leetcode1023 Www112233
1、基本概念 动态规划(Dynamic Programming)对于子问题重叠的情况特别有效,因为它将子问题的解保存在表格中,当需要某个子问题的解时,直接取值即可,从而避免重复计算!
动态规划是一种灵活的方法,不存在一种万能的动态规划算法可以解决各类最优化问题(每种算法都有它的缺陷)。所以除了要对基本概念和方法正确理解外,必须具体问题具体分析处理,用灵活的方法建立数学模型,用创造性的技巧去求解。
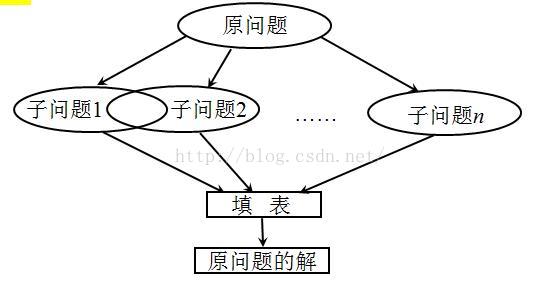
2、基本**与策略 基本**与分治法类似,也是将待求解的问题分解为若干个子问题(阶段),按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各子问题,最后一个子问题就是初始问题的解。 动态规划中的子问题往往不是相互独立的(即子问题重叠)。在求解的过程中,许多子问题的解被反复地使用。为了避免重复计算,动态规划算法采用了填表来保存子问题解的方法。
3、适用的情况 1)两个必备要素
适合应用动态规划方法求解的最优化问题应该具备两个重要的要素:最优子结构和子问题重叠。
(a)最优子结构:问题的最优解由相关子问题的最优解组合而成,并且可以独立求解子问题!
(b)子问题重叠:递归过程反复的在求解相同的子问题。
2)三个性质
能采用动态规划求解的问题的一般要具有3个性质:
(a) 最优化原理:如果问题的最优解所包含的子问题的解也是最优的,就称该问题具有最优子结构,即满足最优化原理。
(b) 无后效性:即某阶段状态(定义的新子问题)一旦确定,就不受这个状态以后决策的影响。也就是说,某状态以后的过程不会影响以前的状态,只与其以前的状态有关。
(c)有重叠子问题:即子问题之间是不独立的(分治法是独立的),一个子问题在下一阶段决策中可能被多次使用到。(该性质并不是动态规划适用的必要条件,但是如果没有这条性质,动态规划算法同其他算法相比就不具备优势)
4、求解的基本步骤 实际应用中可以按以下几个简化的步骤进行设计:
(1)分析最优解的性质,并刻画其结构特征,这一步的开始时一定要从子问题入手。
(2)定义最优解变量,定义递归最优解公式。
(3)以自底向上计算出最优值(或自顶向下的记忆化方式(即备忘录法))
(4)根据计算最优值时得到的信息,构造问题的最优解
二,动态规划的自我总结
实际上动态规划的问题就是在牺牲一定量的内存存储子问题的计算结果,从而未来需要这些信息时不再重复计算,直接获取计算过的结果即可。其实动态规划的问题不好想,除非递推公式比较明显。
上面已经知道动态规划算法的核心是记住已经求过的解,记住求解的方式有两种:①自顶向下的备忘录法 ②自底向上。 为了说明动态规划的这两种方法,举一个最简单的例子:求斐波拉契数列Fibonacci 。先看一下这个问题:
Fibonacci (n) = 1; n = 0 Fibonacci (n) = 1; n = 1 Fibonacci (n) = Fibonacci(n-1) + Fibonacci(n-2)

上面的递归树中的每一个子节点都会执行一次,很多重复的节点被执行,fib(2)被重复执行了5次。由于调用每一个函数的时候都要保留上下文,所以空间上开销也不小。这么多的子节点被重复执行,如果在执行的时候把执行过的子节点保存起来,后面要用到的时候直接查表调用的话可以节约大量的时间。
leetcode解题之53 # Maximum Subarray Java版
Find the contiguous subarray within an array (containing at least one number) which has the largest sum.
