

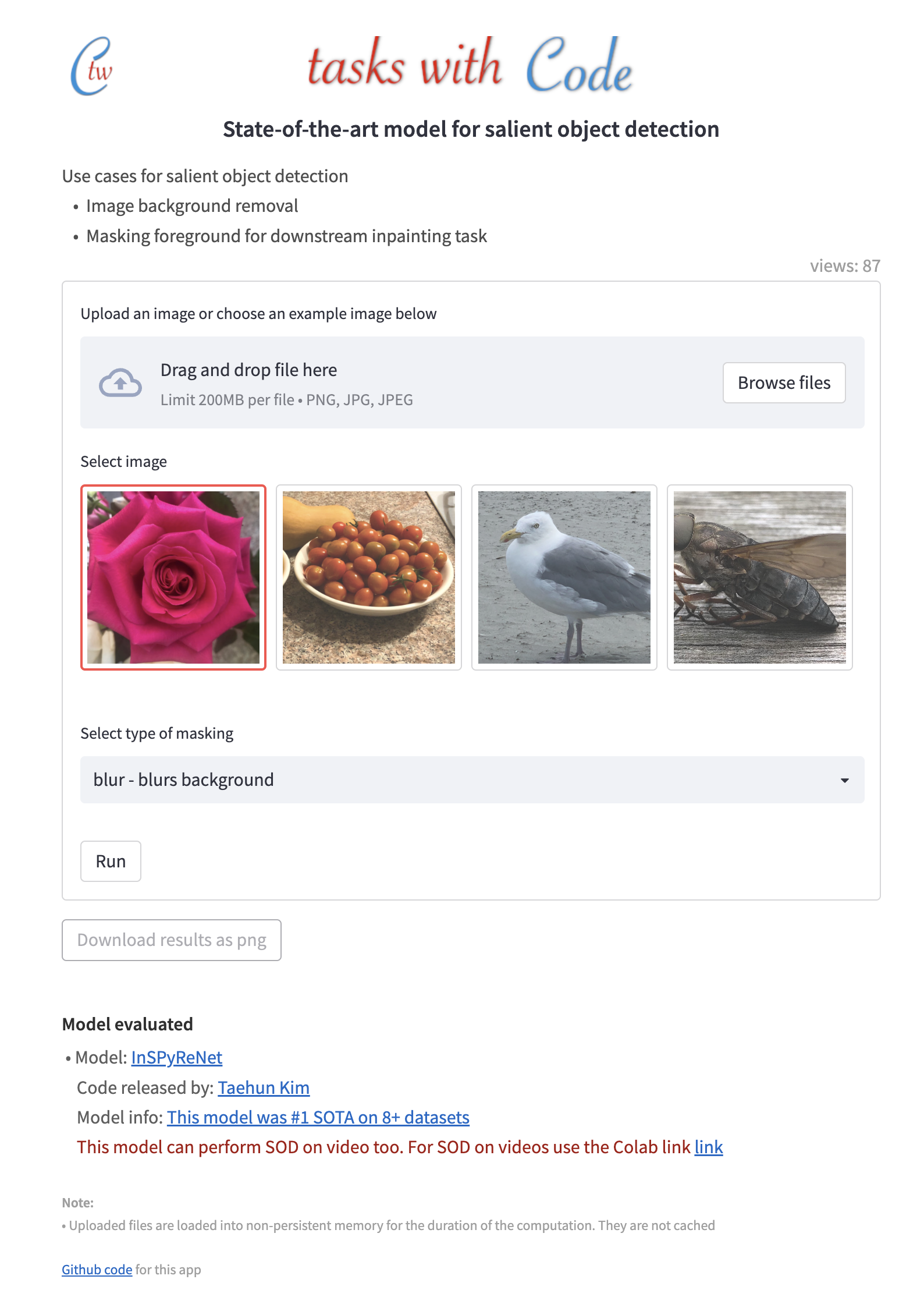
PyTorch implementation of Revisiting Image Pyramid Structure for High Resolution Salient Object Detection (InSPyReNet)
To appear in the 16th Asian Conference on Computer Vision (ACCV2022)
[Arxiv]
Abstract: Salient object detection (SOD) has been in the spotlight recently, yet has been studied less for high-resolution (HR) images. Unfortunately, HR images and their pixel-level annotations are certainly more labor-intensive and time-consuming compared to low-resolution (LR) images. Therefore, we propose an image pyramid-based SOD framework, Inverse Saliency Pyramid Reconstruction Network (InSPyReNet), for HR prediction without any of HR datasets. We design InSPyReNet to produce a strict image pyramid structure of saliency map, which enables to ensemble multiple results with pyramid-based image blending. For HR prediction, we design a pyramid blending method which synthesizes two different image pyramids from a pair of LR and HR scale from the same image to overcome effective receptive field (ERF) discrepancy. Our extensive evaluation on public LR and HR SOD benchmarks demonstrates that InSPyReNet surpasses the State-of-the-Art (SotA) methods on various SOD metrics and boundary accuracy.
