这里写一下lab4 shardkv的思路吧,感觉如果不好好想一下设计细节的话写代码的时候就很容易乱套
目标就是完成所有的part,所以后面的选做部分也要实现(其实感觉不实现那我们的代码就太玩具了)
每个shard不能干扰其他的shard,比如一个shard正在等待数据,他是不能干扰其他shard完成正常操作的。所以我们分别维护每个shard的状态。每个shard有自己的map
去重表,可以放在shard外面也可以放在shard里面,我这里就选择放在shard里面
有一个定时向shardctrler去pull config的线程
有一个定期检查shard状态的线程,当我们切换配置的时候,这个线程就负责去指定的raft组中去pull data,同时当接受到数据以后,这个线程也负责告诉之前持有数据的raft组他们可以删除这个数据了
并发的编程中,尤其是设计到分布式系统的时候,我们要考虑的情况都非常的多。导致思维难度很高。所以我们要去找一些特殊的方法去思考这个系统的设计。
从s6.081的老师学到的就是维护invariant。我们找到我们要维护的invariant,然后再根据这个前提去不断的思考其他的步骤。以及思考如何去维护invariant
在这个lab中,我们的关键就是config的版本。我们肯定不能保证所有raft group的配置都是相同的,因为他们不论是拉取数据还是提交配置都是需要时间的。所以这里维护的是在不出现集群失效的情况下,不同的raft group的配置最多相差一个版本。
比如目前的版本号都是1,然后master提交了一个新的配置2,此时所有的raft group都会先后的拉取到这个配置2,并开始提交。raft group会在不同的时间进入到配置2中。但是这时配置切换并没有结束。因为我们需要去移动shard。当shard都移动结束后,配置切换才算完成。这是raft group才允许去向master拉取新的配置
维护没一个shard的状态。当一个raft group中的所有数据都处于有效或无效的状态(i.e. 不在配置切换的过渡期),才允许daemon去拉取新的配置。这样可以保证每个raft group不会在切换配置的中间状态切换到新的配置,导致维护的ivariant失效
在每个raft group的视角来看,他们都是保证了自己当前配置下的数据要么已经被迁移到了对应的节点,要么是正在服务的状态。当和当前raft group相关的数据迁移都已经完成的时候,他们才可以切换到新的配置。
所以我们还需要一个可以合理表示当前shard状态的状态机。从而可以让raft group确保维护的invariant不会失效
首先是valid和invalid的状态,对应了非配置切换时的状态(i.e. 非中间状态)
当shard需要向其他的raft group请求数据的时候,我们需要有一个状态来让daemon去帮我们请求数据。
看起来差不多了,但其实还不够,因为当一个raft group不需要请求新的数据的时候,他也不能随意的切换到新的配置。因为有可能有其他的raft group请求他的数据。上面说了,只有数据迁移与他无关时他才能切换配置。所以我们还需要维护这个数据是否是要被其他的group请求的数据
但是新的问题又出现了,我们怎么确保这个被拉走的数据已经被提交了呢?因为当start失败,或者由于一些其他的原因导致日志没能提交的时候,之前我们有客户端在不断的重试。所以我们不能让数据一被拉走就删除,我们还需要让新的group告诉我们,他已经成功apply了这个数据,我们现在可以删除了。
所以我们还需要一个状态表示当成功apply了以后,这个数据是需要去告知原group我们apply成功的。但是为什么需要一个状态呢?我们难道不能在提交的时候就去RPC告诉原group我们成功了吗?其实不能,和上面的原因相同,删除数据是需要组内同步的一个操作,所以需要commit,但是由于commit不确定会成功,所以需要一个daemon去重试。直到我们确定了数据已经被删除为止。
当确定数据被删除了以后,我们就可以提交一个确认删除的log,从而让当前raft group的这个shard完成配置过渡
通过状态机来表示一下上面说到的思路
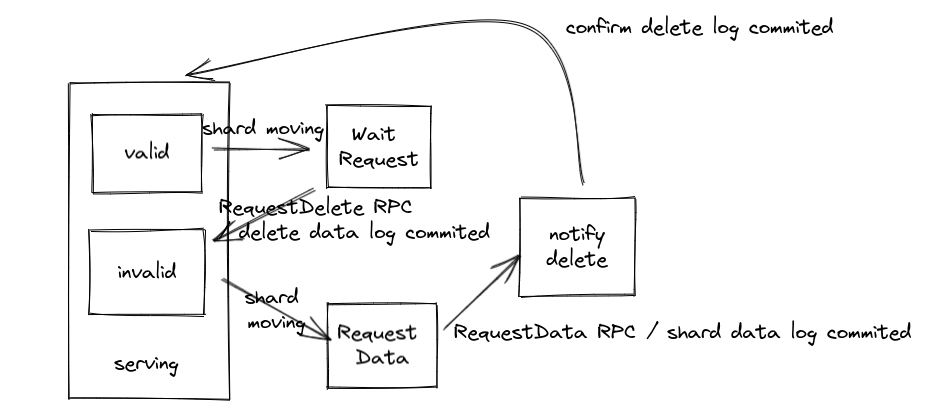
当服务器是在serving的状态中,每个shard是valid或者invalid,表示当前服务器负责这个shard或者不负责这个shard
当我们pull到了新的config的时候,就会尝试提交。config提交时就会应用到服务器中,这时我们就进入了配置过渡的状态。每个shard根据自己的情况,可能变成Wait Request状态,或者变成Request Data状态
这时后台线程就负责去请求shard数据,RequestData状态的shard就会通过RequestData RPC来请求数据,并commit这个数据。当数据成功apply到服务器中时,他就会转换到notify delete状态,表示要告知原服务器删除这个shard的数据。
WaitRequest的shard则等待notify delete状态的shard向自己发送RequestDelete RPC,并提交删除数据的log。当成功apply时,他就会删除数据并转化为invalid的状态。
notify delete状态的shard会不断尝试RPC,直到他发现目标地点的数据已经被删除了(apply了log),他就会返回并提交一个确认删除的log,当log apply时,就会从notify delete状态转化为valid的状态。
由于我们需要每个节点的数据都是一致的,所以涉及到状态的变更这些操作都需要通过log达成共识