Pytorch to train ENet of Cityscapes datasets and CamVid datasets nicely

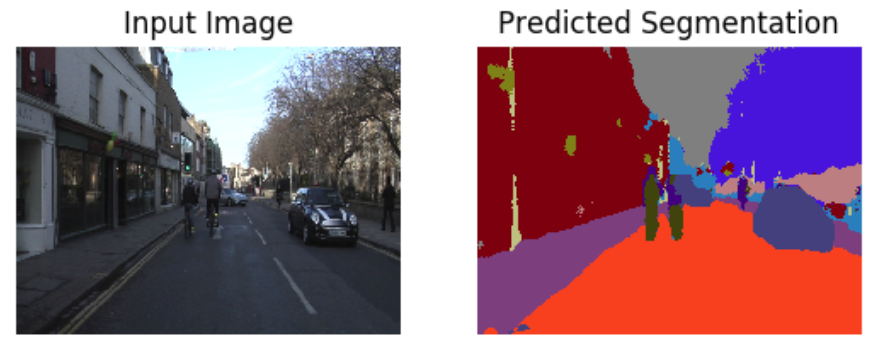
The most important thing is that do not use interpolation method to resize the label image during the training. Because label image will be inserted with the wrong label even though nearest neighbor interpolation. You can print to see each pixel of label image after resized.
I have implemented a fast scaled downsampling method in C++. It can reduce label image in proportion without inserting wrong label. Run the command ./datasets/Cityscapes/scaleDownSampling/scaleDownSampling help will print the parameter guide:
please enter 8 parameter
argv[1]: Original cityscapes datasets txt file
argv[2]: Path to Original cityscapes datasets
argv[3]: New txt file of the resized cityscapes datasets
argv[4]: Path to the resized cityscapes datasets
argv[5]: Image x-axis reduction ratio
argv[6]: Image y-axis reduction ratio
argv[7]: Label x-axis reduction ratio
argv[8]: Label y-axis reduction ratio
pytorch1.x
python3.6
opencv
Please download the fine labeled Cityscapes dataset leftImg8bit_trainvaltest.zip (11GB) and the corresponding ground truth gtFine_trainvaltest.zip (241MB) from the Cityscapes website and unzip in ./datasets/Cityscapes/. In addition, clone the cityscapesScripts repository:
$ git clone https://github.com/mcordts/cityscapesScripts.git
After that, run the /preparation/createTrainIdLabelImags.py script, to convert annotations in polygonal format to png images with label IDs, where pixels encode "train IDs" (that you can define in labels.py). Since we use the default 19 classes, you do not need to change anything in the labels.py script. The input data layer which is used requires a text file of white-space separated paths to the images and the corresponding ground truth.
Second to run the /Pytorch-ENet-Nice/datasets/Cityscapes/makepairs.py script directly to generate original cityscapes datasets txt file in the ./datasets/Cityscapes/.
train_cityscapes.txt
val_cityscapes.txt
Finaly use the executable filePytorch-ENet-Nice/datasets/Cityscapes/scaleDownSampling/scaleDownSampling to generate new cityscapes datasets of size 1024*512 and new txt file. Need to pay attention here, you should pre-create the directory folder in the Pytorch-ENet-Nice/datasets/Cityscapes/scaleDownSampling/ like that:
- Cityscapes
- leftImg8bit
- train
- val
- gtFine
- train
- val
- leftImg8bit
After that, you should cd ./datasets/Cityscapes/scaleDownSampling/, and generate training data of size 1024*512 to encoder-decoder architecture:
./scaleDownSampling ../train_cityscapes.txt ../.. Cityscapes/scale_train_cityscapes.txt Cityscapes 0.5 0.5 0.5 0.5
./scaleDownSampling ../val_cityscapes.txt ../.. Cityscapes/scale_val_cityscapes.txt Cityscapes 0.5 0.5 0.5 0.5
if you want to train encoder architecture only, then you can run :
./scaleDownSampling ../train_cityscapes.txt ../.. encoder_Cityscapes/encoder_train_cityscapes.txt encoder_Cityscapes 0.5 0.5 0.0625 0.0625
./scaleDownSampling ../val_cityscapes.txt ../.. encoder_Cityscapes/encoder_val_cityscapes.txt encoder_Cityscapes 0.5 0.5 0.0625 0.0625
!!! Strongly recommended to pre-generate data to accelerated training !!!
