注意:
分布式运行的时候, 如果出现python报各种找不到module的错误, 然而这个module明明已经安装了, 那么很可能是ssh到新的节点上的时候, virtualenv没有运行起来. 解决办法如下
- 首先在
.bashrc中添加一条source语句, 目的是每次登录都自动加载virtualenv. - 然后重新登录你的账户.
- Symbol: 声明式 (Declarative) 的符号表达式 (就是更贴近数学语言的程序语言啦)
- NDArray: 命令式 (Imperative) 的张量计算 (一脸懵逼???什么是张量? 就是有现实意义、有计量单位的数组啦. 链接: 数学不行还学AI-第四话-知乎 )
- **KVStore: ** 多设备间的数据交互. 通过push/pull实现交互.
push: worker向server推键值对pull: server从worker按照键来取值updater: push同一个键时所作的操作. 默认为覆盖. 用户可以绑定自己的updater回调函数, 来实现梯度下降\权值更新等目的.
- [EB/OL] MXNet设计和实现简介
- [J] A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems
- [EB/OL] MXNet System Architecture
- [EB/OL] Deep Learning Programming Style
三种角色: server\worker\scheduler
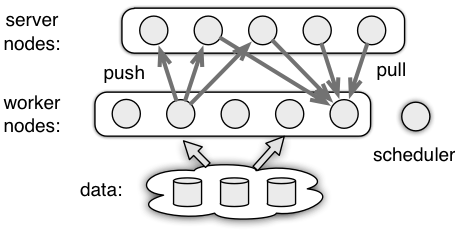
- Worker. A worker node performs the main computations such as reading the data and computing the gradient. It communicates with the server nodes via
pushandpull. For example, it pushes the computed gradient to the servers, or pulls the recent model from them. - Server. A server node maintains and updates the model weights. Each node maintains only a part of the model.
- Scheduler. The scheduler node monitors the aliveness of other nodes. It can be also used to send control signals to other nodes and collect their progress.
2017-7-24 更新: 请参照明矾队长的工作笔记 .

- [EB/OL]PS-Lite Documents. 这个文档介绍了PS-Lite的原理和用法.
- 追评: 感觉这个文档没什么用. 除了介绍了几个ps-lite要用的环境变量, 其他的都还没写完.
- [EB/OL]PS-Lite源码分析 - 程序园. 这个博文详细分析了PS-Lite的结构, 各个模块(类)的职能.
- 追评: 很详细. 语言组织不够流畅. 但是仔细看很有收获.
- [EB/OL]PS-Lite源码剖析 - 作业部落. 这个博文详细剖析了PS-Lite的类职能, 消息处理流程和实现细节. 并给出了简单的例子.
- [EB/OL]【深度学习&分布式】Parameter Server详解 - 仙道菜 - CSDN博客. 这个博文详细解释了Parameter Server的优点(重点在几个动图), 架构(重点在push, pull, range push和range pull), 以及build blocks(由哪些算法和方法组成).
- [J] Scaling Distributed Machine Learning with the Parameter Server. 注意看Algorithm 1, 里面有ps-lite如何用来做分布式的随机梯度下降.
- 明矾队长的工作笔记 .
需要链接这些库:
-lrdmacm -libverbs
- Building an RDMA-Capable Application with IB Verbs
- RDMA Read and Write with IB Verbs
- Basic Flow Control for RDMA Transfers
- RDMA Aware Programming User Manual 这可以说是RDMA的官方API文档. 不过...信息量太少, 看起来很吃力.
- Writing RDMA applications on Linux. 思科的ppt.
- RDMA教程.
- RDMA 课程PPT .
- RDMA mojo : blog on RDMA technology and programming RDMA创建者之一的博客.
- RDMA和IB的源码. RDMA和IB实际上是Linux源码的一部分.
- RDMA编程速记 .
- Basic Flow Control for RDMA Transfers的代码. 在appendix目录中也有本地备份.
- 在每个进程的main添加睡眠时间, 使得你有足够的时间打断点.
- 找到pid, 以便下一步把gdb附加到进程(Attach to process)
- 一般来说可以用
ps -al | grep 用户名的方式找到要调试的进程的pid. - 还可以用htop. htop类似于windows的任务管理器, 功能更强大.
- 一般来说可以用
- 用
gdb -p pid或用gdb的内部命令attach开始调试进程. - 在
(gdb)命令提示符中, 用source 文本文件加载调试脚本, 避免重复输入打断点的命令, 可以让打断点更从容一些. - 找到每个进程的角色: scheduler会打印一些调试信息. 这些信息会显示出每个角色分别在哪个node的哪个端口监听着. 用
netstat -antup找到占用端口的pid.
常见的命令有backtrace(bt) - 显示调用堆栈, list-显示当前及周围几行的代码.
print, display
如果要打印主调函数的堆栈内容, 可以用frame x切换到第x个栈帧.
linux执行程序遇到段错误时, 会产生核心转储文件. 默认core大小为0, 也就是不产生core文件. 通过命令
ulimit -c unlimited来允许系统产生core文件.
之后执行出错的程序, 目的是复现段错误. 复现之后在可执行文件的目录下会产生一个core.#####文件. #号为线程pid.
通过命令
gdb <executable> <corefile>就可以查看出错的代码位置(前提是可执行文件在编译生成的时候加了调试选项 -g).
结合前面所述的backtrace, list, print等gdb命令就可以快速定位野指针位置.
首先用gdb的attach <pid> 命令进入指定pid的进程(用ps\top\htop等方式获得死锁进程的pid). 通过调用堆栈backtrace \ bt 命令来查看死锁发生的位置. 然后用info thread命令查看子线程在当前进程中的id. 再用thread <id> 命令进入指定线程的上下文. 通过bt命令查看死锁位置. 这样就能分析出是哪些行为导致了死锁.
在集群上进行源码编译的时候, 经常需要追加PATH, C_INCLUDE_PATH, CPLUS_INCLUDE_PATH, LIBRARY_PATH, LD_LIBRARY_PATH, PKG_CONFIG_PATH. 前五个比较好理解, 是可执行文件、包含文件、库文件的目录, 通常对gcc有用. 而PKG_CONFIG_PATH则是给configure或者cmake检查包是否存在用的. 通常一个成熟的包的lib目录下有pkgconfig目录. 如果有, 一定要追加到PKG_CONFIG_PATH里面. 否则cmake或者configure脚本就有可能检查不到库.
bugsticide是我自己创造的词, 来自于杀虫剂(pesticide).
假如工具没问题, 而上层代码使用工具的方法有问题, 那么我们不必一点一点地调试上层代码, 而是在工具代码的前面加一个
*(int*)0=1;来触发核心转储. 有了核心转储就能看到调用是谁在什么时候调用工具代码(查看调用堆栈). 还可以打印出哪些信息传入了工具代码.