For example, given the array [-2,1,-3,4,-1,2,1,-5,4], the contiguous subarray [4,-1,2,1] has the largest sum = 6.
第一种:
题解:
这道题要求 求连续的数组值,加和最大。
试想一下,如果我们从头遍历这个数组。对于数组中的其中一个元素,它只有两个选择:
-
要么加入之前的数组加和之中(跟别人一组)
-
要么自己单立一个数组(自己单开一组)
所以对于这个元素应该如何选择,就看他能对哪个组的贡献大。如果跟别人一组,能让总加和变大,还是跟别人一组好了;如果自己起个头一组,自己的值比之前加和的值还要大,那么还是自己单开一组好了。
所以利用一个sum数组,记录每一轮sum的最大值,sum[i]表示当前这个元素是跟之前数组加和一组还是自己单立一组好,
/**
Given an integer array nums, find the contiguous subarray (containing at least one number) which has the largest sum and return its sum.
Example:
Input: [-2,1,-3,4,-1,2,1,-5,4],
Output: 6
Explanation: [4,-1,2,1] has the largest sum = 6.
Follow up:
If you have figured out the O(n) solution, try coding another solution using the divide and conquer approach, which is more subtle.
*/
public class MaximumSubarray {
public int maxSubArray(int[] nums) {
int[] sum = new int[nums.length];
int max = nums[0];
sum[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
sum[i] = Math.max(nums[i], sum[i - 1] + nums[i]);
max = Math.max(max, sum[i]);
}
return max;
}
}
-
找状态变量
-
初始化
-
转移方程
-
结果
Leetcode #62
/*
A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below).
The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked 'Finish' in the diagram below).
How many possible unique paths are there?
*
*
*
Example 1:
Input: m = 3, n = 2
Output: 3
Explanation:
From the top-left corner, there are a total of 3 ways to reach the bottom-right corner:
1. Right -> Right -> Down
2. Right -> Down -> Right
3. Down -> Right -> Right
Example 2:
Input: m = 7, n = 3
Output: 28
*/
public class UniquePaths {
public int uniquePaths(int m, int n) {
int[][] ways = new int[m][n];
for (int i = 0; i < m; i++) {
ways[i][0] = 1;
}
for (int i = 0; i < n; i++) {
ways[0][i] = 1;
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
ways[i][j] = ways[i][j - 1] + ways[i - 1][j];
}
}
return ways[m - 1][n - 1];
}
}leetcode # 63
/**
*
* @author younggg
* An obstacle and empty space is marked as 1 and 0 respectively in the grid.
Note: m and n will be at most 100.
Example 1:
Input:
[
[0,0,0],
[0,1,0],
[0,0,0]
]
Output: 2
Explanation:
There is one obstacle in the middle of the 3x3 grid above.
There are two ways to reach the bottom-right corner:
1. Right -> Right -> Down -> Down
2. Down -> Down -> Right -> Right
*/
public class UniquePathsII {
public int uniquePathsWithObstacles(int[][] obstacleGrid) {
int m = obstacleGrid.length;
int n = obstacleGrid[0].length;
int[][] ways = new int[m][n];
for (int i = 0; i < m; i++) {
if(obstacleGrid[i][0] == 1) {
break;
}
ways[i][0] = 1;
}
for (int i = 0; i < n; i++) {
if(obstacleGrid[0][i] == 1) {
break;
}
ways[0][i] = 1;
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if(obstacleGrid[i][j] == 1) {
continue;
}
ways[i][j] = ways[i - 1][j] + ways[i][j - 1];
}
}
return ways[m - 1][n - 1];
}
}LeetCode #64
LeetCode # 70
/**
*
* @author younggg
*
You are climbing a stair case. It takes n steps to reach to the top.
Each time you can either climb 1 or 2 steps.
In how many distinct ways can you climb to the top?
Note: Given n will be a positive integer.
