论文对cache系统进行了一些优化,针对zipfian分布的数据的优化。因为cache系统每次插入、查询操作都需要对链表进行操作,如果采用加锁链表,单次操作的时间开销就很大,包括加锁与释放锁。论文针对长尾型数据对cache进行了改进,将原有的一个缓存空间划分为两部分:冻结缓存和动态缓存。冻结缓存在冻结期间是只读的,无需维护链表,降低了系统开销。而冻结缓存的每次更新都将最热的键值对存储进去,保证冻结缓存可以覆盖大部分的读操作。这种策略非常适合语料库类的数据(论文中使用MSR和Twitter进行测试)。
文章首先介绍了缓存的使用场景,介绍了zipfian这种长尾型数据,并且说明在很短的时间内,最热的项目是相对稳定的,这是论文研究的根基所在。后面的研究也是在这种数据类型的基础上展开的。
文章接下来介绍了一些现有的提高缓存可拓展性的解决方案:无锁数据结构、使用命中率换取可拓展性、分片和细粒度锁。这其实也是我在这次实验中思路的来源:首先我研究了无锁数据结构,发现采用原子操作去维护一个双向链表异常困难,需要保证同时修改四个指针,并且整个过程不能有其他操作影响。其次就是使用命中率换取可拓展性,这其实就是Redis的抽样cache系统,这种随机抽样并逐出的方案无需维护链表,理论上效率非常高,但是会牺牲一部分命中率。最后是细粒度锁,也是我在本次实验中采用的方案,我对链表的每次操作只需对三个节点进行加锁,而无需对整个数据结构加锁。但是在实验的过程中我也发现,不同线程会争抢头节点指针,造成阻塞。
文章接下来讲解了FrozenHot的设计方案:冻结缓存FC、动态缓存DC以及FC控制器。DC就是原有的缓存机制,FC将热门键值对冻结起来而不维护他们的排序,消除对锁的依赖,FC控制器则是控制FC的更新。用户查找时先从无锁无管理的FC中查找,未命中则从DC中查找,DC也未命中则从硬盘等介质获取并插入DC。FC控制器是FrozenHot的精华所在,它分为学习阶段、重构阶段和冻结阶段。学习阶段FC控制器学习当前阶段最优的FC缓存占比,重构阶段合并FC和DC并重建两个缓存,这个重建发生在三种情况:①请求延迟和吞吐量下降到学习阶段获得的基线性能时②定时刷新③当数据不符合zipfian(我认为是)时,整个缓存回到只有DC的状态。FrozenHot不是针对某一种缓存算法,而是一种通用的缓存管理策略,其部署也相当简单。
