This project aims to implement different methods of sampling, camparing Exact Inference and Approximate Inference.
Exact Inference and Approximate Inference are two methods used in probabilistic graphical models to compute the posterior distribution of a set of variables given some evidence.
-
Exact Inference: Exact inference computes the exact posterior distribution. This is typically done using algorithms like Variable Elimination, Belief Propagation, or Junction Tree Algorithm. These methods are very efficient for certain types of graphical models, such as trees or singly connected graphs. However, for models with high treewidth (i.e., models that are highly interconnected), exact inference can be computationally infeasible, as the time complexity is exponential in the treewidth of the graph.
-
Approximate Inference: Approximate inference methods are used when exact inference is computationally infeasible. These methods provide an approximation to the true posterior distribution. There are two main types of approximate inference methods:
-
Sampling Methods (Stochastic): These methods generate samples from the posterior distribution. Examples include Markov chain Monte Carlo (MCMC) methods like Gibbs Sampling, Metropolis-Hastings, etc.
-
Deterministic Methods: These methods approximate the posterior distribution directly. Examples include Variational Inference, Loopy Belief Propagation, etc.
-
Here we are given the following Bayesian Network and we would like to calculate some probabilities, that are refered to as Queries.

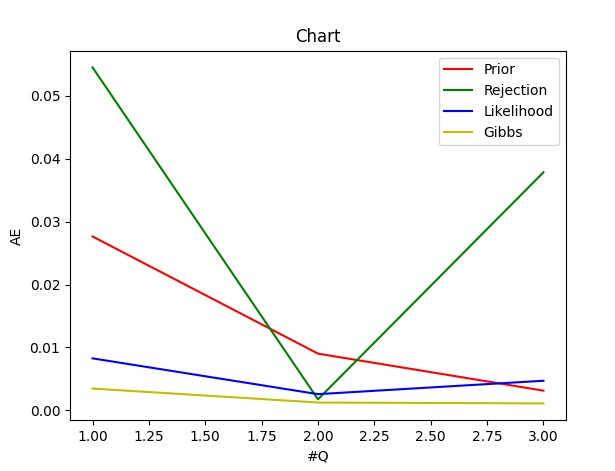
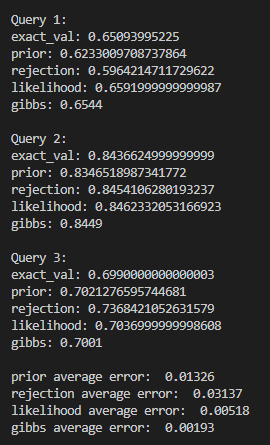
The result and the error of each sampling (Prior Sampling, Rejection Sampling, Likelihood Sampling and Gibbs Sampling) are as follows:
- Install python Here
In this project, there are four different samplings used to find the probabilities of queries.
Here's a breakdown of the code:
the common structure of sampling implementation:
-
query: The variable(s) for which we want to compute the posterior distribution.
-
evidence: The observed variables and their values.
-
cpts: The conditional probability tables (CPTs) for the variables in the graph.
-
graph: The graph structure, which includes information about the parent nodes of each variable.
exact_inference:
-
It initializes an empty list new_cpts to store the updated CPTs after incorporating the evidence.
-
It retrieves the parent nodes for each variable from the graph.
-
It iterates over each CPT. For each CPT, it creates an empty list tb.
-
For each row in the CPT, it checks if the variable corresponding to the CPT is in the evidence. If it is, and the value in the row doesn't match the evidence, it skips this row.
-
It then checks if all the parent variables of the current variable match the evidence. If they do, it adds the row to tb.
-
After iterating over all rows in the CPT, it adds tb to new_cpts.
-
Finally, it calls the variable_elimination function with the evidence, the query, and the updated CPTs, and returns the result.
prior_sample:
-
It sorts the vertices of the graph in topological order.
-
It initializes an empty list samples to store the generated samples.
-
It generates globals.num_samples(10000) samples. For each sample, it initializes a dictionary where each vertex is mapped to -1. Then, it samples a value for each vertex using the sample_vertex function and the current sample, and stores it in the sample dictionary. It adds the sample to the samples list.
-
It initializes two counters, consistent_with_evidence and query_evidence_true.
-
It iterates over each sample. For each sample, it checks if the sample is consistent with the evidence. If it is, it increments consistent_with_evidence. It then checks if the sample is consistent with the query. If it is, it increments query_evidence_true.
-
If consistent_with_evidence is 0, it returns 0 to avoid division by zero.
-
Finally, it returns the ratio of query_evidence_true to consistent_with_evidence. This is an estimate of the probability of the query given the evidence.
rejection_sample:
-
It sorts the vertices of the graph in topological order.
-
It initializes an empty list samples to store the generated samples and a counter consistent_with_evidence.
-
It generates globals.num_samples(10000) samples. For each sample, it initializes a dictionary where each vertex is mapped to -1. Then, it samples a value for each vertex using the sample_vertex function and the current sample. If the vertex is in the evidence and its sampled value doesn't match the evidence, it rejects the sample and continues to the next one.
-
If the sample is not rejected, it increments consistent_with_evidence and adds the sample to the samples list.
-
It initializes a counter query_evidence_true.
-
It iterates over each sample. For each sample, it checks if the sample is consistent with the query. If it is, it increments query_evidence_true.
-
If consistent_with_evidence is 0, it returns 0 to avoid division by zero.
-
Finally, it returns the ratio of query_evidence_true to consistent_with_evidence. This is an estimate of the probability of the query given the evidence.
likelihood_sample:
-
It sorts the vertices of the graph in topological order.
-
It initializes three empty lists samples, weights_all, and weights_query to store the generated samples and their weights.
-
It generates globals.num_samples(10000) samples. For each sample, it initializes a dictionary where each vertex is mapped to -1. Then, it iterates over each vertex. If the vertex is in the evidence, it sets its value to the observed value and multiplies the weight of the sample by the probability of the observed value given the parents' values in the sample. If the vertex is not in the evidence, it samples a value for the vertex.
-
It checks if the sample is consistent with the query. If it is, it adds the weight of the sample to weights_query.
-
It adds the weight of the sample to weights_all and the sample to samples.
-
If the sum of weights_all is 0, it returns 0 to avoid division by zero.
-
Finally, it returns the ratio of the sum of weights_query to the sum of weights_all. This is an estimate of the probability of the query given the evidence.
gibbs_sample:
-
It sorts the vertices of the graph in topological order.
-
It initializes an empty list samples to store the generated samples.
-
It generates globals.num_samples(10000) samples. For each sample, it initializes a dictionary where each vertex is mapped to -1. Then, it sets the value of each vertex in the evidence to the observed value and samples a value for each vertex not in the evidence.
-
It performs a Gibbs sampling step for each sample. For each vertex not in the evidence, it computes the conditional probability of the vertex given the rest of the variables in the sample, and samples a new value for the vertex from this conditional distribution.
-
It adds the sample to the samples list.
-
It initializes a counter query_satisfied.
-
It iterates over each sample. For each sample, it checks if the sample is consistent with the query. If it is, it increments query_satisfied.
-
Finally, it returns the ratio of query_satisfied to globals.num_samples. This is an estimate of the probability of the query given the evidence.
Distributed under the MIT License.
This code is provided by ErfanXH and all rights are reserved.
Project Link: https://github.com/ErfanXH/Sampling