使用标准输入,从URL或HTML文件中批量提取、筛选出指定标签内容,属性值及注释中的内容
建议:Linux/Mac下使用效果最佳
go install -v github.com/zha0gongz1/html-Absorber@latest
▶ html-Absorber
Usage: html-Absorber <mode> [<args>]
Modes:
tags <tag names> Extract text contained in tags
attribs <attrib names> Extract attribute values
comments Extract comments
Option:
-output Save the result to file
Examples:
cat urls.txt | html-Absorber tags title [-output]
find . -type f -name "*.html" | html-Absorber attribs src href [-output]
cat urls.txt | html-Absorber comments [-output]
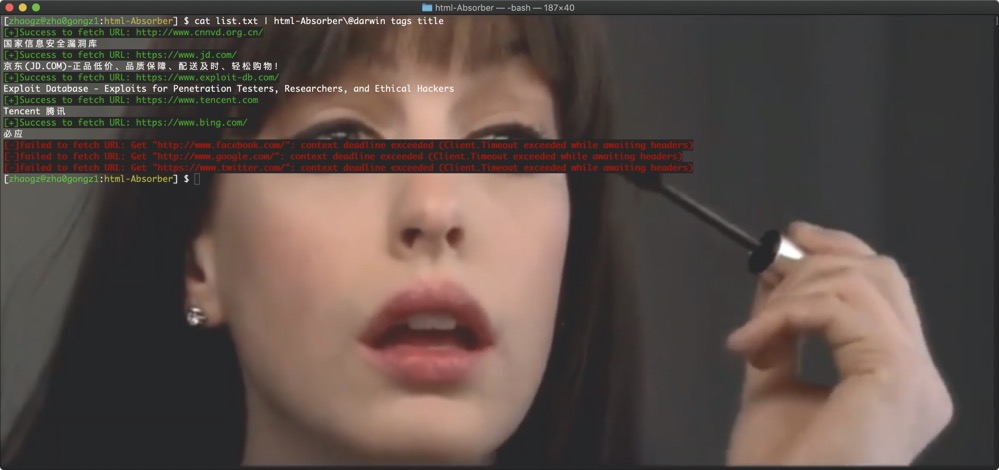
命令行输出结果
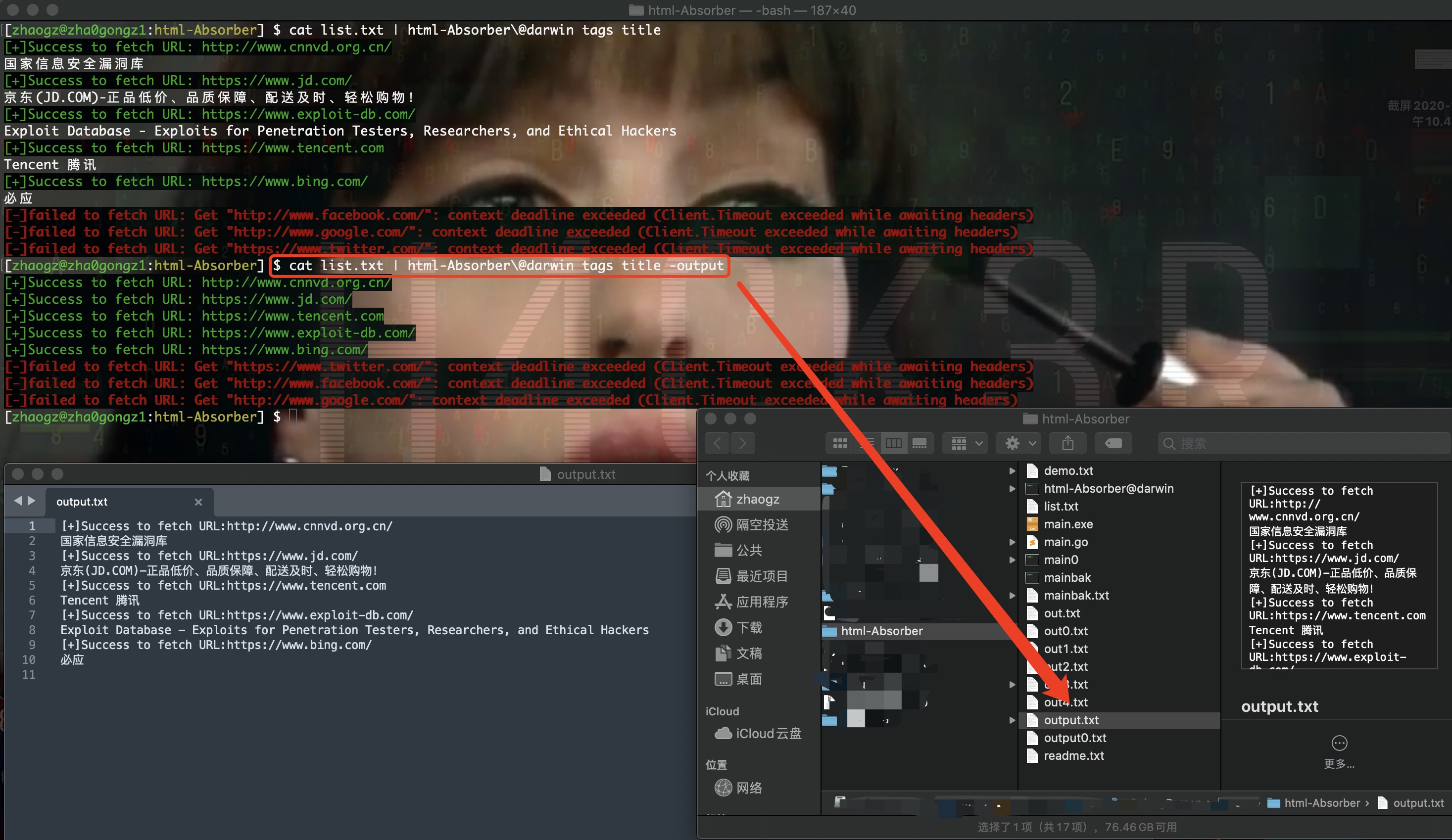
保存结果
注:-output为追加式输出到文件output.txt中。