This notebook explores a machine learning approach to the task of language identification on the Europarl corpus. The first section examines the dataset and prepares the data for training. Then, related studies on the task of language identification over this dataset will be introduced. Finally, I will introduce my approach to this problem, and present the results of my solution.
The Europarl corpus is a collection of transcripts in 21 languages from the proceedings of the European parliament. Transcripts appear to be organized by date, and stored in folders for each respective language. Each file contains the transcript text and XML tags representing additional information on the text. There is also an existing toolkit for transforming the text in the dataset. This corpus will be used for training a machine learning algorithm in this task.
The test data for this task is provided by startup.ml. It is a single text file containing sample label-sentence pairs for different languages, and each sample is stored in an individual line. For this task, I will train an algorithm and classify the language for each sentence in the test data. Since the test samples are sentences, it would be interesting to observe the performance of the algorithm on short test samples.
The training data contains XML tags, so we need to remove those tags from the
documents first.
We can achieve this by using the following command on each
document.
sed '/^<.*>/d' input_file > output_file
And the shell script de-XML-corpus.sh runs this command over all the files in
the corpus, then output the cleaned up files into another directory. The
resulting dataset is organized by the same directory structure as the original.
The source of the test file is unknown, therefore it is unclear whether the data in the test file exists within the Europarl corpus used for training. It would be too resource heavy to check whether the overlaps exist, due to the large size of the training data. Therefore, this task is based on the assumption that there are no overlaps between the training data and test data. Furthermore, my solution only trained an algorithm using a small subset of data randomly sampled from the whole dataset. The possibility that there is a significant overlap between the training and test data should be very low.
The best performance in Language Identification over this dataset seems to be
presented by Baldwin and Lui. They
achieved an accuracy of 0.993 using the toolkit
language-detection,
and an accuracy of 0.992 with langid.py
which they developed. language-detection uses a Naive Bayes classifier
trained with character langid.py uses a multinomial Naive
Bayes classifier trained over byte n-grams.
Neither of the toolkits is trained purely on the Europarl corpus, and it is unclear whether the test data used is the same as the test set in this task.
For this task, I chose to train a multinomial Naive Bayes classifier on byte
I used scikit-learn's
HashingVectorizer
to convert documents into feature vectors, and its Multinomial Naive Bayes
Classifier
as the learning algorithm.
The feature extraction function is as follows:
def get_byte_n_grams(text, n_gram_range=(1,1)):
text_bytes = bytes(text, 'utf-8')
ngrams=[]
beg, end=n_gram_range
for i in range(beg,end+1):
ngrams.extend(get_n_grams(text_bytes, i))
return map(to_string, ngrams)
def to_string(ngram):
return " ".join(map(str, ngram))
def get_n_grams(seq, n):
return zip(*[seq[i:] for i in range(n)])get_byte_n_grams converts the text string into bytes, then returns the literal string representations of these n-grams specified by n_gram_range.
scikit-learn's HashingVectorizer can be initialized with a function, and
use it to convert a document into a vector representation. For this task, I
used the vectorizer to extract byte
def byte_1_4_gram_analyzer(x):
return get_byte_n_grams(x, n_gram_range=(1,4))Since we need the same vectorizer object for both training and testing, the following class is defined for the purpose of packaging a vectorizer and classifier together. After training, the trained instance of this class is pickled. For testing, the pickled object is loaded back into memory, and it is able to convert the test samples into vectors using the same vectorizer.
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.naive_bayes import MultinomialNB
class LanguageClassifier:
def __init__(self, feature_function):
self.vectorizer = HashingVectorizer(analyzer=feature_function,
norm=None,
non_negative='total')
self.classifier = MultinomialNB()
def partial_train(self, samples, labels, classes):
"""Partially train the algorithm, using MultinomialNB's partial_fit
method. Use this when the size of the training sample set is too big
and training on multiple batches is required.
