneficial to a transformer architecture.🌱 Pooling-based Vision Transformer (PiT) upon the original ViT model.
-
(ACMMM 2021) DPT: Deformable Patch-based Transformer for Visual Recognition, Zhiyang Chen et al. [Paper] [Code]
🌱 The Deformable Patch (DePatch) module learns to adaptively split the images into patches with different positions and scales in a data-driven way, which can well preserve the semantics in patches.🌱 The DePatch module can work as a plug-and-play module, which can easily incorporate into different transformers to achieve end-to-end training.- 📚 Image Classification, Object Detection
-
(arXiv preprint 2021) Go Wider Instead of Deeper, Fuzhao Xue et al. [Paper]
🌱 Replace feedforward network (FFN) with mixture-of-experts (MoE) and share the MoE layers across transformer blocks using individual layer normalization. Such deployment plays the role to transform various semantic representations, which makes the model more parameter-efficient and effective.
-
(ICCV 2021) Conformer: Local Features Coupling Global Representations for Visual Recognition, Zhiliang Peng et al[Paper] [Code]
🌱 A hybrid network structure with Convs and attention mechanisms.
-
(ICCV 2021) Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions, Wenhai Wang et al. [Paper] [Code]
🌱 Pyramid Vision Transformer(PVT): can be not only trained on dense partitions of the image to achieve high output resolution but also using a progressive shrinking pyramid to reduce computations of large feature maps.- 📚 Object Detection, Instance Segmentation, Semantic Segmentation
-
(arXiv preprint 2021) Focal Self-attention for Local-Global Interactions in Vision Transformers, Jianwei Yang et al. [Paper]
🌱 Focal self-attention: a new mechanism that incorporates both fine-grained local and coarse-grained global interactions. Each token attends the closest surrounding tokens at fine granularity, but the tokens far away at a coarse granularity, and thus can capture both short- and long-range visual dependencies efficiently and effectively.- 🚀 SOTA on ADE20K dataset, ADE20K val for Semantic Segmentation
- 🚀 SOTA on COCO test-dev, minival for Instance Segmentation
- 📚 Image Classification, Object Detection, Instance Segmentation, Semantic Segmentation
-
(arXiv preprint 2021) CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows, Xiaoyi Dong et al. [Paper] [Code]
🌱 Cross-Shaped Window self-attention: compute self-attention in the horizontal and vertical stripes in parallel forms a cross-shaped window. Each stripe is obtained by splitting the input feature into stripes of equal width.- 📚 Object Detection, Semantic Segmentation
-
-
Vision and Language «🎯Back To Top»
- (arXiv preprint 2021) CogView: Mastering Text-to-Image Generation via Transformers, Ming Ding et al. [Paper] [Code] [Demo Website(Chinese)]
📌 The first open-source large text-to-image transformer.🌱 A 4-billion-parameter Transformer with VQ-VAE tokenizer .🌱 Adapting for diverse downstream tasks: style learning (domain-specific text-to-image), super-resolution (image-to-image), image captioning (image-to-text), and even text-image reranking.- 👑 A large-scale 30 million text-image pairs dataset.
- (arXiv preprint 2021) Episodic Transformer for Vision-and-Language Navigation, Alexander Pashevich et al. [Paper] [Code]
🌱 An attention-based architecture for vision-and-language navigation.🌱 Use synthetic instructions as the intermediate interface between the human and the agent.- 🚀 SOTA on ALFRED
- (CVPR 2021 AI for Content Creation Workshop) High-Resolution Complex Scene Synthesis with Transformers, Manuel Jahn et al. [Paper]
🌱 An orthogonal approach to the controllable synthesis of complex scene images, where the generative model is based on pure likelihood training without additional objectives.
- (ICML 2021) ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision, Wonjae Kim et al. [Paper] [Code]
🌱 Without region features or deep convolutional visual encoders.🌱 Drive performance on whole word masking and image augmentations in Vision-and-Language Pretraining (VLP) training schemes.
- (arXiv preprint 2021) VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning, Jun Chen et al. [Paper] [Code]
📌 The first large pretrained language models for image captioning.
- (CVPR 2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain, Mingchen Zhuge et al. [Paper] [Code] [Video]
📌 The first method extracts a series of multi-grained image patches for the image modality.🌱 Kaleido strategy
- (arXiv preprint 2020) ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data, Di Qi et al. [Paper]
🌱 Pre-training with a large-scale Image-Text dataset.
- (CVPR 2020) 12-in-1: Multi-Task Vision and Language Representation Learning, Jiasen Lu et al. [Paper] [Code]
🌱 Multi-task training
- (NeurlIPS 2019) ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks, Jiasen Lu et al. [Paper] [Code]
🌱 Cross-modality co-attention layers.
- (ICCV 2019) VideoBERT: A Joint Model for Video and Language Representation Learning, Chen Sun et al. [Paper] [Code]
📌 The first Video-Text Pre-Training Model.
- (arXiv preprint 2019) VisualBERT: A Simple and Performant Baseline for Vision and Language, Liunian Harold Li et al. [Paper] [Code]
📌 The first Image-Text Pre-Training Model.
- (arXiv preprint 2019) Visual Grounding with Transformers, Ye Du et al. [Paper] [Code]
🌱 Visual grounding task.
- (arXiv preprint 2021) CogView: Mastering Text-to-Image Generation via Transformers, Ming Ding et al. [Paper] [Code] [Demo Website(Chinese)]
-
GNN «🎯Back To Top»
-
Image Classification «🎯Back To Top»
- (arXiv preprint 2022) [💬360° Image Classification] Spherical Transformer, Sungmin Cho et al. [Paper]
📌 The first to leverage the transformer architecture to perform representation learning for 360° images, which is suitable for reducing the projection and rotation distortions.🌱 SPHTR: can be easily plugged into existing sampling methods and alleviate rotation distortion effectively.
