by Jun Wei, Shuhui Wang, Qingming Huang
 Most of existing salient object detection models have achieved great progress by aggregating multi-level features extracted from convolutional neural networks. However, because of the different receptive fields of different convolutional layers, there exists big differences between features generated by these layers. Common feature fusion strategies (addition or concatenation) ignore these differences and may cause suboptimal solutions. In this paper, we propose the F3Net to solve above problem, which mainly consists of cross feature module (CFM) and cascaded feedback decoder (CFD) trained by minimizing a new pixel position aware loss (PPA). Specifically, CFM aims to selectively aggregate multi-level features. Different from addition and concatenation, CFM adaptively selects complementary components from input features before fusion, which can effectively avoid introducing too much redundant information that may destroy the original features. Besides, CFD adopts a multi-stage feedback mechanism, where features closed to supervision will be introduced to the output of previous layers to supplement them and eliminate the differences between features. These refined features will go through multiple similar iterations before generating the final saliency maps. Furthermore, different from binary cross entropy, the proposed PPA loss doesn’t treat pixels equally, which can synthesize the local structure information of a pixel to guide the network to focus more on local details. Hard pixels from boundaries or error-prone parts will be given more attention to emphasize their importance. F3Net is able to segment salient object regions accurately and provide clear local details. Comprehensive experiments on five benchmark datasets demonstrate that F3Net outperforms state-of-the-art approaches on six evaluation metrics.
Most of existing salient object detection models have achieved great progress by aggregating multi-level features extracted from convolutional neural networks. However, because of the different receptive fields of different convolutional layers, there exists big differences between features generated by these layers. Common feature fusion strategies (addition or concatenation) ignore these differences and may cause suboptimal solutions. In this paper, we propose the F3Net to solve above problem, which mainly consists of cross feature module (CFM) and cascaded feedback decoder (CFD) trained by minimizing a new pixel position aware loss (PPA). Specifically, CFM aims to selectively aggregate multi-level features. Different from addition and concatenation, CFM adaptively selects complementary components from input features before fusion, which can effectively avoid introducing too much redundant information that may destroy the original features. Besides, CFD adopts a multi-stage feedback mechanism, where features closed to supervision will be introduced to the output of previous layers to supplement them and eliminate the differences between features. These refined features will go through multiple similar iterations before generating the final saliency maps. Furthermore, different from binary cross entropy, the proposed PPA loss doesn’t treat pixels equally, which can synthesize the local structure information of a pixel to guide the network to focus more on local details. Hard pixels from boundaries or error-prone parts will be given more attention to emphasize their importance. F3Net is able to segment salient object regions accurately and provide clear local details. Comprehensive experiments on five benchmark datasets demonstrate that F3Net outperforms state-of-the-art approaches on six evaluation metrics.
git clone git@github.com:weijun88/F3Net.git
cd F3Net/Download the following datasets and unzip them into data folder
- If you want to test the performance of F3Net, please download the model into
outfolder - If you want to train your own model, please download the pretrained model into
resfolder
cd src/
python3 train.pyResNet-50is used as the backbone of F3Net andDUTS-TRis used to train the modelbatch=32,lr=0.05,momen=0.9,decay=5e-4,epoch=32- Warm-up and linear decay strategies are used to change the learning rate
lr - After training, the result models will be saved in
outfolder
cd src
python3 test.py- After testing, saliency maps of
PASCAL-S,ECSSD,HKU-IS,DUT-OMRON,DUTS-TEwill be saved ineval/F3Net/folder.
- To evaluate the performace of F3Net, please use MATLAB to run
main.m
cd eval
matlab
main-
Quantitative comparisons
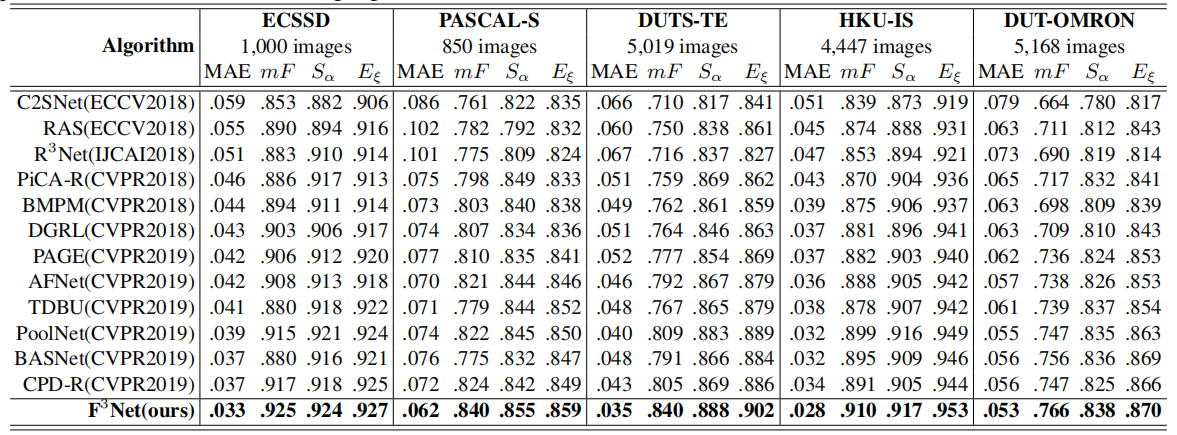
-
Qualitative comparisons



- If you find this work is helpful, please cite our paper
@inproceedings{F3Net,
title = {F3Net: Fusion, Feedback and Focus for Salient Object Detection},
author = {Jun Wei, Shuhui Wang, Qingming Huang},
booktitle = {AAAI Conference on Artificial Intelligence (AAAI)},
year = {2020}
}