Example 1:
Input: 2
Output: 2
Explanation: There are two ways to climb to the top.
1. 1 step + 1 step
2. 2 steps
Example 2:
Input: 3
Output: 3
Explanation: There are three ways to climb to the top.
1. 1 step + 1 step + 1 step
2. 1 step + 2 steps
3. 2 steps + 1 step
*/
public class ClimbingStairs {
public static int climbStairs(int n) {
if(n == 1) {
return 1;
}
if(n == 2) {
return 2;
}
int cur = 2;
int prev = 1;
for (int i = 0; i <= n; i++) {
cur = cur + prev;
prev = cur - prev;
}
return cur;
}
}贪心算法**:
顾名思义,贪心算法总是作出在当前看来最好的选择。**也就是说贪心算法并不从整体最优考虑,**它所作出的选择只是在某种意义上的局部最优选择。当然,**希望贪心算法得到的最终结果也是整体最优的。**虽然贪心算法不能对所有问题都得到整体最优解,但对许多问题它能产生整体最优解。如单源最短路经问题,最小生成树问题等。在一些情况下,即使贪心算法不能得到整体最优解,其最终结果却是最优解的很好近似。
贪心算法的基本要素:
-
贪心选择性质。
**所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。**这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别。
动态规划算法通常以自底向上的方式解各子问题,而贪心算法则通常以自顶向下的方式进行,以迭代的方式作出相继的贪心选择,每作一次贪心选择就将所求问题简化为规模更小的子问题。
对于一个具体问题,要确定它是否具有贪心选择性质,必须证明每一步所作的贪心选择最终导致问题的整体最优解。
-
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。
问题的最优子结构性质是该问题可用动态规划算法或贪心算法求解的关键特征。
贪心算法的基本思路:
从问题的某一个初始解出发逐步逼近给定的目标,以尽可能快的地求得更好的解。当达到算法中的某一步不能再继续前进时,算法停止。
该算法存在问题:
- 不能保证求得的最后解是最佳的;
- 不能用来求最大或最小解问题;
- 只能求满足某些约束条件的可行解的范围。
实现该算法的过程:
从问题的某一初始解出发;
while 能朝给定总目标前进一步 do
求出可行解的一个解元素;
由所有解元素组合成问题的一个可行解;
用背包问题来介绍贪心算法:
背包问题:有一个背包,背包容量是M=150。有7个物品,物品可以分割成任意大小。要求尽可能让装入背包中的物品总价值最大,但不能超过总容量。
物品 A B C D E F G
重量 35 30 60 50 40 10 25
价值 10 40 30 50 35 40 30
分析如下
目标函数: ∑pi最大
约束条件是装入的物品总重量不超过背包容量:∑wi<=M( M=150)。
(1)根据贪心的策略,每次挑选价值最大的物品装入背包,得到的结果是否最优?
(2)每次挑选所占重量最小的物品装入是否能得到最优解?
(3)每次选取单位重量价值最大的物品,成为解本题的策略。
值得注意的是,贪心算法并不是完全不可以使用,贪心策略一旦经过证明成立后,它就是一种高效的算法。
贪心算法还是很常见的算法之一,这是由于它简单易行,构造贪心策略不是很困难。
可惜的是,它需要证明后才能真正运用到题目的算法中。
一般来说,贪心算法的证明围绕着:整个问题的最优解一定由在贪心策略中存在的子问题的最优解得来的。
对于背包问题中的3种贪心策略,都是无法成立(无法被证明)的,解释如下:
贪心策略:选取价值最大者。反例:
W=30
物品:A B C
重量:28 12 12
价值:30 20 20
根据策略,首先选取物品A,接下来就无法再选取了,可是,选取B、C则更好。
(2)贪心策略:选取重量最小。它的反例与第一种策略的反例差不多。
(3)贪心策略:选取单位重量价值最大的物品。反例:
W=30
物品:A B C
重量:28 20 10
价值:28 20 10
根据策略,三种物品单位重量价值一样,程序无法依据现有策略作出判断,如果选择A,则答案错误。但是果在条件中加一句当遇见单位价值相同的时候,优先装重量小的,这样的问题就可以解决.