- (arXiv preprint 2021) ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases, Stéphane d'Ascoli et al. [Paper] [Code]
🌱 The ConViT is simply a ViT where the first 10 blocks replace the Self-Attention (SA) layers with a Gated Positional Self-Attention(GPSA) layer with a convolutional initialization.🌱 The Gated Positional Self-Attention(GPSA) is a form of positional self-attention which can be equipped with a "soft" convolutional inductive bias.
- (arXiv preprint 2021) LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference, Benjamin Graham et al. [Paper] [Code]
🌱 Introduce a new way to integrate positional information in vision transformers--attention bias.🌱 LeViT: a hybrid neural network for fast inference image classification.🌱 5 times faster than EfficientNet on CPU.
- (arXiv preprint 2021) Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet, Luke Melas-Kyriazi [Paper] [Code]
🌱 Attention Layer-free
- (arXiv preprint 2021) Self-Supervised Learning with Swin Transformers, Zhenda Xie et al [Paper] [Code]
🌱 A self-supervised learning approach based on vision transformers as backbone.
- (arXiv preprint 2021) CvT: Introducing Convolutions to Vision Transformers, Haiping Wu et al [Paper] [Unofficial Code]
🌱 Improve Vision Transformer (ViT) in performance and efficiency by introducing desirable properties of convolutional neural networks (CNNs) into ViT architecture (shift, scale, and distortion invariance), while maintaining the merits of Transformers (dynamic attention, global context, and better generalization).
- (arXiv preprint 2021) Twins: Revisiting the Design of Spatial Attention in Vision Transformers, Xiangxiang Chu et al [Paper] [Code]
🌱 Two vision transformer architectures(Twins- PCPVT and Twins-SVT).🌱 May serve as stronger backbones for many vision tasks.
- (arXiv preprint 2021) Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length, Yulin Wang et al. [Paper] [Code]
🌱 Dynamic token numbers for different images.🌱 Efficient feature reuse and relationship reuse mechanisms across different components.
- (arXiv preprint 2021) MSG-Transformer: Exchanging Local Spatial Information by Manipulating Messenger Tokens, Jiemin Fang et al. [Paper] [Code]
🌱 Propose addtional messenger token to exchange information from different regions.
- (arXiv preprint 2022) [💬360° Image Classification] Spherical Transformer, Sungmin Cho et al. [Paper]
-
Object Detection «🎯Back To Top»
-
(CVPR 2022) TESTR: Text Spotting Transformers, Xiang Zhang et al. [Paper] [Code]
🌱 TExt Spotting TRansformers (TESTR), a generic end-to-end text spotting framework using Transformers for text detection and recognition in the wild. TESTR builds upon a single encoder and dual decoders for the joint text-box control point regression and character recognition. Other than most existing literature, this method is free from Region-of-Interest operations and heuristics-driven post-processing procedures; TESTR is particularly effective when dealing with curved text-boxes where special cares are needed for the adaptation of the traditional bounding-box representations. This paper shows canonical representation of control points suitable for text instances in both Bezier curve and polygon annotations. In addition, the authors design a bounding-box guided polygon detection (box-to-polygon) process. Experiments on curved and arbitrarily shaped datasets demonstrate state-of-the-art performances of the proposed TESTR algorithm.
-
(CVPR 2022) DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection, Hao Zhang et al. [Paper] [Code]
-
-
-
🌱 DINO: improves over previous DETR-like models in performance and efficiency by using a contrastive way for denoising training, a mixed query selection method for anchor initialization, and a look forward twice scheme for box prediction. DINO achieves 48.3AP in 12 epochs and 51.0AP in 36 epochs on COCO with a ResNet-50 backbone and multi-scale features, yielding a significant improvement of +4.9AP and +2.4AP, respectively, compared to DN-DETR, the previous best DETR-like model. DINO scales well in both model size and data size. Without bells and whistles, after pre-training on the Objects365 dataset with a SwinL backbone, DINO obtains the best results on both COCO val2017 (63.2AP) and test-dev (63.3AP). Compared to other models on the leaderboard, DINO significantly reduces its model size and pre-training data size while achieving better results.
-
-
(ICLR 2022) DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR, Shilong Liu et al. [Paper] [Code]
🌱 DAB-DETR: present a novel query formulation using dynamic anchor boxes for DETR (DEtection TRansformer) and offer a deeper understanding of the role of queries in DETR. This new formulation directly uses box coordinates as queries in Transformer decoders and dynamically updates them layer-by-layer. Using box coordinates not only helps using explicit positional priors to improve the query-to-feature similarity and eliminate the slow training convergence issue in DETR, but also allows us to modulate the positional attention map using the box width and height information
-
(arXiv preprint 2021) Multi-modal Transformers Excel at Class-agnostic Object Detection, Muhammad Maaz et al. [Paper] [Code]

(From: https://github.com/mmaaz60/mvits_for_class_agnostic_od [2021/11/28])
🌱 MDef-DETR: an efficient and flexible Multi-modal Vision Transformers (MViT) architecture using multi-scale feature processing and deformable self-attention that can adaptively generate proposals given a specific language query for OpenWorld object detection, salient and camouflage object detection, supervised and self-supervised detection tasks.
-
(arXiv preprint 2021) ViDT: An Efficient and Effective Fully Transformer-based Object Detector, Hwanjun Song et al. [Paper] [Code]
🌱 Vision and Detection Transformers (ViDT): an effective and efficient object detector introduces a reconfigured attention module to extend the recent Swin Transformer to be a standalone object detector, followed by a computationally efficient transformer decoder.
-
(CVPR 2021) You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection, Zhigang Dai et al [Paper] [Code]
🌱 2D object detection can be accomplished in a pure sequence-to-sequence manner by taking a sequence of fixed-sized non-overlapping image patches as input.🌱 Discuss the impacts of prevalent pre-train schemes and model scaling strategies for Transformer in vision.
-
(CVPR 2021) UP-DETR: Unsupervised Pre-training for Object Detection with Transformers, Zhigang Dai et al [Paper] [Code]
🌱 Multi-task learning & Multi-query localization🌱 Random query patch detection.
