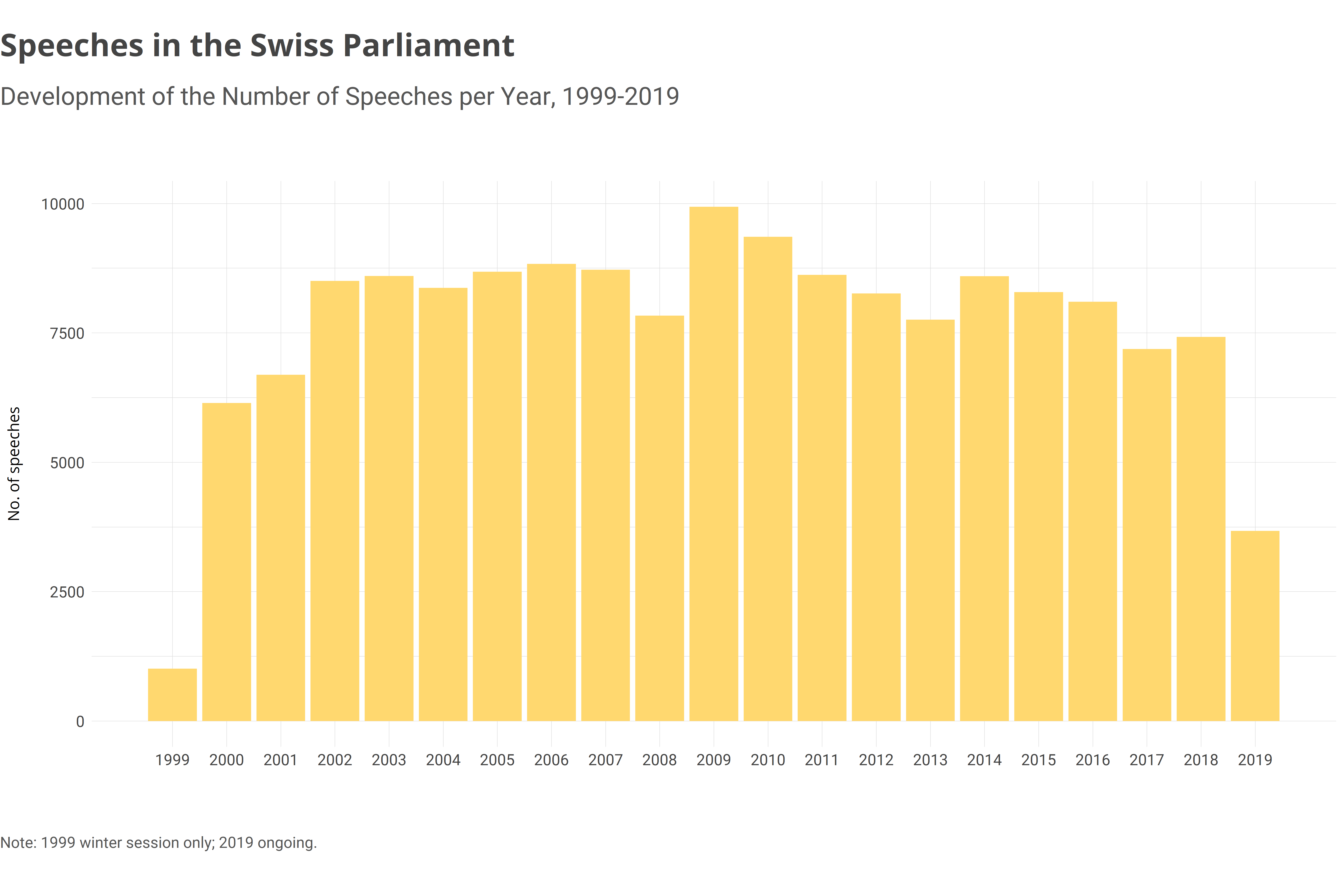
The dataset contains all speeches given in the Swiss Parliament since the 1999 winter session (Wintersession 1999) as well as further information on the speakers, the items of business discussed and the debates. The data were collected using web scraping and are updated at irregular intervals.