广度优先搜索(也称宽度优先搜索,缩写BFS,以下采用广度来描述)是连通图的一种遍历策略。因为它的**是从一个顶点V0开始,辐射状地优先遍历其周围较广的区域,故得名。
一般可以用它做什么呢?一个最直观经典的例子就是走迷宫,我们从起点开始,找出到终点的最短路程,很多最短路径算法就是基于广度优先的**成立的。
算法导论里边会给出不少严格的证明,我想尽量写得通俗一点,因此采用一些直观的讲法来伪装成证明,关键的point能够帮你get到就好。
刚刚说的广度优先搜索是连通图的一种遍历策略,那就有必要将图先简单解释一下。

图2-1 连通图示例图
如图2-1所示,这就是我们所说的连通图,这里展示的是一个无向图,连通即每2个点都有至少一条路径相连,例如V0到V4的路径就是V0->V1->V4。
一般我们把顶点用V缩写,把边用E缩写。
常常我们有这样一个问题,从一个起点开始要到一个终点,我们要找寻一条最短的路径,从图2-1举例,如果我们要求V0到V6的一条最短路(假设走一个节点按一步来算)【注意:此处你可以选择不看这段文字直接看图3-1】,我们明显看出这条路径就是V0->V2->V6,而不是V0->V3->V5->V6。先想想你自己刚刚是怎么找到这条路径的:首先看跟V0直接连接的节点V1、V2、V3,发现没有V6,进而再看刚刚V1、V2、V3的直接连接节点分别是:{V0、V4}、{V0、V1、V6}、{V0、V1、V5}(这里画删除线的意思是那些顶点在我们刚刚的搜索过程中已经找过了,我们不需要重新回头再看他们了)。这时候我们从V2的连通节点集中找到了V6,那说明我们找到了这条V0到V6的最短路径:V0->V2->V6,虽然你再进一步搜索V5的连接节点集合后会找到另一条路径V0->V3->V5->V6,但显然他不是最短路径。
你会看到这里有点像辐射形状的搜索方式,从一个节点,向其旁边节点传递病毒,就这样一层一层的传递辐射下去,知道目标节点被辐射中了,此时就已经找到了从起点到终点的路径。
我们采用示例图来说明这个过程,在搜索的过程中,初始所有节点是白色(代表了所有点都还没开始搜索),把起点V0标志成灰色(表示即将辐射V0),下一步搜索的时候,我们把所有的灰色节点访问一次,然后将其变成黑色(表示已经被辐射过了),进而再将他们所能到达的节点标志成灰色(因为那些节点是下一步搜索的目标点了),但是这里有个判断,就像刚刚的例子,当访问到V1节点的时候,它的下一个节点应该是V0和V4,但是V0已经在前面被染成黑色了,所以不会将它染灰色。这样持续下去,直到目标节点V6被染灰色,说明了下一步就到终点了,没必要再搜索(染色)其他节点了,此时可以结束搜索了,整个搜索就结束了。然后根据搜索过程,反过来把最短路径找出来,图3-1中把最终路径上的节点标志成绿色。

整个过程的实例图如图3-1所示。
初始全部都是白色(未访问)
即将搜索起点V0(灰色)
已搜索V0,即将搜索V1、V2、V3
……终点V6被染灰色,终止
找到最短路径

图3-2 广度优先搜索的流程图
在写具体代码之前有必要先举个实例,详见第4节。
第一节就讲过广度优先搜索适用于迷宫类问题,这里先给出POJ3984《迷宫问题》。
《迷宫问题》
定义一个二维数组: int maze[5][5] = { 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, }; 它表示一个迷宫,其中的1表示墙壁,0表示可以走的路,只能横着走或竖着走,不能斜着走,要求编程序找出从左上角到右下角的最短路线。
题目保证了输入是一定有解的。
也许你会问,这个跟广度优先搜索的图怎么对应起来?BFS的第一步就是要识别图的节点跟边!