-
(arXiv preprint 2021) Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Ze Liu et al. [Paper] [Code]
- ⭐ SOTA on COCO test-dev, COCO minival
-
(arXiv preprint 2021) Twins: Revisiting the Design of Spatial Attention in Vision Transformers, Xiangxiang Chu et al [Paper]
-
-
Object Tracking «🎯Back To Top»
- (arXiv preprint 2021) MOTR: End-to-End Multiple-Object Tracking with TRansformer, Fangao Zeng et al. [Paper] [Code]
📌 The first fully end-toend multiple-object tracking framework.🌱 Model the long-range temporal variation of the objects.🌱 Introduce the concept of “track query” to models the entire track of an object.
- (arXiv preprint 2021) TrTr: Visual Tracking with Transformer, Moju Zhao et al. [Paper] [Code]
🌱 Transformer models template and search in targe image.
- (arXiv preprint 2021) MOTR: End-to-End Multiple-Object Tracking with TRansformer, Fangao Zeng et al. [Paper] [Code]
-
Instance Segmentation «🎯Back To Top»
-
Semantic Segmentation «🎯Back To Top»
- (arXiv preprint 2021) [Video] TransVOS: Video Object Segmentation with Transformers, Jianbiao Mei et al. [Paper]
🌱 Fully exploit and model both the temporal and spatial relationships.- 🚀 SOTA on DAVIS and YouTube-VOS
- (arXiv preprint 2021) Vision Transformers for Dense Prediction, René Ranftl et al. [Paper] [Code]
- (arXiv preprint 2021) Twins: Revisiting the Design of Spatial Attention in Vision Transformers, Xiangxiang Chu et al [Paper]
- (arXiv preprint 2021) Segmenter: Transformer for Semantic Segmentation, Robin Strudel et al. [Paper] [Code]
🌱 Convolution-free🌱 Capture contextual information by design and outperform Fully Convolutional Networks(FCN) based approaches.
- (arXiv preprint 2021) SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers, Enze Xie et al. [Paper] [Code]
🌱 A novel hierarchically structured Transformer encoder which outputs multiscale features.🌱 Proposed MLP decoder aggregates information from different layers, combined both local and global attention.
- (arXiv preprint 2021) [Video] TransVOS: Video Object Segmentation with Transformers, Jianbiao Mei et al. [Paper]
-
Image Retrieval «🎯Back To Top»
-
Video Understanding «🎯Back To Top»
- (arXiv preprint 2021) ViViT: A Video Vision Transformer, Anurag Arnab et al. [Paper] [Code]
🌱 Convolution-free- ⭐ SOTA on Kinetics-400/600
- (arXiv preprint 2021) Is Space-Time Attention All You Need for Video Understanding?, Gedas Bertasius et al. [Paper] [Code]
🌱 Convolution-free
- (arXiv preprint 2021) ViViT: A Video Vision Transformer, Anurag Arnab et al. [Paper] [Code]
-
Monocular Depth Estimation «🎯Back To Top»
- (arXiv preprint 2021) Vision Transformers for Dense Prediction, René Ranftl et al. [Paper] [Code]
- 🚀 SOTA on NYU-Depth V2
- (arXiv preprint 2021) Vision Transformers for Dense Prediction, René Ranftl et al. [Paper] [Code]
-
GAN «🎯Back To Top»
- (arXiv preprint 2021) ViTGAN: Training GANs with Vision Transformers, Kwonjoon Lee et al. [Paper]
🌱 Integrate the Vision Transformers (ViTs) architecture into generative adversarial networks (GANs).🌱 Introduce novel regularization techniques for training GANs with ViTs to solve the serious instability during training.
- (arXiv preprint 2021) TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up, Yifan Jiang et al. [Paper(V3)] [Code]
📌 The first pilot study in building a GAN completely free of convolutions, using only pure transformer-based architectures.🌱 Introduce a new module of grid self-attention for alleviating the memory bottleneck to scale up TransGAN to high-resolution generation.🌱 Develop a unique training recipe: data augmentation, modified normalization and relative position encoding.
- (arXiv preprint 2021) TransGAN: Two Transformers Can Make One Strong GAN, Yifan Jiang et al. [Paper(V1)] [Paper(V2)] [Code]
🌱 Convolution-free
- (arXiv preprint 2021) ViTGAN: Training GANs with Vision Transformers, Kwonjoon Lee et al. [Paper]
-
Deepfake Detection «🎯Back To Top»
- (arXiv preprint 2021) M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection, Junke Wang et al. [Paper]
📌 The first Multi-modal Multi-scale Transformer- 👑 face Swapping and facial Reenactment DeepFake(SR-DF) Dataset
- (arXiv preprint 2021) M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection, Junke Wang et al. [Paper]
-
Perceptual Representation «🎯Back To Top»
- (CVPR 2021-NTIRE workshop) Perceptual Image Quality Assessment with Transformers, Manri Cheon et al. [Paper] [Code(TBD)]
- 🚀 1st Place in NTIRE 2021 perceptual IQA challenge.
- (CVPR 2021-NTIRE workshop) Perceptual Image Quality Assessment with Transformers, Manri Cheon et al. [Paper] [Code(TBD)]
-
Low Level Vision «🎯Back To Top»
- (CVPR 2022) TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions, Jeya Maria Jose Valanarasu et al. [Paper] [Code] [Project]
- 🌱 TransWeather: a transformer-based end-to-end model with just a single encoder and a decoder that can restore an image degraded by any weather condition.
- (CVPR 2021) Pre-Trained Image Processing Transformer, Hanting Chen et al. [Paper] [Code] [2nd code]
🌱 Various image processing tasks based Transformer.
- (CVPR 2022) TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions, Jeya Maria Jose Valanarasu et al. [Paper] [Code] [Project]
-
Sign Language «🎯Back To Top»
- (ACMMM 2021) Contrastive Disentangled Meta-Learning for Signer-Independent Sign Language Translation, Tao Jin et al. [Paper]
- 🚀 SOTA on PHOENIX14T for Sign Language Translation
🌱 Contrastive Disentangled Meta-learning (CDM): focuses on augmenting the generalization ability of the translation model.🌱 We facilitate the frame-word alignments by leveraging contrastive constraints between the obtained task-specific representation and the decoding output.🌱 Considering that vanilla meta-learning methods utilize the multiple specific signers insufficiently, a fine-grained learning strategy is introduced that simultaneously conducts meta-learning in various domain shift scenarios in each iteration.