| Demo1 | Demo2 |
|---|---|
 |
 |
| InSPyReNet | pyramid blending |
|---|---|
 |
 |
- Create conda environment with following command
conda create -y -n inspyrenet python=3.8 - Activate environment with following command
conda activate inspyrenet - Install requirements with following command
pip install -r requirements.txt
| Item | Destination Folder | OneDrive | GDrive |
|---|---|---|---|
| Train Datasets | data/Train_Dataset/... |
Link | Link |
| Test Datasets | data/Test_Dataset/... |
Link | Link |
| Res2Net50 checkpoint | data/backbone_ckpt/*.pth |
Link | Link |
| SwinB checkpoint | data/backbone_ckpt/*.pth |
Link | Link |
- Train InSPyReNet (SwinB)
python run/Train.py --config configs/InSPyReNet_SwinB.yaml --verbose
- Train with extra training datasets can be done by just changing Train.Dataset.sets in the
yamlconfig file, which is just simply adding more directories (e.g., HRSOD-TR, HRSOD-TR-LR, UHRSD-TR, ...):
Train:
Dataset:
type: "RGB_Dataset"
root: "data/RGB_Dataset/Train_Dataset"
sets: ['DUTS-TR'] --> ['DUTS-TR', 'HRSOD-TR-LR', 'UHRSD-TR-LR']
- Inference for test benchmarks
python run/Test.py --config configs/InSPyReNet_SwinB.yaml --verbose
- Evaluate metrics
python run/Eval.py --config configs/InSPyReNet_SwinB.yaml --verbose
- Please note that we only uploaded the low-resolution (LR) version of HRSOD and UHRSD due to their large image resolution. In order to use them, please download them from the original repositories (see references below), and change the directory names as we did to the LR versions.
- You can inference your own single image or images (.jpg, .jpeg, and .png are supported), single video or videos (.mp4, .mov, and .avi are supported), and webcam input (ubuntu and macos are tested so far).
python run/Inference.py --config configs/InSPyReNet_SwinB.yaml --source [SOURCE] --dest [DEST] --type [TYPE] --gpu --jit --verbose- SOURCE: Specify your data in this argument.
- Single image -
image.png - Folder containing images -
path/to/img/folder - Single video -
video.mp4 - Folder containing videos -
path/to/vid/folder - Webcam input:
0(may vary depends on your device.)
- Single image -
- DEST (optional): Specify your destination folder. If not specified, it will be saved in
resultsfolder. - TYPE: Choose between
map, green, rgba, blurmapwill output saliency map only.greenwill change the background with green screen.rgbawill generate RGBA output regarding saliency score as an alpha map. Note that this will not work for video and webcam input.blurwill blur the background.
- --gpu: Use this argument if you want to use GPU.
- --jit: Slightly improves inference speed when used.
- --verbose: Use when you want to visualize progress.
- SOURCE: Specify your data in this argument.
Note: If you want to try our trained checkpoints below, please make sure to locate latest.pth file to the Test.Checkpoint.checkpoint_dir.
| Backbone | Train DB | Config | OneDrive | GDrive |
|---|---|---|---|---|
| Res2Net50 | DUTS-TR | InSPyReNet_Res2Net50 | Link | Link |
| SwinB | DUTS-TR | InSPyReNet_SwinB.yaml | Link | Link |
| Backbone | Train DB | Config | OneDrive | GDrive |
|---|---|---|---|---|
| SwinB | DUTS-TR, HRSOD-TR-LR | InSPyReNet_SwinB.yaml | Link | Link |
| SwinB | HRSOD-TR-LR, UHRSD-TR-LR | InSPyReNet_SwinB.yaml | Link | Link |
| SwinB | DUTS-TR, HRSOD-TR-LR, UHRSD-TR-LR | InSPyReNet_SwinB.yaml | Link | Link |
- *-LR denotes resized into low-resolution scale (i.e., 384 X 384).
| Backbone | Train DB | Config | OneDrive | GDrive |
|---|---|---|---|---|
| SwinB | DUTS-TR, HRSOD-TR | InSPyReNet_SwinB.yaml | Link | Link |
| SwinB | HRSOD-TR, UHRSD-TR | InSPyReNet_SwinB.yaml | Link | Link |
| Backbone | Train DB | Config | OneDrive | GDrive |
|---|---|---|---|---|
| SwinB | DUTS-TR, DUTS-TE, FSS-1000, MSRA-10K, ECSSD, HRSOD-TR-LR, UHRSD-TR-LR | InSPyReNet_SwinB.yaml | Link | Link |
Note: Due to the cloud memory shortage, we only provide results trained on DUTS-TR only. Please generate yourself for the models with extra training datasets if you need.
| Backbone | DUTS-TE | DUT-OMRON | ECSSD | HKU-IS | PASCAL-S | DAVIS-S | HRSOD-TE | UHRSD-TE |
|---|---|---|---|---|---|---|---|---|
| Res2Net50 | Link | Link | Link | Link | Link | N/A | N/A | N/A |
| SwinB | Link | Link | Link | Link | Link | Link | Link | Link |
- Quantitative
| LR Benchmark | HR Benchmark | HR Benchmark (Trained with extra DB) |
|---|---|---|
 |
 |
 |
- Qualitative
| DAVIS-S & HRSOD | UHRSD | UHRSD (Trained with extra DB) |
|---|---|---|
 |
 |
 |
@article{kim2022revisiting,
title={Revisiting Image Pyramid Structure for High Resolution Salient Object Detection},
author={Kim, Taehun and Kim, Kunhee and Lee, Joonyeong and Cha, Dongmin and Lee, Jiho and Kim, Daijin},
journal={arXiv preprint arXiv:2209.09475},
year={2022}
}
-
Backbones: Res2Net, Swin Transformer
-
Datasets:
-
Evaluation Toolkit
- SOD Metrics (e.g., S-measure): PySOD Metrics
- Boundary Metric (mBA): CascadePSP