节点就是某种状态,边就是节点与节点间的某种规则。
对应于《迷宫问题》,你可以这么认为,节点就是迷宫路上的每一个格子(非墙),走迷宫的时候,格子间的关系是什么呢?按照题目意思,我们只能横竖走,因此我们可以这样看,格子与它横竖方向上的格子是有连通关系的,只要这个格子跟另一个格子是连通的,那么两个格子节点间就有一条边。
如果说本题再修改成斜方向也可以走的话,那么就是格子跟周围8个格子都可以连通,于是一个节点就会有8条边(除了边界的节点)。
对应于题目的输入数组:
0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0,
我们把节点定义为(x,y),(x,y)表示数组maze的项maze[x][y]。
于是起点就是(0,0),终点是(4,4)。按照刚刚的思路,我们大概手工梳理一遍:
初始条件:
起点Vs为(0,0)
终点Vd为(4,4)
灰色节点集合Q={}
初始化所有节点为白色节点
开始我们的广度搜索!
手工执行步骤【PS:你可以直接看图4-1】:
1.起始节点Vs变成灰色,加入队列Q,Q={(0,0)}
2.取出队列Q的头一个节点Vn,Vn={0,0},Q={}
3.把Vn={0,0}染成黑色,取出Vn所有相邻的白色节点{(1,0)}
4.不包含终点(4,4),染成灰色,加入队列Q,Q={(1,0)}
5.取出队列Q的头一个节点Vn,Vn={1,0},Q={}
6.把Vn={1,0}染成黑色,取出Vn所有相邻的白色节点{(2,0)}
7.不包含终点(4,4),染成灰色,加入队列Q,Q={(2,0)}
8.取出队列Q的头一个节点Vn,Vn={2,0},Q={}
9.把Vn={2,0}染成黑色,取出Vn所有相邻的白色节点{(2,1), (3,0)}
10.不包含终点(4,4),染成灰色,加入队列Q,Q={(2,1), (3,0)}
11.取出队列Q的头一个节点Vn,Vn={2,1},Q={(3,0)}
- 把Vn={2,1}染成黑色,取出Vn所有相邻的白色节点{(2,2)}
13.不包含终点(4,4),染成灰色,加入队列Q,Q={(3,0), (2,2)}
14.持续下去,知道Vn的所有相邻的白色节点中包含了(4,4)……
15.此时获得了答案
起始你很容易模仿上边过程走到终点,那为什么它就是最短的呢?
怎么保证呢?
我们来看看广度搜索的过程中节点的顺序情况:
图4-1 迷宫问题的搜索树
你是否观察到了,广度搜索的顺序是什么样子的?
图中标号即为我们搜索过程中的顺序,我们观察到,这个搜索顺序是按照上图的层次关系来的,例如节点(0,0)在第1层,节点(1,0)在第2层,节点(2,0)在第3层,节点(2,1)和节点(3,0)在第3层。
我们的搜索顺序就是第一层->第二层->第三层->第N层这样子。
我们假设终点在第N层,因此我们搜索到的路径长度肯定是N,而且这个N一定是所求最短的。
我们用简单的反证法来证明:假设终点在第N层上边出现过,例如第M层,M<N,那么我们在搜索的过程中,肯定是先搜索到第M层的,此时搜索到第M层的时候发现终点出现过了,那么最短路径应该是M,而不是N了。
所以根据广度优先搜索的话,搜索到终点时,该路径一定是最短的。
4.3.代码 我给出以下代码用于解决上述题目(仅仅只是核心代码):
/**
- 广度优先搜索
- @param Vs 起点
- @param Vd 终点
*/
bool BFS(Node& Vs, Node& Vd){
queue<Node> Q;
Node Vn, Vw;
int i;
//用于标记颜色当visiti==true时,说明节点访问过,也就是黑色
bool visitMAXL;
//四个方向
int dir = {
{0, 1}, {1, 0},
{0, -1}, {-1, 0}
};
//初始状态将起点放进队列Q
Q.push(Vs);
visitVs.x = true;//设置节点已经访问过了!
while (!Q.empty()){//队列不为空,继续搜索!