- (ACMMM 2021) SimulSLT: End-to-End Simultaneous Sign Language Translation, Aoxiong Yin et al. [Paper]
📌 The first end-to-end simultaneous sign language translation model, which can translate sign language videos into target text concurrently.🌱 SimulSLT: composed of a text decoder, a boundary predictor, and a masked encoder. 1) use the wait-k strategy for simultaneous translation. 2) design a novel boundary predictor based on the integrate-and-fire module to output the gloss boundary, which is used to model the correspondence between the sign language video and the gloss. 3) propose an innovative re-encode method to help the model obtain more abundant contextual information, which allows the existing video features to interact fully.🌱 SimulSLT achieves BLEU scores that exceed the latest end-to-end non-simultaneous sign language translation model while maintaining low latency.
- (ICCV 2021) Mixed SIGNals: Sign Language Production via a Mixture of Motion Primitives, Ben Saunders et al. [Paper]
🌱 Splitting the Sign Language Production (SLP) task into two distinct jointly-trained sub-tasks. (1) Translation sub-task: translate from spoken language to a latent sign language representation with gloss supervision. (2) Animation sub-task: produce expressive sign language sequences that closely resemble the learned spatio-temporal representation.🌱 Mixture of Motion Primitives (MoMP): temporally combine at inference to animate continuous sign language sequences.
- (arXiv preprint 2021) Aligning Subtitles in Sign Language Videos, Hannah Bull et al. [Paper] [Project]
📌 The first subtitle alignment task based on Transformers.
- (arXiv preprint 2021) Continuous 3D Multi-Channel Sign Language Production via Progressive Transformers and Mixture Density Networks, Ben Saunders et al. [Paper]
📌 The first Sign Language Production(SLP) model to translate from discrete spoken language sentences to continuous 3D multi-channel sign pose sequences in an end-to-end manner.- (Extended journal version of Progressive Transformers for End-to-End Sign Language Production)
- (WACV 2021) Pose-based Sign Language Recognition using GCN and BERT, Anirudh Tunga et al. [Paper]
🌱 Capture the spatial interactions in every frame comprehensively before utilizing the temporal dependencies between various frames.
- (CVPR 2020) Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation, Necati Cihan Camgoz et al. [Paper] [Code]
📌 The first successful application of transformers for Continuous Sign Language Recognition(CSLR) and Sign Language Translation(SLT).🌱 A novel multi-task formalization of CSLR and SLT exploits the supervision power of glosses, without limiting the translation to spoken language.
- (COLING 2020 & ECCV 2020 SLRTP Workshop) Better Sign Language Translation with STMC-Transformer, Kayo Yin et al. [Paper] [Code]
📌 The first work adopts weight tying, transfer learning, and ensemble learning in Sign Language Translation(SLT).- 🚀 SOTA on ASLG-PC12
- (ECCV 2020 Workshop) Multi-channel Transformers for Multi-articulatory Sign Language Translation, Necati Cihan Camgoz et al. [Paper]
📌 The first successful approach to multi-articulatory Sign Language Translation(SLT), which models the inter and intra contextual relationship of manual and non-manual channels.🌱 A novel multi-channel transformer architecture supports multi-channel, asynchronous, sequence-to-sequence learning.
- (ECCV 2020) Progressive Transformers for End-to-End Sign Language Production, Ben Saunders et al. [Paper] [Code]
- (ECCV 2020) Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuous Sign Language Recognition, Zhe Niu et al. [Paper] [Code]
🌱 Propose stochastic frame dropping (SFD) and stochastic gradient stopping (SGS) to reduce video memory footprint, improve model robustness and alleviate the overfitting problem during model training.
- (ACMMM 2021) Contrastive Disentangled Meta-Learning for Signer-Independent Sign Language Translation, Tao Jin et al. [Paper]
-
Medical Image Segmentation «🎯Back To Top»
- (MICCAI 2021) TransBTSV2: Wider Instead of Deeper Transformer for Medical Image Segmentation, Jiangyun Li et al. [Paper] [Code]
🌱 TransBTSV2: a hybrid CNN-Transformer architecture, which is not limited to brain tumor segmentation (BTS) but focuses on general medical image segmentation, providing a strong and efficient 3D baseline for volumetric segmentation of medical images.
- (arXiv preprint 2021) UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer, Haonan Wang et al. [Paper] [Code]
📌 The first method to rethink the self-attention mechanism of Transformer from a channel-wise perspective.🌱 UCTransNet (with a proposed CTrans module in U-Net): the CTrans module is an alternate of the U-Net skip connections, which consists of (1) a sub-module to conduct the multi-scale Channel Cross fusion with Transformer; (2) a sub-module Channel-wise Cross-Attention to guide the fused multi-scale channel-wise information, to connect to the decoder features for eliminating the ambiguity effectively.
- (arXiv preprint 2021) nnFormer: Interleaved Transformer for Volumetric Segmentation, Hong-Yu Zhou et al. [Paper] [Code]
🌱 nnFormer(Not-aNother transFormer): A powerful segmentation model with an interleaved architecture based on empirical combination of self-attention and convolution, which learns volumetric representations from 3D local volumes.
- (arXiv preprint 2021) LeViT-UNet: Make Faster Encoders with Transformer for Medical Image Segmentation, Guoping Xu et al. [Paper] [Code]
🌱 LeViT-UNet: integrate a LeViT Transformer module into the U-Net architecture, for fast and accurate medical image segmentation.
- (MICCAI 2021) A Multi-Branch Hybrid Transformer Network for Corneal Endothelial Cell Segmentation, Yinglin Zhang et al. [Paper]
🌱 Multi-Branch hybrid Transformer Network (MBT-Net): based on the transformer and body-edge branch.🌱 The convolutional block focuses on local texture feature extraction. The transformer and residual connection establish long-range dependencies over space, channel, and layer.
