
Scrape information of amazon orders from amazon site
Recorded with Recordit
Add this line to your application's Gemfile:
gem 'amazon_order'And then execute:
$ bundle
Or install it yourself as:
$ gem install amazon_order
chromedriver is required. Please download chromedriver and update chromedriver regularly.
Create credentials following the instructions of https://github.com/kyamaguchi/amazon_auth
Use envchain or .env
amazon_auth
envchain amazon ...
# OR
vi .env
And Dotenv.load or gem 'dotenv-rails' may be required when you use this in your app.
In console
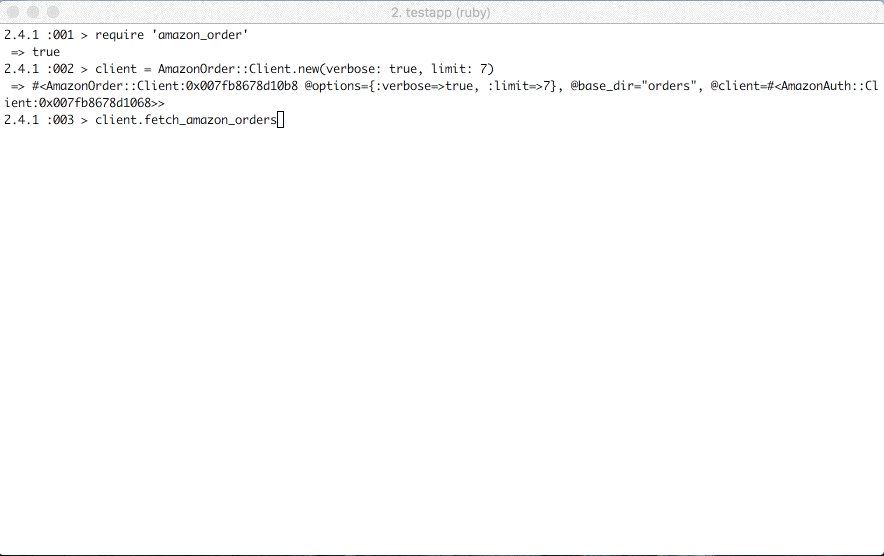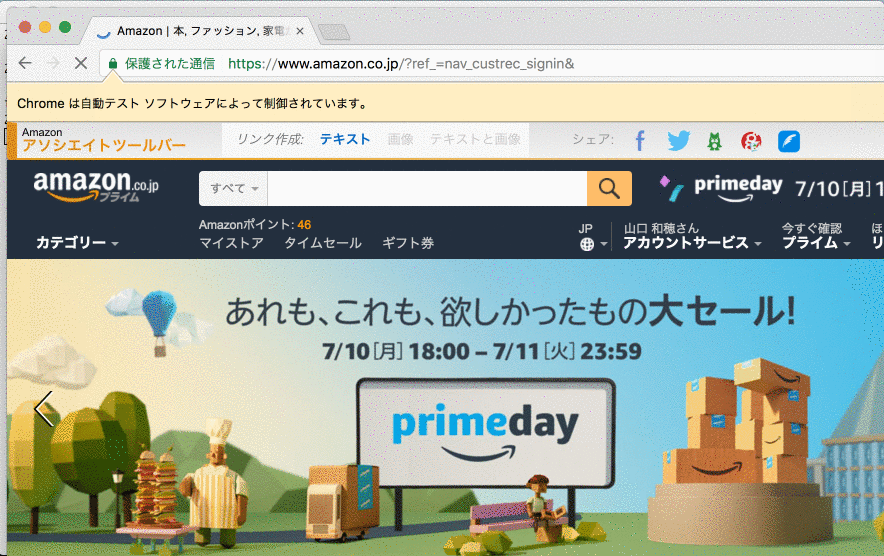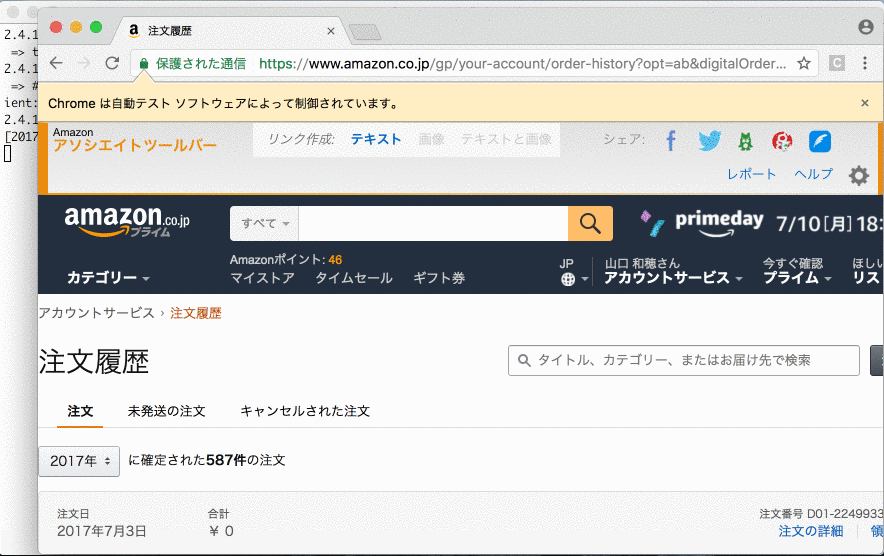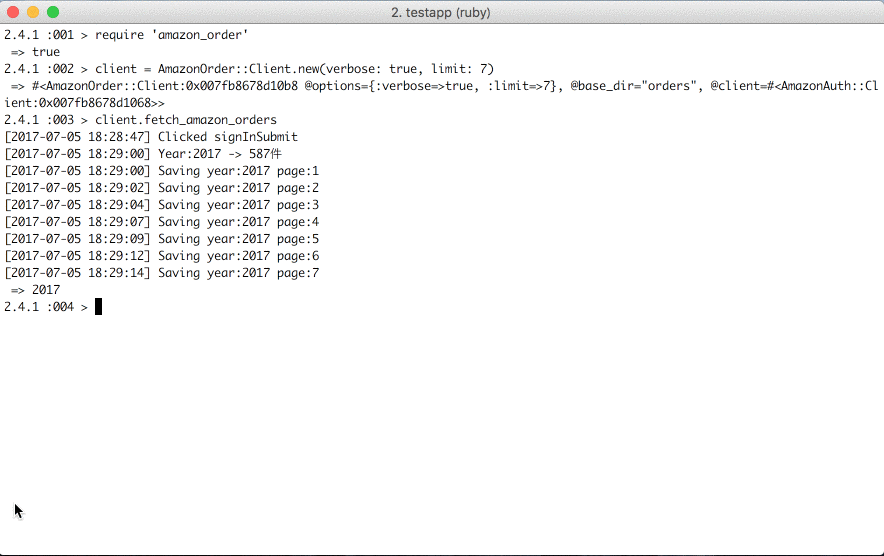
require 'amazon_order'
client = AmazonOrder::Client.new(keep_cookie: true, verbose: true, limit: 10)
client.fetch_amazon_orders
# Fetch orders of specified year
client.fetch_orders_for_year(year: 2016)
# Fetch all pages of specified year
client = AmazonOrder::Client.new(limit: nil)
client.sign_in
client.go_to_amazon_order_page
client.fetch_orders_for_year(year: 2015)Downloaded pages will be stored into tmp/orders directory.
tmp comes from Capybara.save_path.
Once fetch_amazon_orders succeeds, you can load orders information of downloaded pages anytime.
