Необходимо реализовать графическую утилиту с использованием WPF для анализа соотношения размера файлов и каталогов внутри выбранного каталога в многопоточном режиме
- Разработка программ с графическим интерфейсом (WPF).
- Разделение логики предметной области и представления данных в интерфейсе пользователя (MVVM).
- Многопоточное программирование.
- Работа с файловой системой.
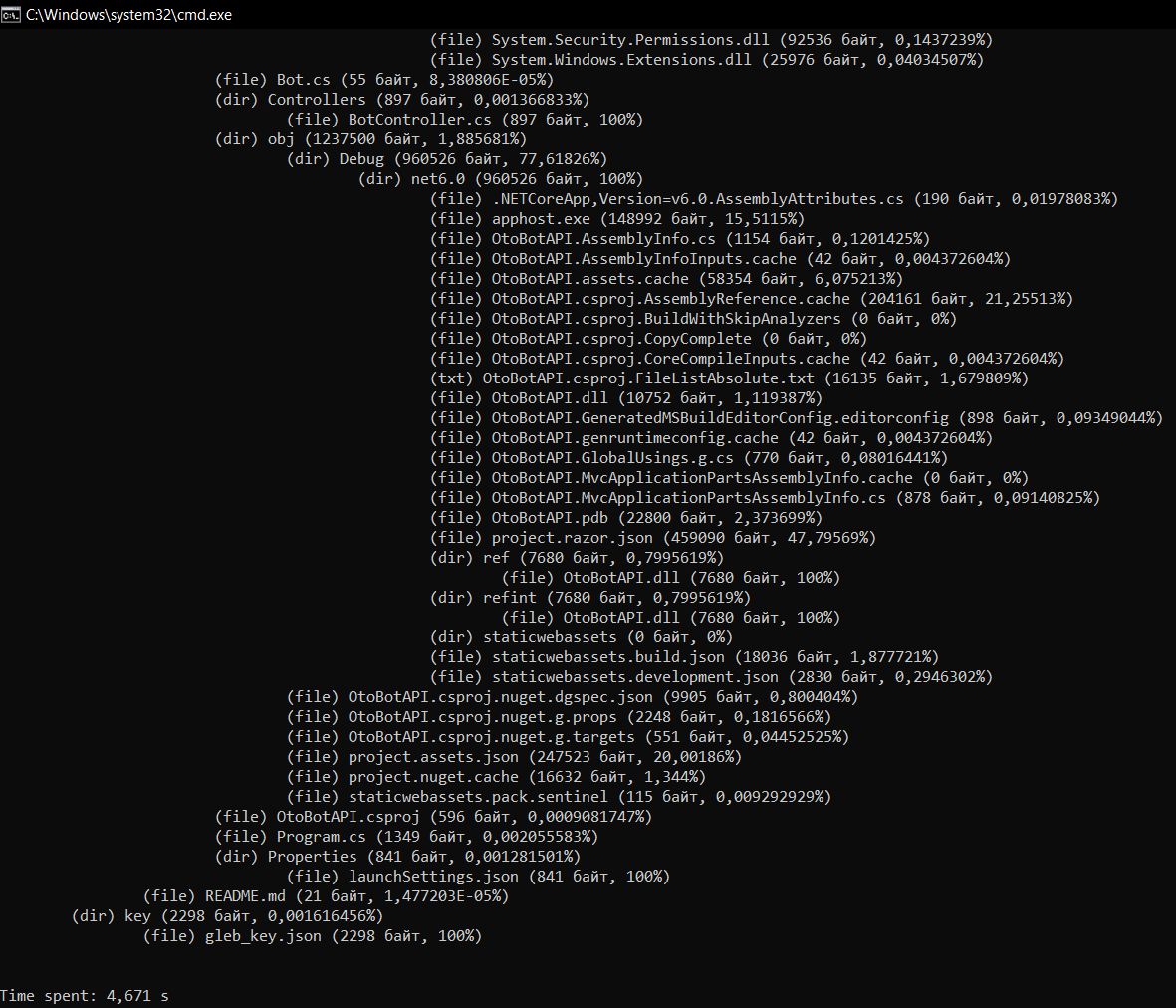
Содержимое загруженной папки (выбирается через стандартный диалог открытия папки) представлено в иерархическом виде (элемент управления TreeView), где для каждого элемента указан размер в байтах и процент занимаемого пространства относительно общего размера каталога, в котором находится элемент. Узлы, соответствующие папкам и файлам, имеют разные иконки (а именно директории, текстовые файлы и обычные документы файловой системы).
Также в программе реализована функция "отмены" сканирования (Казалось бы, можно было бы использовать cancellation token для преостановки работы всех обрабатывающих в данный момент файлы потоков, однако я сделал эту часть более интересно. О ней подробнее дальше). В результате, при нажатии кнопки "Отмена" в дереве результатов отображаются те сведения, которые были собраны к этому моменту.
