This repository contains the official implementation of the following papers:
-
CoTNet Contextual transformer networks for visual recognition, TPAMI 2022
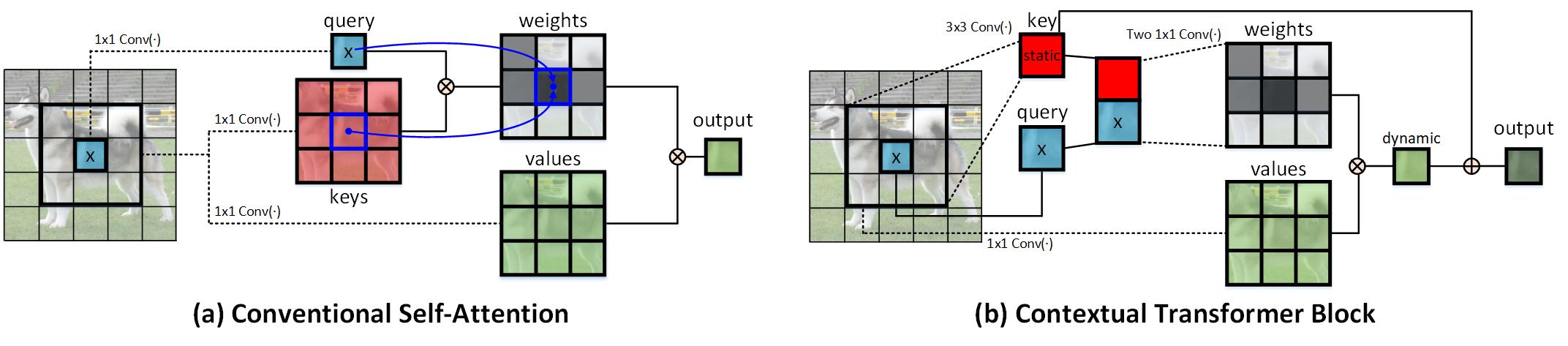
-
Wave-ViT Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning, ECCV 2022
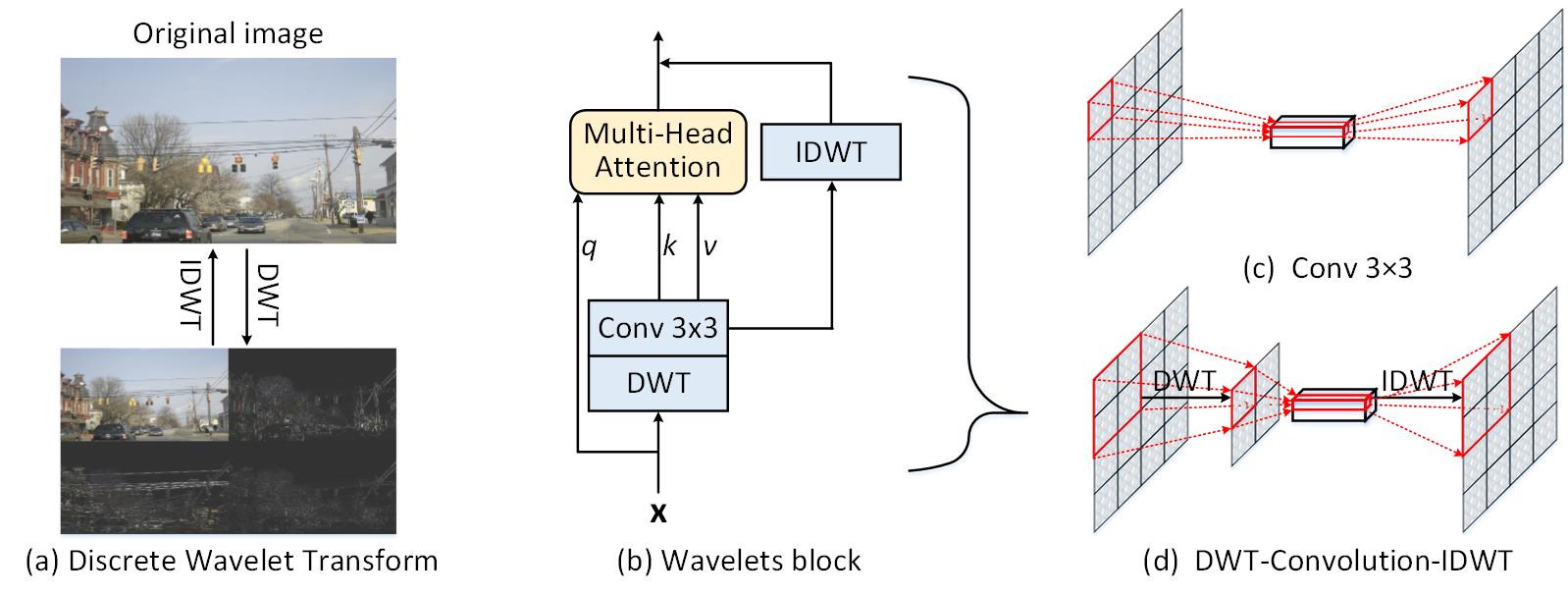
-
Dual-ViT Dual Vision Transformer
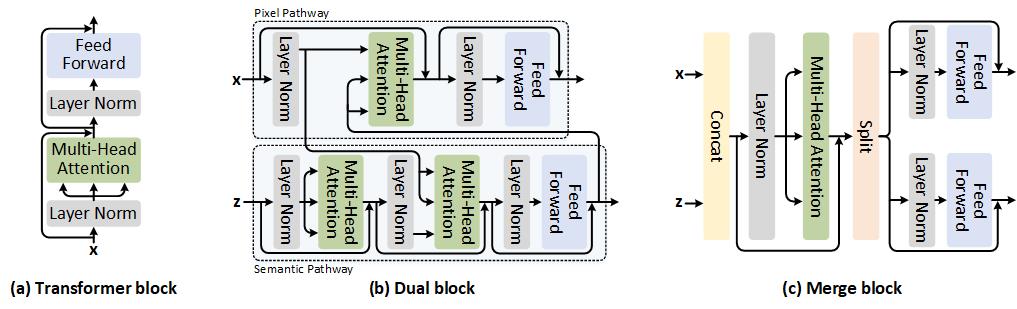



- For Image Classification, please see classification.
- For Object Detection and Instance Segmentation, please see object_detection.
- For Semantic Segmentation, please see semantic_segmentation.
CoTNet
@article{cotnet2022,
title={Contextual transformer networks for visual recognition},
author={Li, Yehao and Yao, Ting and Pan, Yingwei and Mei, Tao},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2022},
publisher={IEEE}
}
Wave-ViT
@inproceedings{wavevit2022,
title = {Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning},
author = {Yao, Ting and Pan, Yingwei and Li, Yehao and Ngo, Chong-Wah and Mei, Tao},
booktitle = {Proceedings of the European conference on computer vision (ECCV)},
year = {2022},
}
Dual-ViT
@article{dualvit2022,
title={Dual Vision Transformer},
author={Yao, Ting and Li, Yehao and Pan, Yingwei and Wang, Yu and Zhang, Xiao-Ping and Mei, Tao},
journal={arXiv preprint arXiv:2207.04976},
year={2022}
}