(You don't need to fetch pages with launching browser every time.)
orders = client.load_amazon_orders;nil
orders.size
# Sum of order_total
orders.map(&:order_total).sum
# Products
products = orders.map(&:products).flatten;nil
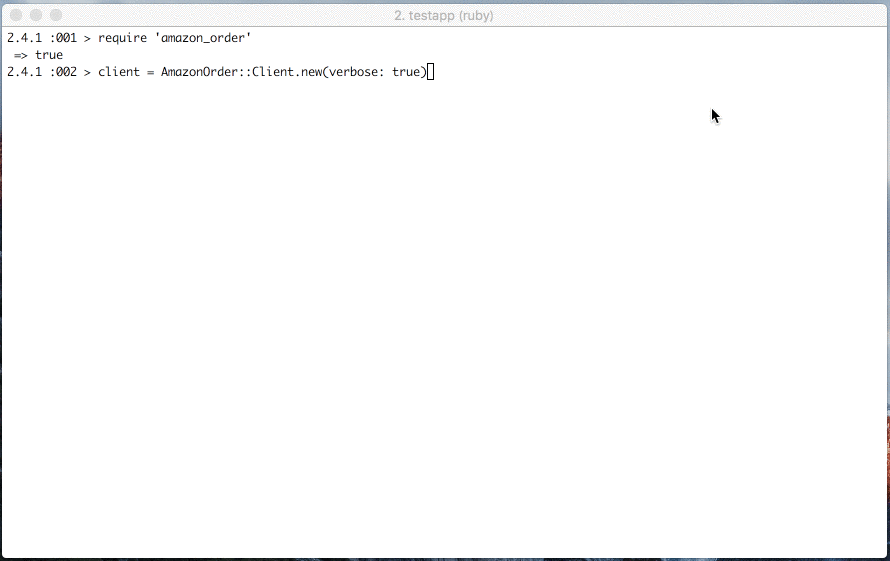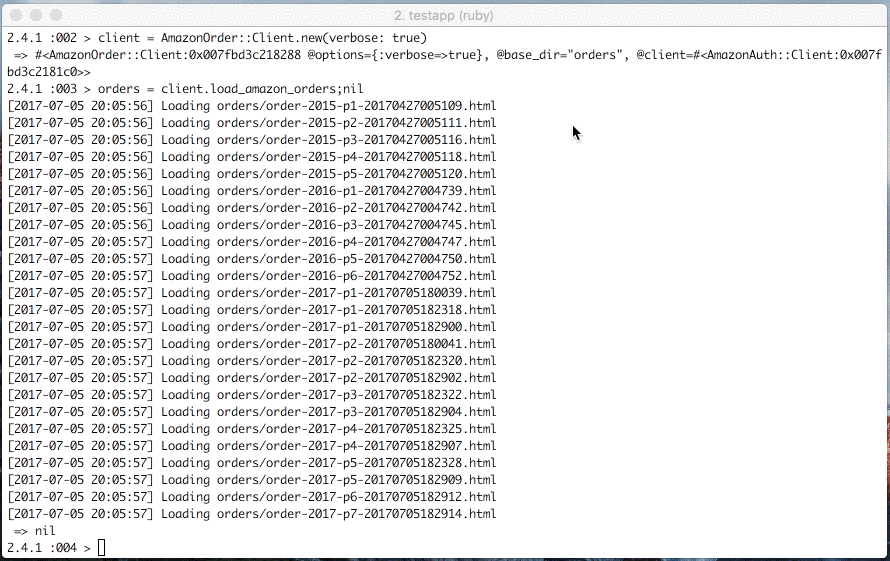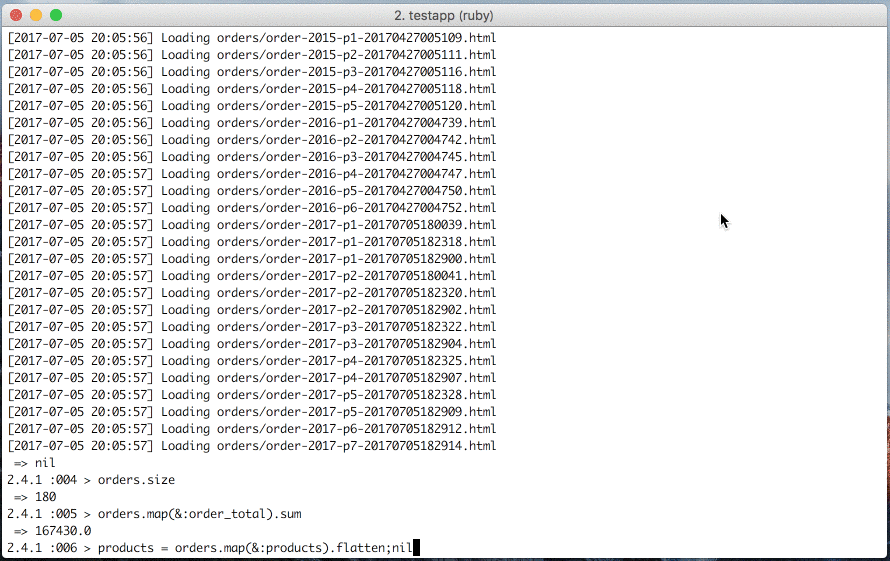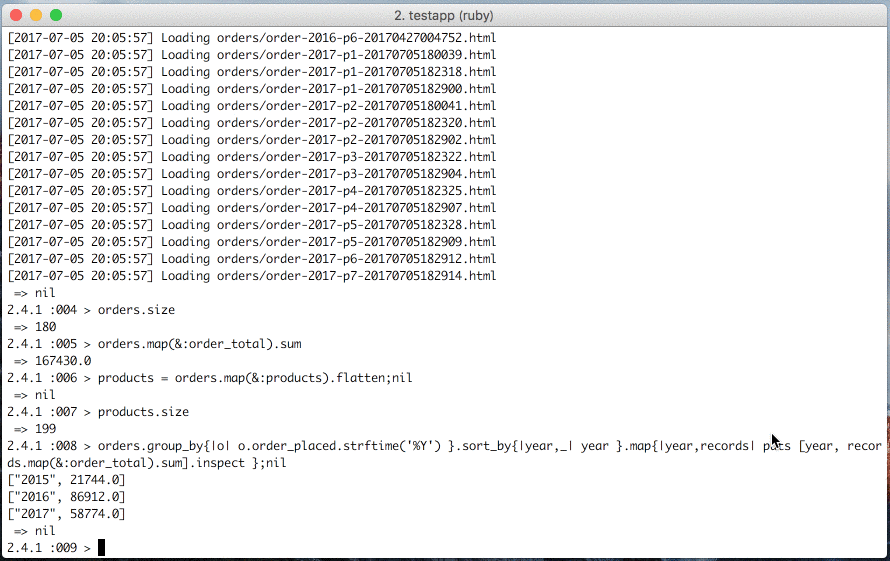
products.size
# Sum of order_total by year
orders.group_by{|o| o.order_placed.strftime('%Y') }.sort_by{|year,_| year }.map{|year,records| puts [year, records.map(&:order_total).sum].inspect };nilconsole> pp orders.first.to_hash
{"order_placed"=>Wed, 25 Aug 2010,
"order_number"=>"503-5746373-6335034",
"order_total"=>2940.0,
"shipment_status"=>nil,
"shipment_note"=>nil,
"order_details_path"=>
"/gp/your-account/order-details/...",
"all_products_displayed"=>false,
:products=>
[{"title"=>"メタプログラミングRuby",
...
}
console> pp products.first.to_hash
{"title"=>"メタプログラミングRuby",
"path"=>"/gp/product/4048687158/...",
"content"=>"Paolo Perrotta, 角征典...",
"image_url"=>
"https://images-fe.ssl-images-amazon.com/images/I/51TODrMIEnL.jpg"}client.generate_csvLimit fetching with number of pages: client = AmazonOrder::Client.new(limit: 5)
(limit: nil for no limit. default is 5)
Set year range: client = AmazonOrder::Client.new(year_from: 2012, year_to: 2013)
(default is Time.current.year)
Keep cookies(keep signin): keep_cookie: true
Firefox: driver: :firefox
Output debug log: debug: true
This may not work well with amazon.com because I don't have enough data of order pages. (amazon.co.jp will be OK)
client = AmazonOrder::Client.new(debug: true)Test parsing of all your orders pages
ORDERS_DIR=/path/to/testapp/orders rspec spec/amazon_order/parser_spec.rb
Bug reports and pull requests are welcome on GitHub at https://github.com/kyamaguchi/amazon_order.
The gem is available as open source under the terms of the MIT License.