文章接下来对FrozenHot的性能进行了评估。从箱型线来看,吞吐量的最大提升超过500%,大部分的性能提升也超过了100%,而且随着线程数量的提升,吞吐量提升越明显。而且缓存命中率相较于基线(DC)也有压倒性优势。缓存延迟在高线程数量下有着极大的优势,尤其是应用于LFU算法时。文章还进行了灵敏性分析,无论是缓存大小还是存储设备延迟的改变,都不会影响FrozenHot在吞吐量上的优势。
我认为论文最最重要的贡献在于为缓存管理的优化提供了一种新的思路。让性能优化不再局限于提升链表的性能、牺牲命中率换取效率,而是从更上层的管理策略入手,根据数据的特征,反向优化我们的系统。这种有倾向性的优化方案让我眼前一亮,非常值得学习。
使用泛型<key_type, value_type>扩充使用范围。
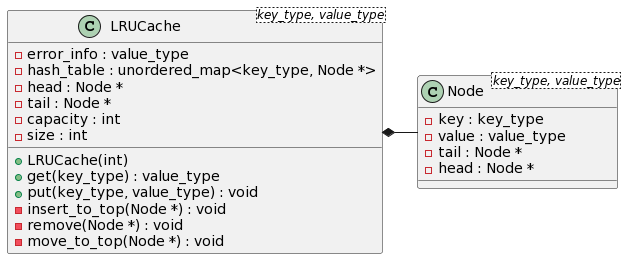
双向链表(独立实现):使用共享锁、互斥锁、原子操作实现的支持多并发的双向链表
无锁HashTable(第三方库):bhhbazinga/LockFreeHashTable: Lock Free Resizable Hash Table Based On Split-Ordered Lists. (github.com)
- 采用粒度加锁,实现更细化的控制,每次对链表的操作只需要对三个节点进行加锁,但是对三个节点的随意加锁又会产生死锁问题。所以我对设计了如下加锁策略:
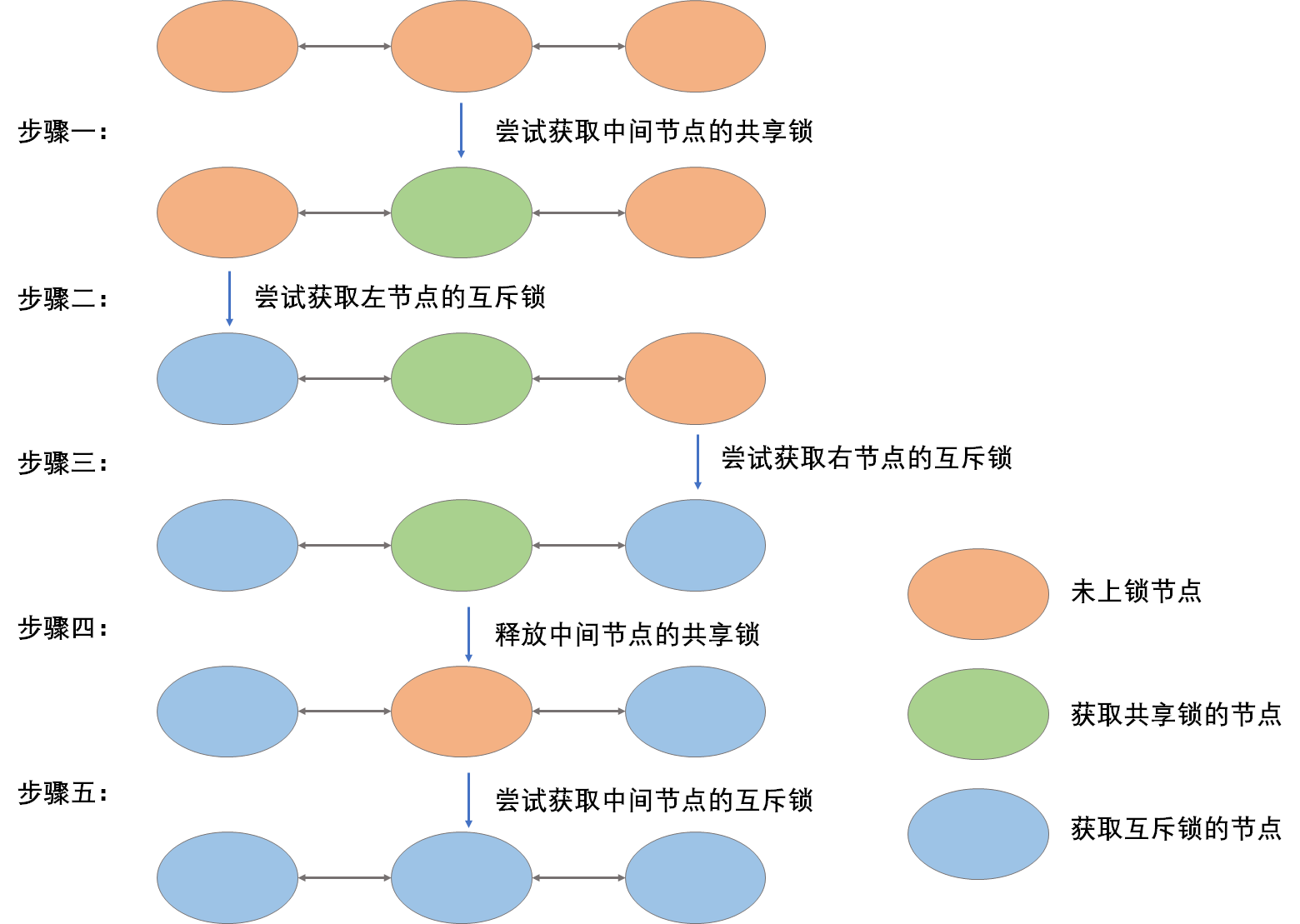
- 设计思路:
通常来说,只要保证所有线程对三个节点上锁的顺序一致(全部正向或全部逆向),就可以避免死锁问题。例如:线程A在获得左侧、中间节点的互斥锁后,如果线程B获取了右侧节点的互斥锁(此节点是线程B的左侧节点,也是线程A的右侧节点),只需要让线程A等待线程B处理完并释放锁,线程A就可以继续执行。由于双向链表不是一个环,所以这种等待策略并不会产生哲学家吃通心面问题。
但是这种简单的顺序加锁策略会产生指针悬挂问题:线程A对左侧节点加锁后,中间节点锁被线程B占用,如果线程B将节点删除,左侧节点的tail指针就会产生悬挂。
所以我首先对中间节点加共享锁B,这个加锁过程循环等待,直至获得锁。然后对左侧节点加互斥锁A,这个加锁过程不循环等待,如果出现锁被占用,则会退释放锁B到初始状态,这是为了避免产生死锁。最后对右侧节点加互斥锁C,这个加锁过程循环等待。最后一个过程循环等待而不是回退,是因为不会产生死锁问题,就像上面所说的,不会产生哲学家吃通心面问题。最后将中间节点的共享锁释放并加互斥锁,这个过程同样是安全的,因为此时左右两节点都已经加上互斥锁。