models will save in logs, you should pre-create the directory folder as Pytorch-ENet-Nice/logs
python3 init.py --mode train --cuda=True --num-classes=19 --input-path-train=./datasets/Cityscapes/scaleDownSampling/encoder_Cityscapes/encoder_train_cityscapes.txt --input-path-val=./datasets/Cityscapes/scaleDownSampling/encoder_Cityscapes/encoder_val_cityscapes.txt --cityscapes_path=./datasets/Cityscapes/scaleDownSampling --train_mode=encoder
if you have trained ENet-encoder architecture, run this command:
python3 init.py --mode train --cuda=True --num-classes=19 --input-path-train=./datasets/Cityscapes/scaleDownSampling/Cityscapes/scale_train_cityscapes.txt --input-path-val=./datasets/Cityscapes/scaleDownSampling/Cityscapes/scale_val_cityscapes.txt --cityscapes_path=./datasets/Cityscapes/scaleDownSampling --pretrain_model=./logs/ckpt-enet_encoder-xx-xx-xx.pth
else:
python3 init.py --mode train --cuda=True --num-classes=19 --input-path-train=./datasets/Cityscapes/scaleDownSampling/Cityscapes/scale_train_cityscapes.txt --input-path-val=./datasets/Cityscapes/scaleDownSampling/Cityscapes/scale_val_cityscapes.txt --cityscapes_path=./datasets/Cityscapes/scaleDownSampling
CamVid datasets is already save in Pytorch-ENet-Nice/datasets/CamVid/,use size 480*360 of CamVid datasets to train ENet.
models will save in logs, you should pre-create the directory folder as Pytorch-ENet-Nice/logs
python3 init.py --mode train --cuda=True --train_mode=encoder
if you have trained ENet-encoder architecture, run this command:
python3 init.py --mode train --cuda=True --pretrain_model=./logs/ckpt-enet_encoder-xx-xx-xx.pth
else:
python3 init.py --mode train --cuda=True
Cityscapes model and CamVid model is open source and save in the test directory.
You can find the pretrained model in Pytorch-ENet-Nice/test/cityscapes_model/, then run:
python3 init.py --mode test --num-classes=19 --cuda=True -m=./test/cityscapes_model/ckpt-enet-134-1.25e-06-96.66597379744053.pth -i=./test/munich_000000_000019_leftImg8bit.png
You can find the pretrained model in Pytorch-ENet-Nice/test/camvid_model/, then run:
python3 init.py --mode test --cuda=True -m=./test/camvid_model/ckpt-enet-198-3.0517578125e-07-9.757900461554527.pth -i=./test/0016E5_07961.png --resize-height=480 --resize-width=360 --test_mode=camvid
-
You can take a fixed class weight of datasets if you want to resume training sometime. This can save a lot of time. I have calculated the weight of cityscapes datasets of size
1024*512:class_weights = np.array([3.03507951, 13.09507946, 4.54913664, 37.64795738, 35.78537802, 31.50943831, 45.88744201, 39.936759, 6.05101481, 31.85754823, 16.92219283, 32.07766734, 47.35907214, 11.34163794, 44.31105748, 45.81085476, 45.67260936, 48.3493813, 42.02189188])If you don't want to calculate the weight again, you should modify the 35-40 line of code in
train.pylike this:if len(cityscapes_path): #pipe = loader_cityscapes(ip, cityscapes_path, batch_size='all') #class_weights = get_class_weights(pipe, nc, isCityscapes=True) class_weights = np.array([3.03507951, 13.09507946, 4.54913664, 37.64795738, 35.78537802, 31.50943831, 45.88744201, 39.936759, 6.05101481, 31.85754823, 16.92219283, 32.07766734, 47.35907214, 11.34163794, 44.31105748, 45.81085476, 45.67260936, 48.3493813, 42.02189188])
-
If you training converges, you can choose the model with the least error and properly improve the learning rate to retrain. Maybe you can get a lower error model. If you want to resume training, you should add the training parameter:
--resume_model_path path/to/your/least/error/model -
Use the method
torch.optim.lr_scheduler.ReduceLROnPlateauto adaptively control the learning rate reduction. Reduce learning rate when a metric has stopped improving.scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode="min", factor=0.5, patience=2, verbose=True, threshold=0.01)when the error in the later period changes little, you should change the threshold value to 0.005 or smaller and resume training. Maybe you can get a lower error model.