- (MICCAI 2021) Progressively Normalized Self-Attention Network for Video Polyp Segmentation, GePeng Ji et al. [Paper] [Code]
🌱 Progressively Normalized Self-attention Network(PNS-Net): efficiently learn representations from polyp videos with real-time speed ( ∼140fps) on a single RTX 2080 GPU and no postprocessing.
- (MICCAI 2021) UTNet: A Hybrid Transformer Architecture for Medical Image Segmentation, Yunhe Gao et al. [Paper]
🌱 This approach addresses the dilemma that Transformer requires huge amounts of data to learn vision inductive bias.
- (MICCAI 2021) Multi-Compound Transformer for Accurate Biomedical Image Segmentation, Yuanfeng Ji et al. [Paper] [Code]
🌱 Multi-Compound Transformer (MCTrans): incorporate rich feature learning and semantic structure mining into a unified framework.🌱 A learnable proxy embedding: model semantic relationship.
- (MICCAI 2021) Medical Transformer: Gated Axial-Attention for Medical Image Segmentation, Jeya Maria Jose Valanarasu et al. [Paper] [Code]
🌱 Gated Axial-Attention model: introduce an additional control mechanism in the self-attention module.🌱 Local-Global training strategy (LoGo): operate on the whole image and patches to learn global and local features.
- (arXiv preprint 2021) DS-TransUNet:Dual Swin Transformer U-Net for Medical Image Segmentation, Ailiang Lin et al. [Paper]
📌 The first attempt to concurrently incorporate the advantages of hierarchical Swin Transformer into both encoder and decoder of the standard U-shaped architecture to enhance the semantic segmentation quality of varying medical images.🌱 Introduce the Swin Transformer block into decoder to further explore the long-range contextual information during the up-sampling process.
- (arXiv preprint 2021) TransBTS: Multimodal Brain Tumor Segmentation Using Transformer, Wenxuan Wang et al. [Paper] [Code]
📌 The first time to exploits Transformer in 3D CNN for MRI Brain Tumor Segmentation.
- (arXiv preprint 2021) U-Net Transformer: Self and Cross Attention for Medical Image Segmentation, Olivier Petit et al. [Paper]
🌱 U-Net Transformer: combines a U-shaped architecture for image segmentation with self- and cross-attention from Transformers.🌱 Overcome the inability of U-Nets to model long-range contextual interactions and spatial dependencies
- (arXiv preprint 2021) SpecTr: Spectral Transformer for Hyperspectral Pathology Image Segmentation, Boxiang Yun et al. [Paper] [Code]
📌 The first time to formulate the contextual feature learning across spectral bands for hyperspectral pathology image segmentation as a sequence-to-sequence prediction procedure by transformers.🌱 SpecTr outperforms other competing methods in a hyperspectral pathology image segmentation benchmark without the need for pre-training.
- (arXiv preprint 2021) TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation, Jieneng Chen et al. [Paper] [Code]
🌱 TransUNet: merits both Transformers and U-Net, as a strong alternative for medical image segmentation.🌱 Transformers can serve as strong encoders for medical image segmentation tasks, with the combination of U-Net to enhance finer details by recovering localized spatial information.
- (IJCAI 2021) Medical Image Segmentation using Squeeze-and-Expansion Transformers, Shaohua Li et al. [Paper] [Code]
🌱 A novel squeezed attention block regularizes the self-attention of transformers, and an expansion block learns diversified representations.🌱 A new positional encoding scheme for transformers, imposing a continuity inductive bias for images.
- (arXiv preprint 2021) Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation, Hu Cao et al. [Paper] [Code]
📌 The first pure Transformer-based U-shaped architecture .
- (MICCAI 2021) TransBTSV2: Wider Instead of Deeper Transformer for Medical Image Segmentation, Jiangyun Li et al. [Paper] [Code]
-
Other Applications «🎯Back To Top»
-
(arXiv preprint 2023) [💬Biomarker Prediction] Fully transformer-based biomarker prediction from colorectal cancer histology: a large-scale multicentric study, Sophia J. Wagner et al. [Paper]
🌱 A fully transformer-based end-to-end pipeline trained on thousands of pathology slides yields clinical-grade performance for biomarker prediction on surgical resections and biopsies.
-
(CVPR 2022) [💬Grounded Situation Recognition] Collaborative Transformers for Grounded Situation Recognition, Junhyeong Cho et al. [Paper] [Code] [Project]
🌱 CoFormer: A novel approach where the two processes for activity classification and entity estimation are interactive and complementary to achieve accurate grounded situation recognition.
-
(arXiv preprint 2022) [💬Image Editing] MaskGIT: Masked Generative Image Transformer, Huiwen Chang et al. [Paper]
🌱 MaskGIT: a novel image synthesis paradigm using a bidirectional transformer decoder.🌱 Training: predict randomly masked tokens by attending to tokens in all directions. Inference: the model begins with generating all tokens of an image simultaneously and then refines the image iteratively conditioned on the previous generation.- 📚 Image editing tasks: Class-conditional Image Generation; Image Manipulation; Image Inpainting; Image Outpainting(Extrapolation).
-
(arXiv preprint 2022) [💬Video Restoration] VRT: A Video Restoration Transformer, Jingyun Liang et al. [Paper] [Code]
- 🚀 SOTA on 3 video restoration tasks (video super-resolution, video deblurring, video denoising) on 9 benchmark datasets.
🌱 Video Restoration Transformer (VRT): is composed of multiple scales, each of which consists of two kinds of modules: temporal mutual self attention (mutual attention--joint motion estimation, feature alignment, feature fusion; self attention--feature extraction) and parallel warping (further fuse information from neighboring frames).