//取出队列的头Vn
Vn = Q.front();
Q.pop();
for(i = 0; i < 4; ++i){
Vw = Node(Vn.x+dir[i][0], Vn.y+dir[i][1]);//计算相邻节点
if (Vw == Vd){//找到终点了!
//把路径记录,这里没给出解法
return true;//返回
}
if (isValid(Vw) && !visit[Vw.x][Vw.y]){
//Vw是一个合法的节点并且为白色节点
Q.push(Vw);//加入队列Q
visit[Vw.x][Vw.y] = true;//设置节点颜色
}
}
}
return false;//无解
}5.核心代码 为了方便适用于大多数的题解,抽取核心代码如下:
/**
-
广度优先搜索
-
@param Vs 起点
-
@param Vd 终点 */ bool BFS(Node& Vs, Node& Vd){ queue Q; Node Vn, Vw; int i;
//初始状态将起点放进队列Q Q.push(Vs); hash(Vw) = true;//设置节点已经访问过了!
while (!Q.empty()){//队列不为空,继续搜索! //取出队列的头Vn Vn = Q.front();
//从队列中移除 Q.pop(); while(Vw = Vn通过某规则能够到达的节点){ if (Vw == Vd){//找到终点了! //把路径记录,这里没给出解法 return true;//返回 } if (isValid(Vw) && !visit[Vw]){ //Vw是一个合法的节点并且为白色节点 Q.push(Vw);//加入队列Q hash(Vw) = true;//设置节点颜色 } }} return false;//无解 }
对于一个题目来说,要标志节点是否访问过,用数组是一种很快速的方法,但有时数据量太大,很难用一个大数组来记录时,采用hash是最好的做法。实际上visit数组在这里也是充当hash的作用。(PS:至于hash是什么?得自己去了解,它的作用是在O(1)的时间复杂度内取出某个值)
6.其他实例 6.1.题目描述 给定序列1 2 3 4 5 6,再给定一个k,我们给出这样的操作:对于序列,我们可以将其中k个连续的数全部反转过来,例如k = 3的时候,上述序列经过1步操作后可以变成:3 2 1 4 5 6 ,如果再对序列 3 2 1 4 5 6进行一步操作,可以变成3 4 1 2 5 6.
那么现在题目就是,给定初始序列,以及结束序列,以及k的值,那么你能够求出从初始序列到结束序列的转变至少需要几步操作吗?
6.2.思路 本题可以采用BFS求解,已经给定初始状态跟目标状态,要求之间的最短操作,其实也很明显是用BFS了。
我们把每次操作完的序列当做一个状态节点。那每一次操作就产生一条边,这个操作就是规则。
假设起始节点是:{1 2 3 4 5 6},终点是:{3 4 1 2 5 6}
去除队列中的起始节点时,将它的相邻节点加入队列,其相邻节点就是对其操作一次的所有序列:
{3 2 1 4 5 6}、{1 4 3 2 5 6}、{1 2 5 4 3 6}、{1 2 3 6 5 4}
然后继续搜索即可得到终点,此时操作数就是搜索到的节点所在的层数2。
7.OJ题目 题目分类来自网络:
sicily:1048 1444 1215 1135 1150 1151 1114