File typ: .rds
File size: ~274.2 MB
Items of business covered: 14'353
Debates: 22'092
Speeches: 160'597
Number of words (spoken, cf. below): 55'912'341
https://www.gfzb.ch/swisspoliticalspeeches/20190910.rds
# Download file to working directory
download.file("https://www.gfzb.ch/swisspoliticalspeeches/20190910.rds", "my_file.rds")
# Import
dt <- readRDS("my_file.rds")| Variable | Description |
|---|---|
s_transcript_raw |
Raw transcript of the speech as extracted from the website of the Swiss Parliament. |
s_transcript |
Speech without unspoken content (brackets, page references) |
s_speaker_name |
Name of the speaker |
s_speaker_council |
Council of the speaker (BR = Bundesrat (Federal Council), BK = Bundeskanzler (Federal Chancellor), NR = Nationalrat (National Council), SR = Ständerat (Council of states)) |
s_speaker_canton |
Canton of the speaker (2-letter abbreviation, only for NR and SR) |
s_speaker_faction |
Faction affiliation of the speaker |
s_speaker_president |
Dummy variable, if s_speaker_president == 1 the speaker is council president (subsequently coded by date) |
s_link |
Link to the original transcript on the website of the Swiss Parliament |
s_link_video |
Link to video of the speech on the website of the Swiss Parliament |
s_language_cld2 |
Main language detected by cld2 (subsequently coded) |
s_length_words |
Length of the non-raw transcript in words (subsequently coded) |
b_number |
ID of the discussed item of business |
b_title_german |
Title of the discussed item of business in german |
b_title_french |
Title of the discussed item of business in french |
b_link |
Link to the item of business on the website of the Swiss Parliament |
d_session |
Session of the debate |
d_date |
Date of the debate (YYYY-MM-DD) |
d_time |
Start time of the debate (HHhMM) |
d_council |
Council of debate (NR = Nationalrat (National Council), SR = Ständerat (Council of states), VB = Vereinigte Bundesversammlung (United federal Assembly)) |
d_preliminary |
Dummy variable, if d_preliminary == 1 the transcripts of the debate are preliminary. |
scraping_timestamp |
Time of scraping |
Zumbach, David (2019). Swiss Parliamentary Speeches (1999-2019). Zürich: Grünenfelder Zumbach GmbH.
- Anthology on "Konkordanz" in the Swiss Parliament (Bühlmann et al. 2019)
- Blog post on DeFacto on the federal diversity in Switzerland (Mueller/Zumbach 2017)

# Load packages
pacman::p_load(dplyr, quanteda, lubridate, purrr, ggwordcloud)
# Create a document-feature matrix from the transcripts
dt_dfm <- quanteda::corpus(
dt$s_transcript,
docnames = dt$s_link,
docvars = dt %>%
dplyr::mutate(year = lubridate::year(d_date)) %>%
dplyr::select(year)
) %>%
quanteda::dfm(
tolower = FALSE,
remove_punct = TRUE,
remove_numbers = TRUE,
remove = c(
quanteda::stopwords(language = c("de")),
quanteda::stopwords(language = c("fr")),
quanteda::stopwords(language = c("it"))
)
)
# Function for yearly keyness
get_keyness_per_year <- function(year, n = 30, dfm) {
dfm %>%
quanteda::textstat_keyness(target = quanteda::docvars(dfm, "year") == year) %>%
dplyr::top_n(n, chi2) %>%
dplyr::mutate(year = year)
}
# Calculate keyness for 2014-2019
dt_keyness <- purrr::map_dfr(2014:2019, get_keyness_per_year, n = 30, dfm = dt_dfm)
# Plot
dt_keyness %>%
ggplot2::ggplot(ggplot2::aes(label = feature, size = chi2, alpha = chi2^(1/2))) +
ggwordcloud::geom_text_wordcloud_area() +
ggplot2::scale_size_area(max_size = 14) +
ggplot2::facet_wrap(year~.)