-
(arXiv preprint 2022) [💬Scene Graph Generation] RelTR: Relation Transformer for Scene Graph Generation, Yuren Cong et al. [Paper] [Code]
🌱 RelTR: an end-to-end scene graph generation model which has an encoder(visual feature context)-decoder(triplets subject-predicate-object) architecture.🌱 RelTR is a one-stage method that predicts a set of relationships directly only using visual appearance without combining entities and labeling all possible predicates.
-
(AAAI 2022) [💬Zero-Shot Learning] TransZero: Attribute-guided Transformer for Zero-Shot Learning, Shiming Chen et al. [Paper] [Code]
📌 The first work extends the Transformer to the Zero-shot learning task.- 🚀 SOTA on 3 Zero-shot learning datasets: CUB(Fine-grained), SUN(Fine-grained), and AWA2(Coarse-grained).
🌱 TransZero: an attribute-guided Transformer network that refines visual features and learns attribute localization for discriminative visual embedding representations in Zero-shot learning (ZSL).🌱 The locality-augmented visual features (from a feature augmentation encoder) and semantic vectors (from a visual-semantic decoder) are used to conduct effective visual-semantic interaction in a visual-semantic embedding network.
-
(ACMMM 2021) [💬Video Background Music Generation] Video Background Music Generation with Controllable Music Transformer, Shangzhe Di et al. [Paper]
🌱 This paper establish the rhythmic relationships between video and background music, which connect timing, motion speed, and motion saliency from video with beat, simu-note density, and simu-note strength from music.
-
(ACMMM 2021) [💬Geometry and Illumination Distortion Recovery for Document Images] DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction, Hao Feng et al. [Paper]
📌 The first research of geometry and illumination distortion of document images based on transformer.- 🚀 SOTA on several datasets (doc3D, DocUNet) for document image reflection task.
🌱 Document Image Transformer (DocTr): A geometric unwarping transformer (captures the global context of the document image by self-attention mechanism and decodes the pixel-wise displacement solution to correct the geometric distortion) and an illumination correction transformer (removes the shading artifacts).
-
(arXiv preprint 2021) [💬Face Landmark Localization] LOTR: Face Landmark Localization Using Localization Transformer, Ukrit Watchareeruetai et al. [Paper]
📌 The first research of Transformers in direct regression of landmarks.🌱 Localization Transformer (LOTR): a direct coordinate regression approach leveraging a Transformer network to better utilize the spatial information in the feature map.🌱 Trained end-to-end without requiring any post-processing steps.
-
(ICCV 2021) [💬Object Re-Identification] TransReID: Transformer-based Object Re-Identification, Shuting He et al. [Paper] [Code]
📌 The first pure Transformer-based re-identification (ReID) research.🌱 TransReID: encode an image as a sequence of patches and build a transformer-based strong baseline with a few critical improvements.
-
(ICCV 2021) [💬Action Detection] OadTR: Online Action Detection with Transformers, Xiang Wang et al. [Paper] [Code]
🌱 OadTR: The encoder attached with a task token aims to capture the relationships and global interactions between historical observations. The decoder extracts auxiliary information by aggregating anticipated future clip representations.
-
(arXiv preprint 2021) [💬Image Style Transfer] StyTr^2: Unbiased Image Style Transfer with Transformers, Yingying Deng et al. [Paper] [Code]
🌱 StyTr^2: two different transformer encoders to generate domain-specific sequences for content and style.
-
(arXiv preprint 2021) [💬Hyperspectral Image Super-Resolution] Fusformer: A Transformer-based Fusion Approach for Hyperspectral Image Super-resolution, Jin-Fan Hu et al. [Paper]
🌱 Fusformer: a transformer-based network for fusing the low-resolution hyperspectral images and high-resolution multispectral images to obtain the high-resolution hyperspectral images.📌 The first time using the transformer to solve the hyperspectral image super-resolution problem. The self-attention mechanism in the transformer can represent more global information than previous CNN architectures.
-
(ICCV 2021) [💬3D Human Texture Estimation] 3D Human Texture Estimation from a Single Image with Transformers, Xiangyu Xu et al. [Paper] [Code] [Project]
🌱 Effectively exploit the global information of the input image.🌱 Mask-fusion strategy: combine the advantages of the RGB-based and texture-flow-based models.
-
(ICCV 2021) [💬Image Quality Assessment] MUSIQ: Multi-scale Image Quality Transformer, Junjie Ke et al. [Paper] [Code]
-
(arXiv preprint 2021) [💬Light Field Image Super-Resolution] Light Field Image Super-Resolution with Transformers, Zhengyu Liang et al. [Paper] [Code]
🌱 Angular Transformer: incorporate complementary information among different views.🌱 Spatial Transformer: capture both local and long-range dependencies within each sub-aperture image.📌 First attempt to adapt Transformers to Light Field(LF) image processing and propose a Transformer-based network for Light Field(LF) image Super-Resolution(SR).
-
(ACMMM 2021) [💬Structured Text Understanding] StrucTexT: Structured Text Understanding with Multi-Modal Transformers, Yulin Li et al. [Paper]
🌱 StrucTexT: a unified framework with a segment-token aligned encoder to deal with the entity labeling and entity linking tasks at different levels of granularity.🌱 StrucTexT uses the existing Masked Visual Language Modeling task and the new Sentence Length Prediction and Paired Boxes Direction tasks to incorporate the multi-modal information across text, image, and layout.
-
(arXiv preprint 2021) [💬Blind Face Inpainting] FT-TDR: Frequency-guided Transformer and Top-Down Refinement Network for Blind Face Inpainting, Junke Wang et al. [Paper]
🌱 Frequency-guided Transformer and Top-Down Refinement Network (FT-TDR): a novel two-stage blind face inpainting method.🌱 (1) Transformer-based network: detect the corrupted regions to be inpainted as masks by modeling the relation among different patches; (2) Top-down refinement network: hierarchically restore features at different levels and generate contents that are semantically consistent with the unmasked face regions.