- Анализ размера файлов и каталогов выполняется в
многопоточном режимес использованием системного пула потоковThreadPoolи очередиThreadPool.QueueUserWorkItem - Обработка каждого каталога выполняется в
отдельном потоке. Обработка включает в себясуммирование размеров вложенных файловипостановку в очередьвсех вложенных каталогов для аналогичной обработки. - Максимальное количество задействованных потоков ограничено передаваемым в функцию значением
numberOfThreadsToProceedбез изменения настроек системного пула потоков (использование ThreadPool.SetMaxThreads не предусматривалось).
static void CalculateSizeOfAllEntities(List<Entity> entities, bool isAsync = false, int numberOfThreadsToProceed = 0, int numberOfSystemThreads = 0)Поток, обрабатывающий каталог, не дожидается обработки всех вложенных каталогов, а только ставит их обработку в очередь. В противном случае при высоком уровне вложенности потоки бы простаивали впустую, дожидаясь завершения работы потоков, запущенных для вложенных каталогов. Также при установке ограничения количества задействованных потоков в значение, меньшее уровня вложенности каталогов в сканируемом каталоге, были бы возможны "зависания" программы из-за бесконечного ожидания (взаимной блокировки), когда все потоки заняты ожиданием завершения обхода вложенных каталогов, для запуска обработки которых потоков уже не остается. Решении этой проблемы я также расписал ниже.
Код лабораторной работы состоит из четырёх проектов:
Консольное приложение, с помощью которой можно оценить, на сколько изменится скорость выполнения сканирования при установке значения максимального количества одновременно запущенных потоков, а также сравнить синхронное и асинхронное сканирование. (ConsoleScanner)Библиотека, выполняющая сбор информации о каталоге и построение удобной для отображения структуры данных. (MyScannerLibrary)Модульные тестыдля главной библиотеки (Scanner.Tests)WPF-приложение, отображающее структуру каталогов (ScannerClient)

Для начала, расскажу как пользоваться клиентской частью (WPF), после чего о том, как менять значения в консольном режиме для оценивания скорости обработки каталогов и о принципе анализа вообщем.
При первом запуске, большая часть окна будет закрашена белым цветом, а справа будет виднеться меню для работы. При нажатии на кнопку Gauge Directory пользователю будет представлено диалоговое окно, в котором он должен будет выбрать папку для обработки. После подтверждения программа начнёт сканирование в многопоточном режиме (Константное значение, определяющее максимальное количество одновременно работающих потоков, в библиотеке для клиентской части определено как 7). При этом, пользователь в любой момент может нажать на соответствующую кнопку Stop Gauging, чем он произведёт посыл сигнала (более подробно читай ниже), после которого обработка файлов завершиться, и пользователю будут отображены только те файлы, которые успела обработать программа. Дальнейший анализ происходит аналогично.
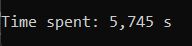
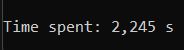
В консольной же части, помимо самой обработки файлов, программа осуществляет подсчёт времени, которое было затрачено на обработку, что позволяет отследить изменение при редактироовании числа максимально доступных потоков, а также для синхронной и асинхронной обработки. Ниже можно посмотреть время, затраченное для обработки одного и того же каталога, но с различными параметрами функции обработки:
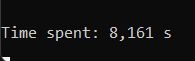
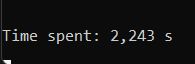
CalculateSizeOfAllEntities(entities); // Sync, 1 Thread
CalculateSizeOfAllEntities(entities, isAsync: true, numberOfThreadsToProceed: 5, numberOfSystemThreads: systemThreadsCount); // Async, 5 Threads
CalculateSizeOfAllEntities(entities, isAsync: true, numberOfThreadsToProceed: 10, numberOfSystemThreads: systemThreadsCount); // Async, 10 Threads
CalculateSizeOfAllEntities(entities, isAsync: true, numberOfThreadsToProceed: 20, numberOfSystemThreads: systemThreadsCount); // Async, 20 ThreadsУ не подготовленного программиста может возникнуть вопрос: А почему, при увеличении числа потоков с 5 -> 10 мы получили выигрыш по времени в целых 3.5 секунды, а при увеличении с 10 -> 20 в 0.002 секунды???
Ответ на этот вопрос довольно прост - При увеличении числа активных потоков, существует предельное значение, увеличении которого не будет приводить абсолютно ни к чему. Это связано с тем, что 10-ти потоков вполне достаточно, чтоб обрабатывать каталог и не тратить время на ожидание завершения других (ведь таким образом происходит наращивание общего времени выполнения). Таким образом, при обработке каталога в моей программе, предельное число оказалось где-то ~10 потоков. Дальнейшее увеличение этого числа никак не будет влиять на временной результат, так как в номера потоков свыше 10 (или около) никогда не попадут задачи на выполнение.