"""
sample_vectors = self.vectorizer.fit_transform(samples)
self.classifier.partial_fit(sample_vectors, labels, classes)
def train(self, samples, labels):
sample_vectors = self.vectorizer.fit_transform(samples)
self.classifier.fit(sample_vectors, labels)
def predict(self, samples):
sample_vectors = self.vectorizer.transform(samples)
return self.classifier.predict(sample_vectors)Even though I attempted to train the model using batches of the training data, training on the whole dataset appeared to be too memory-intensive for my local machine. Therefore, I tried training on subsets of various sizes from the whole dataset. The training processes are carried out by the following script:
import os, sys
from lang_classifier import LanguageClassifier
from analyzer import byte_1_4_gram_analyzer
import random
import pickle
doc_directory = sys.argv[1]
classifier_output = sys.argv[2]
TRAIN_SIZE=int(sys.argv[3])
classifier = LanguageClassifier(byte_1_4_gram_analyzer)
# get the list of folders in the training set
lang_folders = os.listdir(doc_directory)
for l in lang_folders:
print("Training with files in folder {}".format(l))
folder_path = os.path.join(doc_directory, l)
files = os.listdir(folder_path)
random.seed(1)
samples = []
labels = []
for f in random.sample(files, TRAIN_SIZE):
file_path = os.path.join(folder_path, f)
with open(file_path) as sample:
samples.append(sample.read())
labels.append(l)
classifier.partial_train(samples, labels, lang_folders)
with open(classifier_output, 'wb') as out:
pickle.dump(classifier, out)The script randomly samples a subset with a user-specified size from each language's folder. Then uses the sampled documents to train the classifier. The trained classifier is then pickled for later testing.
The script evaluate.py tests a pickled classifier on the test data, then
prints out its performance. The testing results are presented in the next
section.
As mentioned above, I only used randomly sampled small portions of the whole
dataset to train the algorithm. Multiple experiments have been done using a
training set of sizes ranging from 50 documents per language to 800, with
increments of 50. The following graph shows the growth of classifier accuracy
as the size of the training data grows.
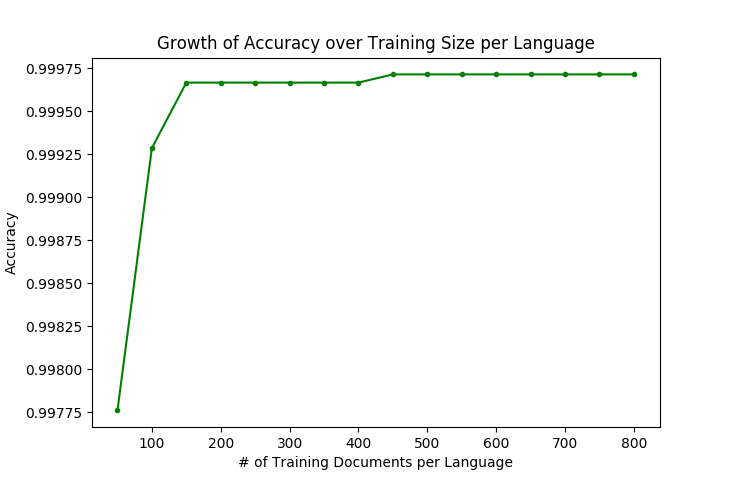
It shows that, the accuracy increases as the size of the training data gets
bigger. However, there is not a significant gain after the training data size
becomes several hundred documents per language.
The maximum training data size was 800 documents per language. The trained algorithm achieved the accuracy of 0.9997 on the test data.
More detailed reports on the performance of each trained classifier can be
found in the folder \results. The name of each .txt file is the number of
documents per language used for training the corresponding model.
The test result shows that, the algorithm is able to achieve high accuracy on classifying short sentences. In addition, the classifier's accuracy is higher than langid.py's 0.992, and language-detection's 0.993. However, this does not prove that this classifier is better than the other toolkits: it is unclear that whether the test data used in the evaluation of the two language identifiers are the same as the one used in this task; those toolkits are also trained on a datasets that have a much wider range of domains and can be used for general purposes.
For future work, we could focus on domain adaptation and train the classifier on a wider range of documents from different domains. In addition, the topic of language identification on text that contains text from other languages seems to be popular in this field, and it would be interesting to see the performance of this classifier on such data, and find ways to adapt the classifier to such problems.