pku:1136 1249 1028 1191 3278 1426 3126 3087 3414
8.总结 假设图有V个顶点,E条边,广度优先搜索算法需要搜索V个节点,因此这里的消耗是O(V),在搜索过程中,又需要根据边来增加队列的长度,于是这里需要消耗O(E),总得来说,效率大约是O(V+E)。
其实最影响BFS算法的是在于Hash运算,我们前面给出了一个visit数组,已经算是最快的Hash了,但有些题目来说可能Hash的速度要退化到O(lgn)的复杂度,当然了,具体还是看实际情况的。
BFS适合此类题目:给定初始状态跟目标状态,要求从初始状态到目标状态的最短路径。
9.扩展 进而扩展的话就是双向广度搜索算法,顾名思义,即是从起点跟终点分别做广度优先搜索,直到他们的搜索过程中有一个节点相同了,于是就找到了起点跟终点的一条路径。
腾讯笔试题目:假设每个人平均是有25个好友,根据六维理论,任何人之间的联系一定可以通过6个人而间接认识,间接通过N个人认识的,那他就是你的N度好友,现在要你编程验证这个6维理论。
此题如果直接做广度优先搜索,那么搜索的节点数可能达到25^6 如果是用双向的话,两个树分别只需要搜索到3度好友即可,搜索节点最多为25^3个,但是用双向广度算法的话会有一个问题要解决,就是你如何在搜索的过程中判断第一棵树中的节点跟第二棵树中的节点有相同的呢?按我的理解,可以用Hash,又或者放进队列的元素都是指向原来节点的指针,而每个节点加入一个color的属性,这样再搜索过程中就可以根据节点的color来判断是否已经被搜索过了。
深度优先搜索(缩写DFS)有点类似广度优先搜索,也是对一个连通图进行遍历的算法。它的**是从一个顶点V0开始,沿着一条路一直走到底,如果发现不能到达目标解,那就返回到上一个节点,然后从另一条路开始走到底,这种尽量往深处走的概念即是深度优先的概念。
你可以跳过第二节先看第三节,:)
还是引用上篇文章的样例图,起点仍然是V0,我们修改一下题目意思,只需要让你找出一条V0到V6的道路,而无需最短路。
图2-1 寻找V0到V6的一条路(无需最短路径)
假设按照以下的顺序来搜索:
1.V0->V1->V4,此时到底尽头,仍然到不了V6,于是原路返回到V1去搜索其他路径;
2.返回到V1后既搜索V2,于是搜索路径是V0->V1->V2->V6,,找到目标节点,返回有解。
这样搜索只是2步就到达了,但是如果用BFS的话就需要多几步。
2.2深度与广度的比较 (你可以跳过这一节先看第三节,重点在第三节)
从上一篇《【算法入门】广度/宽度优先搜索(BFS) 》中知道,我们搜索一个图是按照树的层次来搜索的。
我们假设一个节点衍生出来的相邻节点平均的个数是N个,那么当起点开始搜索的时候,队列有一个节点,当起点拿出来后,把它相邻的节点放进去,那么队列就有N个节点,当下一层的搜索中再加入元素到队列的时候,节点数达到了N2,你可以想想,一旦N是一个比较大的数的时候,这个树的层次又比较深,那这个队列就得需要很大的内存空间了。
于是广度优先搜索的缺点出来了:在树的层次较深&子节点数较多的情况下,消耗内存十分严重。广度优先搜索适用于节点的子节点数量不多,并且树的层次不会太深的情况。
那么深度优先就可以克服这个缺点,因为每次搜的过程,每一层只需维护一个节点。但回过头想想,广度优先能够找到最短路径,那深度优先能否找到呢?深度优先的方法是一条路走到黑,那显然无法知道这条路是不是最短的,所以你还得继续走别的路去判断是否是最短路?