public class Entity
{
public FileSystemInfo Info { get; set; } // Системная информация о сущности
public string Name { get; set; } // Имя
public EntityType Type { get; set; } // Тип сущности
public DirectoryInfo SubDirecory { get; set; } // Каталог, в котором содержится сущность (null для головной)
public long? Size { get; set; } = null; // размер (в байтах)
public string Persantage { get; set; } = null; // размер (в процентах от всего содержимого каталога)
public Entity() { }
}Пройдёмся по каждому полю отдельно:
FileSystemInfo- Хранит всю системную информацию о сущности. Необходимо для подсчёта размера. В зависимости от значенияEntityType, это поле будет явно приводиться к типуDirectoryInfoдля каталогов и кFileInfoдля файлов.Name- Хранит имя файла / каталога.EntityType- Структура, хранящая информацию о типе сущности.DirectoryInfo- Хранит ссылку на выделенный в динамической памяти объект с информацией о директории, в которой содержится файл / каталог.Size- Размер файла / каталога.Persantage- Значение в процентах от размера головной директории
public enum EntityType
{
Directory = 1,
File = 2,
TextFile = 3
}Сначала, в функцию нам попадает только путь, по которому расположен каталог для анализа. Мы создаём инстанс с информацией о каталоге по переданному пути, и добавляем её в список Entities первым, как головной элемент. Далее, мы получаем список всех каталогов и файлов, хранящихся в головном каталоге, после чего передаём эти списки на обработку рекурсивной функции, которая проходится по каждому элементу, и, если это каталог, то для него запускается своя рекурсивная функция с обходом каталога вглубину, предварительно добавив этот каталог как сущность в список. Если же мы имеем дело с файлом - просто добавляем его и идём дальше. Таким образом, после выполнения функции, мы получили список всех сущностей, содержащихся в головном каталоге, вместе с графом этих объектов в виде списка сущностей. Далее, происходит анализ размера сущностей либо синхронно, либо асинхронно с использованием пула потоков и очереди.
CalculateSizeOfAllEntities(entities);Для синхронной обработки нам достаточно передать список сущностей, собранных на предыдущем шаге, после чего программа начнёт проход по списку, проверяя поле EntityType каждого элемента. В зависимости от того, с какой сущностью мы имеем дело, для них будут запускаться разные алгоритмы подсчёта размеров. Для каталога - обход вглубину и подсчёт размера, а для файлов - банальное получение их размера путём обращения к типу. Таким образом, будет выполнен проход для каждого файла и подсчёт размеров и процентного соотношения. Такой принцип обхода не требует за собой мониторинга "А что будет, если количество файлов в каталоге будет больше, чем число доступных для использования потоков???", так как такая исключительная ситуация впринципе не может произойти при использовании данного подхода.
CalculateSizeOfAllEntities(entities, isAsync: true, numberOfThreadsToProceed: 7, numberOfSystemThreads: systemThreadsCount);Для такой обработки, нужно передать ряд параметров:
entities- Тот же самый список сущностей, что и для синхронной обработкиisAsync- Флаг для указания, что мы хотим обработать сущности асинхронно (по умолчанию флагfalse)numberOfThreadsToProceed- Количество потоков для использования программой (задаётся программистом) (по умолчанию0)numberOfSystemThreads- Количество доступных системных потоков (предоставляется системой) (по умолчанию0)
Отличие асинхронной обработки от синхронной только в том, что был добавлен ещё один метод, в котором находится та же самая обработка сущностей, что и при синхронной обработке, + добавлены 2 проверки на контролирование числа активных потоков. Контроль осуществляется следующим образом: После того, как мы передали сущность на обработку в другой поток, мы получаем количество доступных в данный момент потоков (оно должно уменьшиться на 1 от первоначального), после чего сравниваем его с первоначальным числом доступных для использования системой потоков. Разность этих значений должна быть меньше числа, введённого пользователем как ограничение максимального числа активных потоков. Если получилось так, что свободных потоков больше не осталось, мы ждём 100 ms методом Thread.Sleep(100), после чего заново проверяем, освободился ли хотя бы 1 поток, чтоб передать ему следующую задачу. Таким образом в программе осуществлялся контроль за числом работающих в данный момент потоков.
Как и было сказано, я сделал эту часть интересным образом. В классе Program библиотеки вводиться статическая переменная isWorking, которая призвана хранить состояние, ведётся ли обработка в текущий момент или нет. Как только мы начинаем сканровать - значение true, как только закончили сканирование - false. Во всех остальных случаях это значение также false. Предположим, что пользователь решает прервать обработку. Он может напрямую обратиться к этой переменной и поменять это значение в false принудительно. Что это даёт? Перед тем, как запускать новый поток, программа проверяет, что это поле действительно равно true, и только после этого запускается очередной поток. Как только пользователь поменял значение, обращение к этой переменной будет давать значение false, что инициирует выход из цикла по активации новых потоков, после чего мы ждём окончания завершения текущих активных потоков 2-й проверкой, как было описано выше. Таким образом, мы получили результат, где в списке находятся как обработанные, так и не обработанные сущности. Мы выкидывает из списка те сущности, для которых значение размера null, после чего возвращаем список обработанных к текущему моменту времени сущностей. Таким образом, производилось прерывание, основываясь на том принципе, что статическая перемнная - единственная в своём экземпляре, и что её изменение увидят все активные потоки, обрабатывающие каталоги в данный момент времени.
Таким образом, было разработано приложение, способное анализировать и высчитывать размер каталога вместе со всеми вложенными файлами, а также предоставлять возможность выбора пользователю, производить расчёт в синхронном или асинхронном режиме.