| 加锁类型 | 加锁策略 | |
|---|---|---|
| 左侧节点锁A | 互斥锁 | 循环等待 |
| 中间节点锁B | 先共享锁,后互斥锁 | 失败直接回退并释放所有锁 |
| 右侧节点锁C | 互斥锁 | 循环等待 |
- 加锁策略的代码示例如下:
/*
* 这是双向链表删除节点的代码节选
* 用于展示自定义的加锁策略
*/
while (true) {
std::shared_lock lock2(now->mut, std::try_to_lock); // 获得中间节点的共享锁B
while (!lock2.owns_lock()) { // 循环等待
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::shared_lock lock2(now->mut, std::try_to_lock);
}
std::unique_lock lock1(now->head->mut, std::try_to_lock); // 获得左侧节点的互斥锁A
if (!lock1.owns_lock()) { // 失败直接回退
lock2.unlock(); // 释放锁B
continue;
}
std::unique_lock lock3(now->tail->mut, std::try_to_lock); // 获得右侧节点的互斥锁B
while (!lock3.owns_lock()) { // 循环等待
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::unique_lock lock3(now->tail->mut, std::try_to_lock);
}
lock2.unlock(); // 释放中间节点的共享锁
std::unique_lock lock2_unique(now->mut, std::try_to_lock); // 更换成互斥锁
while (!lock2_unique.owns_lock()) { // 循环等待
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::unique_lock lock2_unique(now->mut, std::try_to_lock);
}
now->head->tail = now->tail;