-
(ICCV 2021) [💬Neural Painting] Paint Transformer: Feed Forward Neural Painting with Stroke Prediction, Songhua Liu et al. [Paper] [Code]
🌱 Paint Transformer: predict the parameters of a stroke set with a feed-forward network, which can generate a set of strokes in parallel and obtain the final painting of size 512×512 in near real-time.🌱 Paint Transformer proposed with a self-training pipeline that can be trained without any off-the-shelf dataset while still achieving excellent generalization capability.
-
(arXiv preprint 2021) [💬Computer-Aided Design] Computer-Aided Design as Language, Yaroslav Ganin et al. [Paper] [Code]
🌱 A machine learning model capable of automatically generating such sketches.🌱 A combination of a general-purpose language modeling technique alongside an off-the-shelf data serialization protocol.
-
(MICCAI 2021) [💬Automatic Surgical Instruction Generation] Surgical Instruction Generation with Transformers, Jinglu Zhang et al. [Paper]
🌱 A transformer-backboned encoder-decoder network with self-critical reinforcement learning to generate instructions from surgical images.
-
(arXiv preprint 2021) [💬Quadrupedal Locomotion] Learning Vision-Guided Quadrupedal Locomotion End-to-End with Cross-Modal Transformers, Ruihan Yang et al. [Paper] [Project]
🌱 Proprioceptive states only offer contact measurements for immediate reaction, whereas an agent equipped with visual sensory observations can learn to proactively maneuver environments with obstacles and uneven terrain by anticipating changes in the environment many steps ahead.🌱 LocoTransformer: an end-to-end Reinforcement Learning (RL) method for quadrupedal locomotion that leverages a Transformer-based model for fusing proprioceptive states and visual observations.
-
(arXiv preprint 2021) [💬Document Understanding] DocFormer: End-to-End Transformer for Document Understanding, Srikar Appalaraju et al. [Paper]
🌱 DocFormer uses text, vision and spatial features and combines them using a novel multi-modal self-attention layer.🌱 DocFormer also shares learned spatial embeddings across modalities which makes it easy for the model to correlate text to visual tokens and vice versa.
-
(arXiv preprint 2021) [💬Graph Representation] Do Transformers Really Perform Bad for Graph Representation?, Chengxuan Ying et al. [Paper] [Technical report] [Code]
- 🚀 1st place of PCQM4M-LSC Track @ KDD Cup 2021 OGB Large-Scale Challenge
🌱 Utilizing Transformer in the graph is the necessity of effectively encoding the structural information of a graph into the model.🌱 Proposed several simple yet effective structural encoding methods to help Graphormer better model graph-structured data.
-
(arXiv preprint 2021) [💬Image Captioning] Semi-Autoregressive Transformer for Image Captioning, Yuanen Zhou et al. [Paper] [Code]
🌱 A semi-autoregressive model for image captioning, which keeps the autoregressive property in global but generates words parallelly in local.
-
(arXiv preprint 2021) [💬Image Colourising] ViT-Inception-GAN for Image Colourising, Tejas Bana et al. [Paper]
🌱 Adopt an Inception-v3 fusion embedding in the generator and Vision Transformer (ViT) as the discriminator.
-
(arXiv preprint 2021) [💬Multiple instance learning (MIL)] TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classication, Zhuchen Shao et al. [Paper]
🌱 Transformer based MIL (TransMIL): effectively deal with unbalanced/balanced and binary/multiple classification with great visualization and interpretability.
-
(arXiv preprint 2021) [💬Human Action Recognition] STAR: Sparse Transformer-based Action Recognition, Feng Shi et al. [Paper]
🌱 Sparse Transformer-based Action Recognition (STAR): a novel skeleton-based human action recognition model with sparse attention on the spatial dimension and segmented linear attention on the temporal dimension of data.🌱 5∼7× smaller than the baseline models while providing 4∼18× execution speedup.
-
(CVPR 2021) [💬Human-Object Interaction Detection] HOTR: End-to-End Human-Object Interaction Detection with Transformers, Bumsoo Kim et al. [Paper]
🌱 A novel framework that directly predicts a set of human, object, interaction triplets from an image based on a transformer encoder-decoder architecture.
-
(CVPR 2021) [💬Human-Object Interaction Detection] End-to-End Human Object Interaction Detection with HOI Transformer, Cheng Zou et al. [Paper] [Code]
🌱 Discuss the relations of objects and humans from global image context and directly predicts Human-Object Interaction(HOI) instances in parallel.
-
(arXiv preprint 2021) [💬Robust Classification] Vision Transformers are Robust Learners, Sayak Paul et al. [Paper] [Code]
🌱 Provide novel insights for robustness attribution of ViT.🌱 According to robustness to masking, energy and loss landscape analysis, and sensitivity to high-frequency artifacts to reason about the improved robustness of ViTs.
-
(CVPR 2021) [💬Human Pose and Mesh Reconstruction ] End-to-End Human Pose and Mesh Reconstruction with Transformers, Kevin Lin et al. [Paper]
-
(arXiv preprint 2021) [💬Traffic Scenario Infrastructures] Novelty Detection and Analysis of Traffic Scenario Infrastructures in the Latent Space of a Vision Transformer-Based Triplet Autoencoder, Jonas Wurst et al. [Paper] [Code]
🌱 Triplet Training
-
(arXiv preprint 2021) [💬Scene Text Recognition] I2C2W: Image-to-Character-to-Word Transformers for Accurate Scene Text Recognition, Chuhui Xue et al. [Paper]
🌱 A novel scene text recognizer that is tolerant to complex background clutters and severe geometric distortions.🌱 End-to-end trainable🌱 Transformer based scene text recognition, I2C2W contains image-to-character module (I2C) and a character-to-word module (C2W) which are complementary.
-
(arXiv preprint 2021) [💬Handwritten Recognition] Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer, Wenqi Zhao et al. [Paper] [Code]
🌱 Handwritten Mathematical Expression Recognition
-
(arXiv preprint 2021) [💬Scene Flow Estimation] SCTN: Sparse Convolution-Transformer Network for Scene Flow Estimation, Bing Li et al. [Paper]
📌 The first Sparse Convolution-Transformer Network (SCTN) for scene flow estimation.
