Train double-jointed arms to reach target locations using Proximal Policy Optimization (PPO) in Pytorch

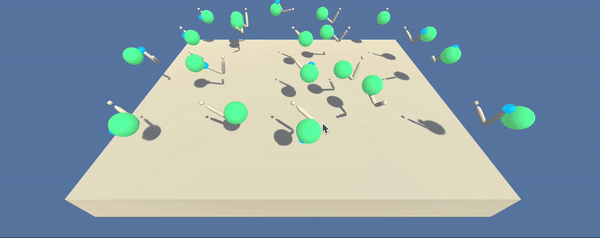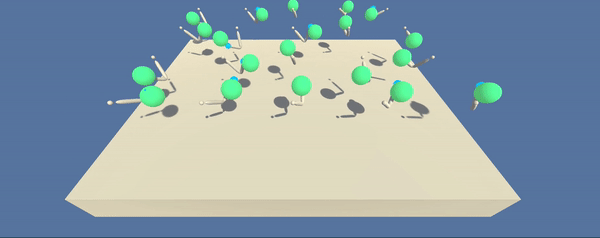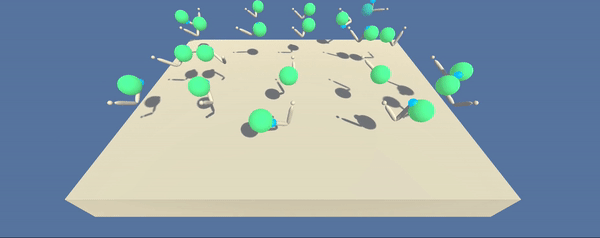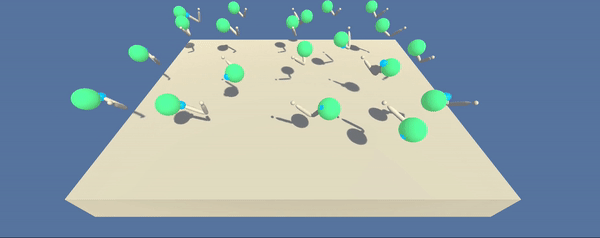
- Set-up: Double-jointed arm which can move to target locations.
- Goal: The agents must move it's hand to the goal location, and keep it there.
- Agents: The environment contains 10 agent linked to a single Brain.
- Agent Reward Function (independent):
- +0.1 Each step agent's hand is in goal location.
- Brains: One Brain with the following observation/action space.
- Vector Observation space: 26 variables corresponding to position, rotation, velocity, and angular velocities of the two arm Rigidbodies.
- Vector Action space: (Continuous) Size of 4, corresponding to torque applicable to two joints.
- Visual Observations: None.
- Reset Parameters: Two, corresponding to goal size, and goal movement speed.
- Benchmark Mean Reward: 30
The project was built with the following configuration:
- Ubuntu 16.04
- CUDA 10.0
- CUDNN 7.4
- Python 3.6 (currently ml-agents unity package does not work with python=3.7)
- Pytorch 1.0
Though not tested, the project can still be expected to work out of the box for most reasonably deviant configurations.
- Create separate virtual environment for the project using the provided
environment.ymlfile
conda env create -f environment.yml
conda activate reacher
- Clone the repository (if you haven't already!)
git clone https://github.com/1jsingh/rl_reacher.git
cd rl_reacher-
Download the environment from one of the links below. You need only select the environment that matches your operating system:
- Linux: click here
- Mac OSX: click here
(For AWS) If you'd like to train the agent on AWS (and have not enabled a virtual screen), then please use this link to obtain the "headless" version of the environment. You will not be able to watch the agent without enabling a virtual screen, but you will be able to train the agent. (To watch the agent, you should follow the instructions to enable a virtual screen, and then download the environment for the Linux operating system above.)