now->tail->head = now->head;
size.fetch_sub(1, std::memory_order_relaxed);
break;
}- 原子操作
链表的size采用原子操作,提高系统并发效率
std::atomic<int> size; // use atomic to avoid mutex cost
size.fetch_sub(1, std::memory_order_relaxed);
size.fetch_add(1, std::memory_order_relaxed);原本想尝试自己实现一个无锁的数据结构,但是随着学习的深入,发现以我现在的能力实现起来十分的困难,有许多细节的地方考虑不到。所以我使用了GitHub上开源的一种无锁HashTable。
这个HashTable提供了非常方便的接口,给我自己实现一个通用的双向链表提供了一些参考,比如使用泛型提高数据结构的通用性,这也使得我的实验过程得到了简化。
总体来说,多线程的LRU cache类与单线程的LRU cache结构一致,只需要更改使用的数据结构即可。
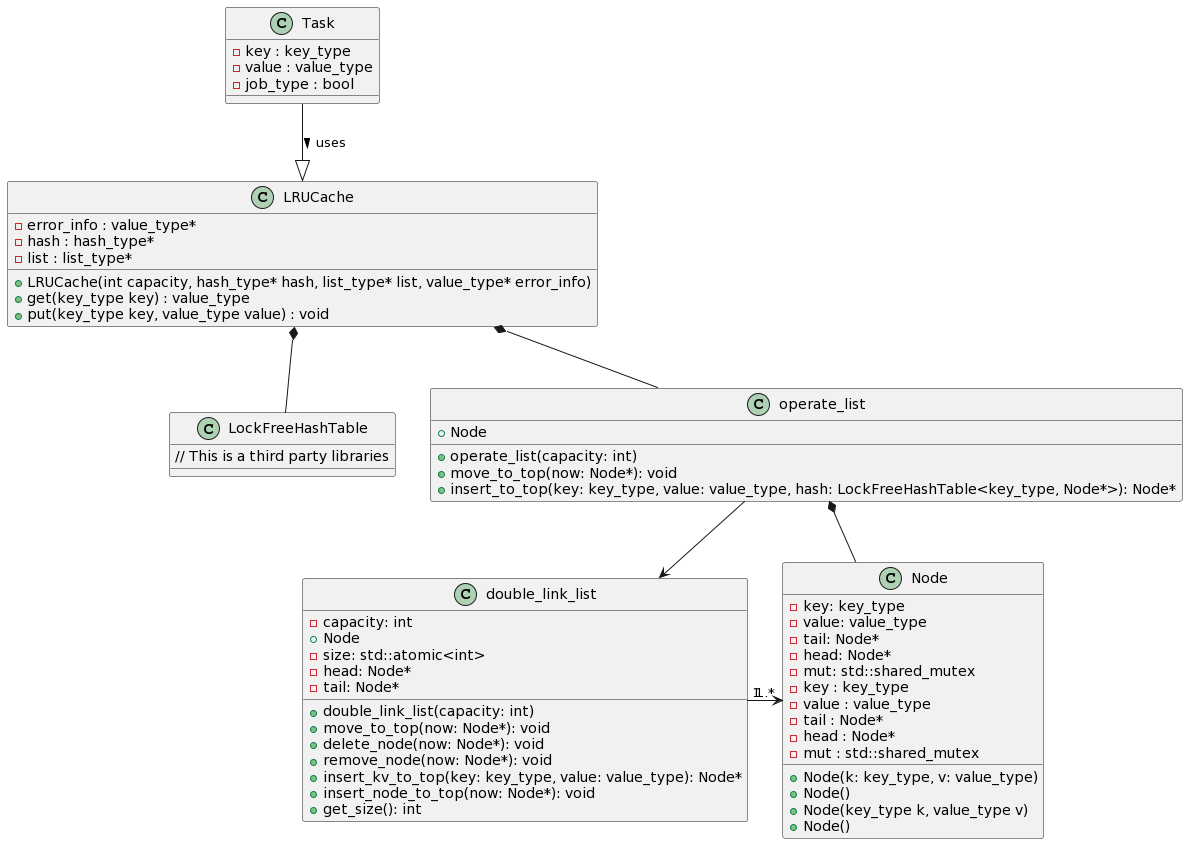
双向链表类double_link_list是通用的链表实现,通过泛型指定key_type与value_type,但是为了方便实现LRU cache对链表的操作,使用operate_list类对链表进行封装。
使用时只需要创建LRUcache类、operate_list类、LockFreeHashTable类,然后将链表和哈希表作为参数传入LRUcache中,使用LRUcache的get和put接口即可完成操作。
实验数据分为两类:随机分布与zipfian分布
二者产生的数据分布如下,左图为随机分布,右图为zipfian分布。可以看到zipfian分布有明显的数据倾斜。
单线程LRU cache
随机分布结果:

zipfian分布结果:

多线程LRU cache
随机分布结果:

zipfian分布结果:

从实验结果看,LRU cache系统非常适合zipfian这种”长尾型“分布的数据,随机分布的命中率接近cache容量与Key范围的比值,而zipfian分布的命中率明显高于随机分布。
但是从cache系统的效率来看,多线程下加粒度锁的双向链表的表现反而不如单线程未加锁的双向链表,我对这种现象的原因做了以下分析:
LRU cache系统对链表的每次操作,都需要将被操作节点移动至链表的头部,这个操作需要对头节点进行加锁。而每个线程的每个操作都需要获得头结点的锁,这导致系统的并发十分困难,产生了大量的阻塞。- 相较于单线程未加锁的双向链表,多线程下加粒度锁的双向链表会进行大量的加锁、释放锁的操作,增加了系统开销。
以上两点造成了多线程cache系统运行时间比单线程cache系统长。我觉得只要缓解头结点的竞争,就可以大幅提升多线程下的表现。
可以采用Redis的采样LRU。经典LRU使用双向链表维护cache中最应该被淘汰的键值对,这样可以保证每次移除的是最旧的。而采样删除的策略虽然不能保证每次删除的都是最旧的,但是却不用维护一个双向链表。牺牲一部分的命中率,提升系统的效率。随机采样并删除样本中最旧的一个键值对,这个思路我感觉很棒。
论文的优化思路十分新颖,对创新点的阐述也十分清晰,对FC缓存的特点、创建方式、重构策略等进行了清晰的讲解。对创新点的灵感来源、优化效果的来源也进行了阐述。原理图的绘制清晰简明,理解起来很方便。实验过程十分详尽,公平地对比了改进缓存与基线缓存的性能。
FrozenHot策略的描述要是加一些流程图或者伪代码就更好了。比如一些缓存未命中的处理比较难以理解。
我对缓存管理、缓存算法的认识更加清晰,对常见的优化思路有了初步理解。也了解了一些论文中常见的图形,例如箱型图等。也明白了论文中有一个清晰易懂的示意图的重要性。
在实验的过程中,我对C++工程的理解更加深入,比如Header-Only的库、GitHub子模块的使用,也明白了代码复用的重要性。
在论文的3.2.2部分,提到FC哈希表是DC的子集,我其实不是很明白为什么是子集的关系,FC是从整个缓存中选区的最热键值对,而DC是剩余的键值对,为什么FC是DC的子集?
在论文的3.2.3部分,Periodic refresh过程重建FC,文章提到无需重新寻找最佳的FC_radio,为什么上一个学习阶段获得的FC_radio仍是有效的?并没有说明原因。
目前的研究方向大致分为两类,一类是针对数据结构的优化,例如不断优化无锁双向链表、无锁哈希表等,另一类是Redis和FrozenHot这种针对管理方式、系统架构的改进优化。
我认为学者们可以注重第二种在架构上的升级,这样往往能够带来巨大的性能提升,提升幅度比优化数据结构要大得多。但是对数据结构的优化是通用的,不仅仅可以应用于缓存系统,还可以为其他方向提供新的思路,也是很重要的工作。
总的来说,技术的迭代往往是一次重大的架构更新跟随着许多细节的优化,进而一步一步发展。