![]()
NeutronStar is a distributed Graph Neural Networks (GNN) training framework that supports CPU-GPU heterogeneous computation on multiple workers.
NeutronStar distinguishes itself from other GNN training frameworks with the following new properties:
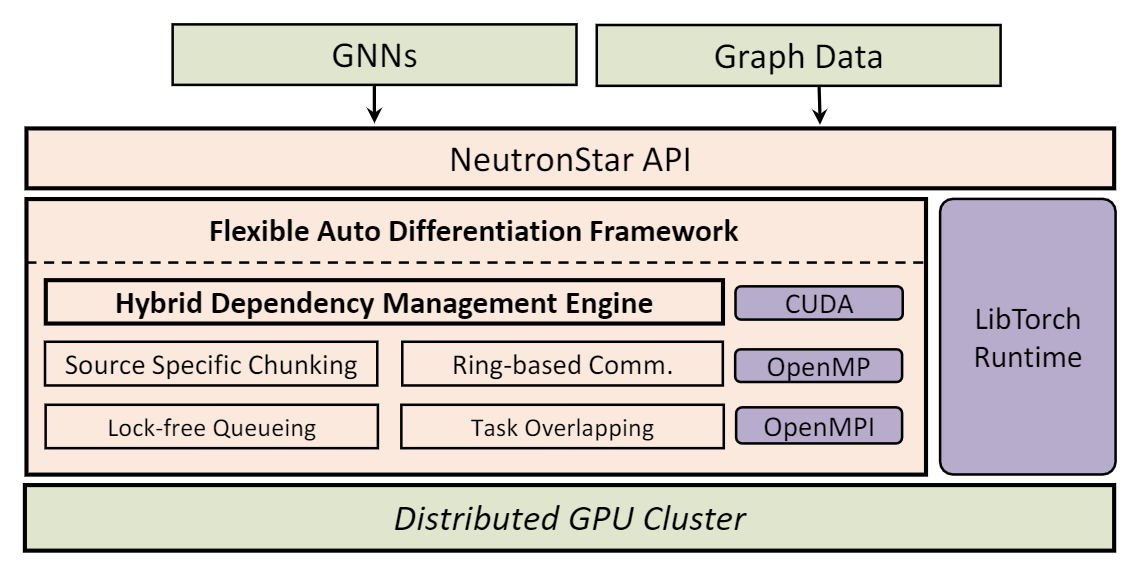
- The dependency management (how to acquire the embeddings and gradients from neighbors) plays a key role in distributed GNN training. NeutronStar combines the cache-based dependency management that are adopted by DGL and Aligraph and the communication-based dependency management method that are widely adopted by traditional graph computing systems, and proposes a hybrid dependency management GNN distributed training system. NeutronStar can determine the optimal way to acquire the embeddings (during forward propagation) and the gradients (during backward propagation) from neighboring vertices.
- NeutronStar integrates the pytorch automatic differentiation library libtorch and tensorflow to support automatic differentiation (automatic backpropagation) across workers.
- NeutronStar is enhanced with many optimization techniques from traditional distributed graph computing systems to effectively accelerate the performance of distributed GNN training, such as CPU-GPU I/O optimization, Ring-based Communication, Overlapping Communication with Computation, Lock-free Parallel Message Enqueuing, and so on.
- NeutronStar shows better performance than many state-of-the-art GNN training systems. The following figure shows the performance comparison. DistDGL is a distributed version of DGL system. ROC is a system originated from Stanford. DepCache is a variantion of NeutronStar that acquires dependencies by caching. DepComm is a variantion of NeutronStar that acquires dependencies from remote servers.

The overall architecture of NeutronStar
A compiler supporting OpenMP and C++11 features (e.g. lambda expressions, multi-threading, etc.) is required.
cmake >=3.14.3
MPI for inter-process communication
cuda > 9.0 for GPU based graph operation.
libnuma for NUMA-aware memory allocation.
cub for GPU-based graph propagation
sudo apt install libnuma-dev"
libtorch version > 1.7 with gpu support for nn computation
unzip the libtorch package in the root dir of NeutronStar and change CMAKE_PREFIX_PATH in "CMakeList.txt"to your own path
download cub to the ./NeutronStar/cuda/ dictionary.
configure PATH and LD_LIBRARY_PATH for cuda and mpi
export CUDA_HOME=/usr/local/cuda-10.2
export MPI_HOME=/path/to/your/mpi
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
export PATH=$MPI_HOME/bin:$CUDA_HOME/bin:$PATH
clang-format is optional for auto-formatting:
sudo apt install clang-formatconfigure "CUDA_ENABLE" flag in ./cuda/cuda_type.h (line 20) to '1' or '0' to enable or disable GPU compilation.
To build:
mkdir build
cd build
cmake ..
make -j4
To run:
List all nodes in ./NeutronStar/hostfile for MPI communication
ip1
ip2
ip3
copy NeutronStar to all your machines(copy_all.sh and make_and_copy.sh) and run the following command in your root DIR.
single-machine multi-slots:(strongly recommand use one slot, except for debugging)
./run_nts.sh $slot_number $configure_file
./run_nts.sh 1 gcn_cora.cfg
distributed:
./run_nts_dist.sh $nodes_number $configure_file
./run_nts_dist.sh 2 gcn_cora.cfg
ENGINE TYPE: We list serveral example in the root dir for your reference GCN: gcn_cora.cfg
gcn_pubmed.cfg
gcn_citeseer.cfg
gcn_reddit.cfg
gcn_reddit_full.cfg
Instead use printf in your code, use LOG_* macros for logging infomation like this
LOG_DEBUG("Train Acc %f", acc);To enable logger in your code, you will need to reconfigure it like this:
cmake -D CMAKE_BUILD_TYPE=Debug ..This will turn on debug mode, and those debug messages will print out.
The different logging levels is defined in common/logger.h. After enable logging, the default logging level is LOG_LEVEL_INFO. Any logging method with a level that is higher than or equal to LOG_LEVEL_INFO(e.g. LOG_INFO, LOG_WARN, LOG_ERROR) will emit logging information.
You can also simply disable logging to improve the runtime performance
currently, debug mode in our project is not stable
You can choose your own preference on code formatting Here's an example first dump clang format configuration
clang-format -style=google -dump-config > .clang-formatyou can pick your favourite style. e.g. llvm, google
open the .clang-format and change the configuration
e.g. if you want to change indention, find IndentWidth and change to what you want
More information can be found at this website
Then run make format, you should be able to see the changes.
You can refer to this guide to install CUDA
You can refer to this guide to install cuDNN
You can find libtorch at this website
Use this command to install libnuma
sudo apt install libnuma-devUse this command to install mpi
sudo apt install mpichRemember to set environment variables mentioned above.
if there are any problems, please contact 1173886760@qq.com