-
Place the downloaded file in the
unity_envsdirectory and unzip it.
mkdir unity_envs && cd unity_envs
unzip Reacher_Linux.zip
- Follow along with
Reacher-ppo.ipynborReacher-ddpg.ipynbto train your own RL agent.
model.py: code for actor and critic classddpg.py: DDPG agent with experience replay and OU NoiseReacher-ppo.ipynb: notebook for training PPO based RL agentReacher-ddpg.ipynb: notebook for training DDPG based RL agentunity_envs: directory for Reacher unity environmentstrained_models: directory for saving trained RL agent models
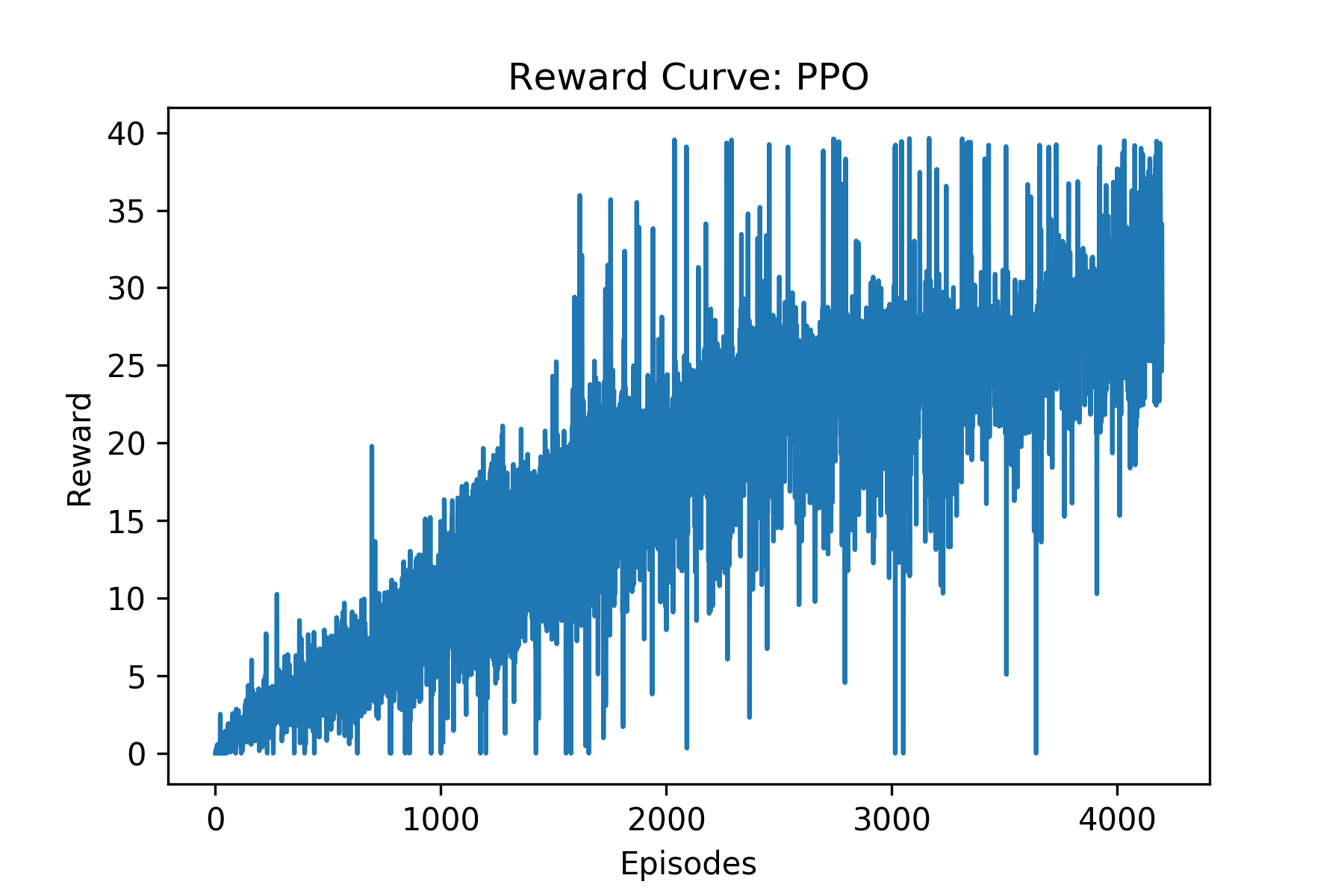
- PPO agent
- DDPG agent
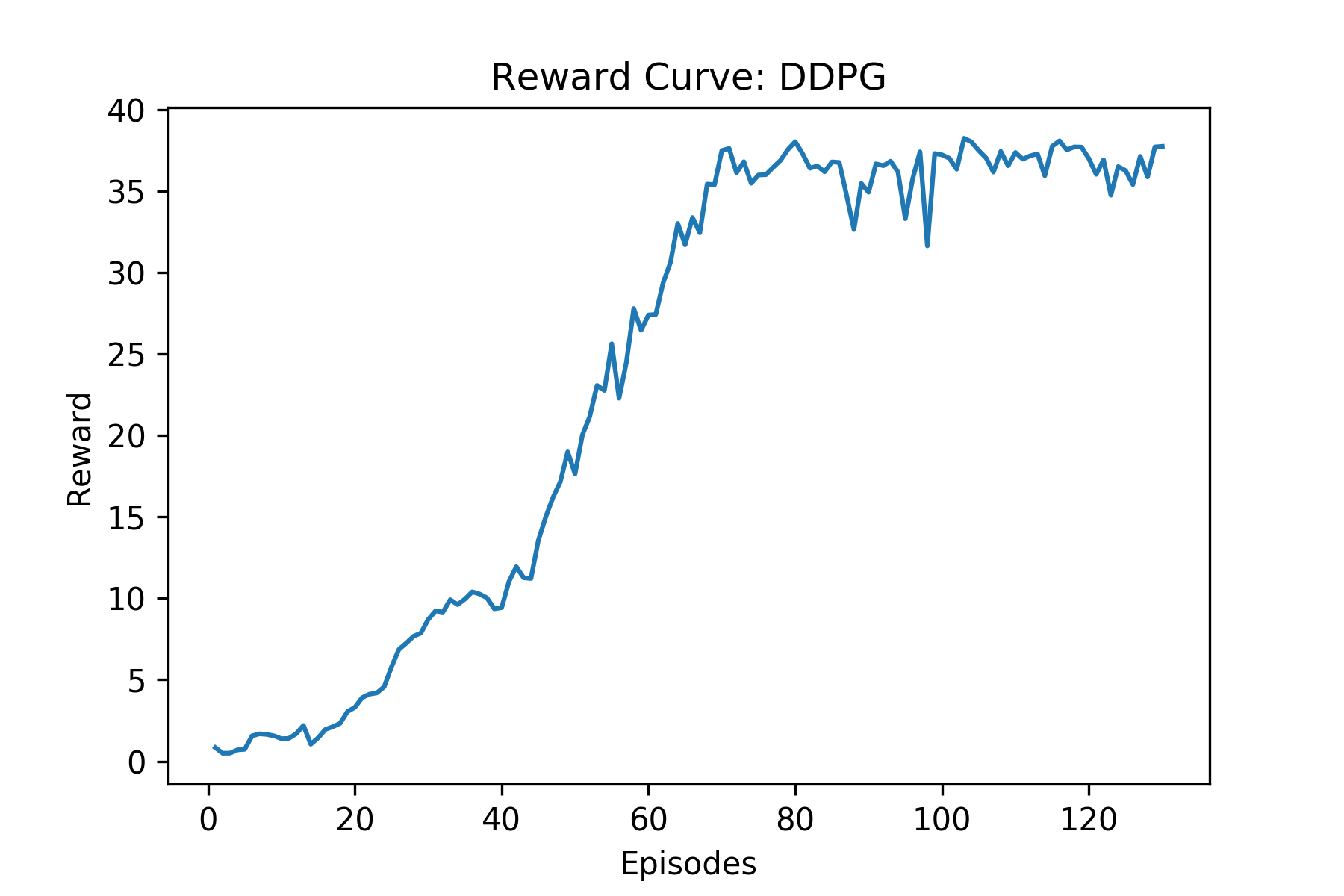


Note: DDPG has higher sample efficiency than PPO
The environment consists of 20 parallel agents which is useful for algorithms like PPO, A3C, and D4PG that use multiple (non-interacting, parallel) copies of the same agent to distribute the task of gathering experience.