date: 14 Nov 2019
task: Implement an n-gram algorithm (for 1,2 and 3-grams), and test it on a part of Turkish Novel Corpus, which includes 5 novels.
Definition:
There are 3 classes which Main, ngram and GUI.
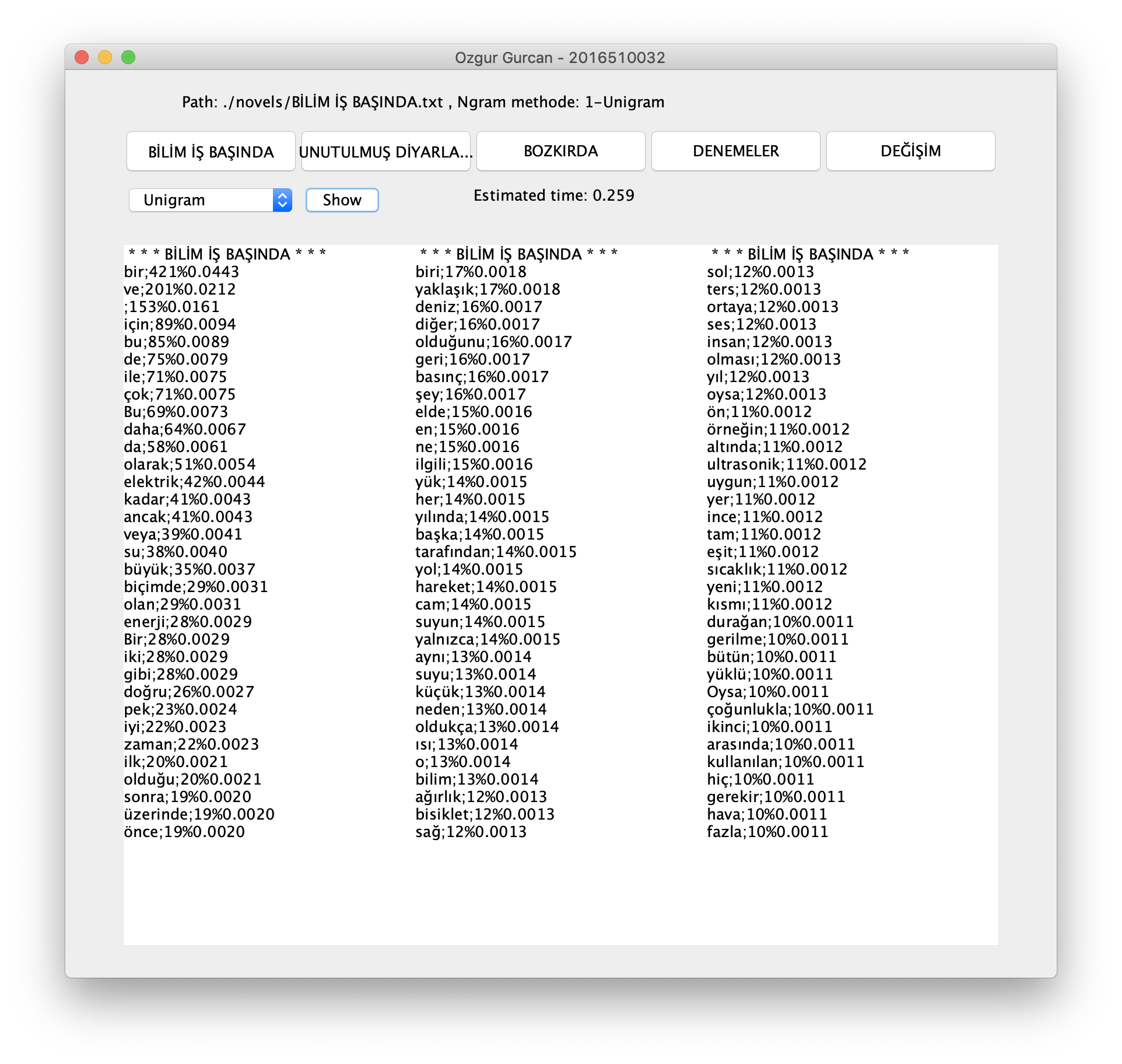
1-GUI Class
-5 Buttons for selecting different files - ("BİLİM İŞ BAŞINDA", "UNUTULMUŞ DİYARLAR", "BOZKIRDA", "DENEMELER", "DEĞİŞİM").
-Text area for listing items-number (top 99).
-Show button for calculating ngram.
-COmbo box for selecting Ngram type - ("Unigram", "Bigrams", "Trigrams").
-2 labels. First one for warnings and giving information to user about selected file path and ngram type.
The second one for to show estimated time.
2-ngram Class
There are 2 variable which count and ngram. ngram is a string which could be 1, 2 or 3 word length.
Count is a int whic desciribe how many times this ngram accured in the file
3-Main Class
readFileAsString method takes input as a path and than returns a string which all of the file=>(content).
ngrams method mothod takes 2 input: NgramMethode("Unigram", "Bigrams", "Trigrams") and content.
In this method content cleans and splits=>words[] and concats. Finaly returns a list=>(ngrams)
concat method takes content and length inputs for to append different words from array to each other.
(concat example: I have a very long string array words[] which have my words. In Trigram example I need to string which concat of words[x] words[x+1] and words[x+2].)
General idea for ngram: 1-Read file. 2-split into array. 3-concat for ngram type. 4-search each ngram in ngram list. 5-if found rise count else add to list. 6-short ngram list. 7-show top 99 with count.