于是深度优先搜索的缺点也出来了:难以寻找最优解,仅仅只能寻找有解。其优点就是内存消耗小,克服了刚刚说的广度优先搜索的缺点。
3.深度优先搜索
3.1.举例 给出如图3-1所示的图,求图中的V0出发,是否存在一条路径长度为4的搜索路径。
图3-1
显然,我们知道是有这样一个解的:V0->V3->V5->V6。
3.2.处理过程
3.3.对应例子的伪代码 这里先给出上边处理过程的对应伪代码。
/**
- DFS核心伪代码
- 前置条件是visit数组全部设置成false
- @param n 当前开始搜索的节点
- @param d 当前到达的深度,也即是路径长度
- @return 是否有解
*/
bool DFS(Node n, int d){
if (d == 4){//路径长度为返回true,表示此次搜索有解
return true;
}
for (Node nextNode in n){//遍历跟节点n相邻的节点nextNode,
if (!visit[nextNode]){//未访问过的节点才能继续搜索
//例如搜索到V1了,那么V1要设置成已访问
visit[nextNode] = true;
//接下来要从V1开始继续访问了,路径长度当然要加
if (DFS(nextNode, d+1)){//如果搜索出有解
//例如到了V6,找到解了,你必须一层一层递归的告诉上层已经找到解
return true;
}
//重新设置成未访问,因为它有可能出现在下一次搜索的别的路径中
visit[nextNode] = false;
}
//到这里,发现本次搜索还没找到解,那就要从当前节点的下一个节点开始搜索。
}
return false;//本次搜索无解
}3.4.DFS函数的调用堆栈
此后堆栈调用返回到V0那一层,因为V1那一层也找不到跟V1的相邻未访问节点
此后堆栈调用返回到V3那一层
此后堆栈调用返回到主函数调用DFS(V0,0)的地方,因为已经找到解,无需再从别的节点去搜别的路径了。
4.核心代码 这里先给出DFS的核心代码。
/**
-
DFS核心伪代码
-
前置条件是visit数组全部设置成false
-
@param n 当前开始搜索的节点
-
@param d 当前到达的深度
-
@return 是否有解 */ bool DFS(Node n, int d){ if (isEnd(n, d)){//一旦搜索深度到达一个结束状态,就返回true return true; }
for (Node nextNode in n){//遍历n相邻的节点nextNode if (!visit[nextNode]){// visit[nextNode] = true;//在下一步搜索中,nextNode不能再次出现 if (DFS(nextNode, d+1)){//如果搜索出有解 //做些其他事情,例如记录结果深度等 return true; }
//重新设置成false,因为它有可能出现在下一次搜索的别的路径中 visit[nextNode] = false; }} return false;//本次搜索无解 }
当然了,这里的visit数组不一定是必须的,在一会我给出的24点例子中,我们可以看到这点,这里visit的存在只是为了保证记录节点不被重新访问,也可以有其他方式来表达的,这里只给出核心**。
深度优先搜索的算法需要你对递归有一定的认识,重要的**就是:抽象!
可以从DFS函数里边看到,DFS里边永远只处理当前状态节点n,而不去关注它的下一个状态。
它通过把DFS方法抽象,整个逻辑就变得十分的清晰,这就是递归之美。
深度优先搜索算法(Depth-First-Search) 深度优先搜索算法(Depth-First-Search),是搜索算法的一种。它沿着树的深度遍历树的节点,尽可能深的搜索树的分 支。 当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。 这一过程一直进行到已发现从源节点可达的所有节点为止。 如果还存在未被发 现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。 深度优先搜索是图论中的经典算法,利用深度优先搜索算法可以产生目标图的相应拓扑排序表,利用拓扑排序表可以方便的解决很多相关的图论问题,如最大路径问题等等。一般用堆数据结构来辅助实现DFS算法。
**深度优先遍历图算法步骤:
- 访问顶点v;
- 依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
- 若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
>上述描述可能比较抽象,举个实例:
DFS 在访问图中某一起始顶点 v 后,由 v 出发,访问它的任一邻接顶点 w1;再从 w1 出发,访问与 w1邻 接但还没有访问过的顶点 w2;然后再从 w2 出发,进行类似的访问,… 如此进行下去,直至到达所有的邻接顶点都被访问过的顶点 u 为止。 接着,退回一步,退到前一次刚访问过的顶点,看是否还有其它没有被访问的邻接顶点。如果有,则访问此顶点,之后再从此顶点出发,进行与前述类似的访问;如果没有,就再退回一步进行搜索。重复上述过程,直到连通图中所有顶点都被访问过为止。
例如下图,其深度优先遍历顺序为 1->2->4->8->5->3->6->7