-
(arXiv preprint 2021) [💬Image Registration] Attention for Image Registration (AiR): an unsupervised Transformer approach, Zihao Wang et al. [Paper]
📌 The first Transformer based image unsupervised registration method.🌱 A multi-scale attention parallel Transformer framework.
-
(arXiv preprint 2021) [💬Action Recognition] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text, Hassan Akbari et al. [Paper]
🌱 Convolution-free🌱 Multimodal representation- 🚀 SOTA on Moments in Time
-
(arXiv preprint 2021) [💬Action Recognition] An Image is Worth 16x16 Words, What is a Video Worth?, Gilad Sharir et al. [Paper] [Code]
🌱 Achieves 78.8 top1-accuracy with ×40 faster inference time on Kinetics-400 benchmark.🌱 End-to-end trainable
-
(arXiv preprint 2021) [💬Video Prediction] Local Frequency Domain Transformer Networks for Video Prediction, Hafez Farazi et al. [Paper] [Code]
📌 The first pure Transformer-based U-shaped architecture .🌱 Lightweight and flexible, enabling use as a building block at the core of sophisticated video prediction systems.
-
(arXiv preprint 2021) [💬Text Recognition] Vision Transformer for Fast and Efficient Scene Text Recognition, Rowel Atienza et al. [Paper] [Code]
🌱 Transformer based scene text recognition, maximize accuracy, speed and computational efficiency all at the same time.
-
(arXiv preprint 2021) [💬Gaze Estimation] Gaze Estimation using Transformer, Yihua Cheng et al. [Paper] [Code]
🌱 Pure and hybrid transformer for gazing direction estimation
-
(arXiv preprint 2021) [💬Image-to-Image Translation] MixerGAN: An MLP-Based Architecture for Unpaired Image-to-Image Translation, George Cazenavette et al. [Paper]
🌱 MLP self-attention based image-to-image translation GAN
-
(arXiv preprint 2021) [💬Single Image Deraining] Sdnet: Multi-Branch For Single Image Deraining Using Swin, Fuxiang Tan et al. [Paper] [Code]
🌱 Swin-transformer based deraining task.
-
-
Beyond Transformer «🎯Back To Top»
- (arXiv preprint 2021) Container: Context Aggregation Network, Peng Gao et al. [Paper]
🌱 A unified view of popular architectures for visual inputs – CNN, Transformer and MLP-mixer.🌱 A novel network block – CONTAINER, which uses a mix of static and dynamic affinity matrices via learnable parameters.- 📚 Image Classification, Object Detection, Instance Segmentation, Self-Supervised Representation Learning
- (arXiv preprint 2021) Less is More: Pay Less Attention in Vision Transformers, Zizheng Pan et al. [Paper]
🌱 Less attention vision Transformer (LIT): Pure multi-layer perceptrons (MLPs) encode rich local patterns in the early stages; Self-attention modules capture longer dependencies in deeper layers.🌱 Propose a learned deformable token merging module to adaptively fuse informative patches in a non-uniform manner.- 📚 Image Classification, Object Detection, Instance Segmentation
- (arXiv preprint 2021) Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks, Meng-Hao Guo et al. [Paper] [Code]
🌱 External Attention(EA): A novel attention mechanism based on two external, small, learnable, shared memories, which simply using two cascaded linear layers and two normalization layers.🌱 External Attention MLP (EAMLP): Incorporate the multi-head mechanism into external attention(EA) to provide an all-MLP architecture.- 📚 Image Classification, Object Detection, Semantic Segmentation, Instance Segmentation, Image Generation, Point Cloud Analysis
- (arXiv preprint 2021) An Attention Free Transformer, Shuangfei Zhai et al. [Paper] [Code]
🌱 Attention Free Transformer (AFT): the key and value are first combined with a set of learned position biases, the result multiplied with the query in an element-wise fashion.🌱 AFT-local & AFT-conv: take advantage of the idea of locality and spatial weight sharing while maintaining global connectivity.- 📚 Autoregressive Modeling (CIFAR10 and Enwik8), Image Recognition (ImageNet-1K classification)
- (arXiv preprint 2021) Pay Attention to MLPs, Hanxiao Liu et al. [Paper]
🌱 Attention-free🌱 A simple variant of MLPs with gating.🌱 Can be competitive with Transformers in terms of BERT’s pretraining perplexity, ViT’s accuracy, the scalability over increased data and compute.
- (arXiv preprint 2021) MLP-Mixer: An all-MLP Architecture for Vision, Ilya Tolstikhin et al. [Paper] [Code]
🌱 An architecture based exclusively on multi-layer perceptrons (MLPs).
- (arXiv preprint 2021) Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks, Meng-Hao Guo et al. [Paper] [Code]
🌱 Simply using two cascaded linear layers and two normalization layers.
- (arXiv preprint 2021) Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet, Luke Melas-Kyriazi. [Paper] [Code]
🌱 Replace the attention layer in a vision transformer with a feed-forward layer.
- (arXiv preprint 2021) RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition, Xiaohan Ding et al. [Paper] [Code]
🌱 Re-parameterizing Convolutions and MLP
- (arXiv preprint 2021) ResMLP: Feedforward networks for image classification with data-efficient training, Hugo Touvron et al. [Paper] [Code]
🌱 Residual MLP structure
- (arXiv preprint 2021) FNet: Mixing Tokens with Fourier Transforms, James Lee-Thorp et al. [Paper] [Code]
🌱 Unparameterized Fourier Transform replaced the self-attention sublayer in Transformer encoder
- (arXiv preprint 2021) Can Attention Enable MLPs To Catch Up With CNNs?, Meng-Hao Guo et al. [Paper]
🌱 Examine what the four newly proposed MLP self-attention architectures
- (arXiv preprint 2021) Container: Context Aggregation Network, Peng Gao et al. [Paper]




-
Yutong ZHOU in Interaction Laboratory, Ritsumeikan University. (づ ̄0 ̄)づ
-
If you have any question, please feel free to contact Yutong ZHOU (E-mail: zhou@i.ci.ritsumei.ac.jp).