Exploring NiFi for Batch ETL. Summary
- Staging Table creation using Hive via Hue
- Initial load with NiFi with QueryDatabaseTable, ConvertRecord with AvroReader and CSVRecordSetWriter, followed by PutHDFS
- Data Profiling and Exploration with CDSW
- Data transformation or aggregation using PySpark invoked via ExecuteSparkInteractive through Livy
We will be using retail_db sample from Mysql installation.
Install using Fabio's OneNodeCDHCluster:
Download and Install Livy
wget https://www.apache.org/dyn/closer.lua/incubator/livy/0.6.0-incubating/apache-livy-0.6.0-incubating-bin.zip
unzip apache-livy-0.6.0-incubating-bin.zip
cd apache-livy-0.6.0-incubating-bin
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark
export HADOOP_CONF_DIR=/etc/hadoop/conf
sudo ln -s /etc/hive/conf/hive-site.xml $SPARK_HOME/conf
Edit livy.conf to enable HiveContext
cp $LIVY_HOME/conf/livy.conf.template $LIVY_HOME/conf/livy.conf
vi $LIVY_HOME/conf/livy.conf
Set the following config to true
livy.repl.enable-hive-context = true
Start Livy
./$LIVY_HOME/bin/livy-server start
Login to Hue. Use Hive editor, create staging database
CREATE DATABASE staging;
Create staging table for orders data
USE staging;
CREATE TABLE orders (
order_id INT
, order_date TIMESTAMP
, order_customer_id INT
, order_status VARCHAR(50)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
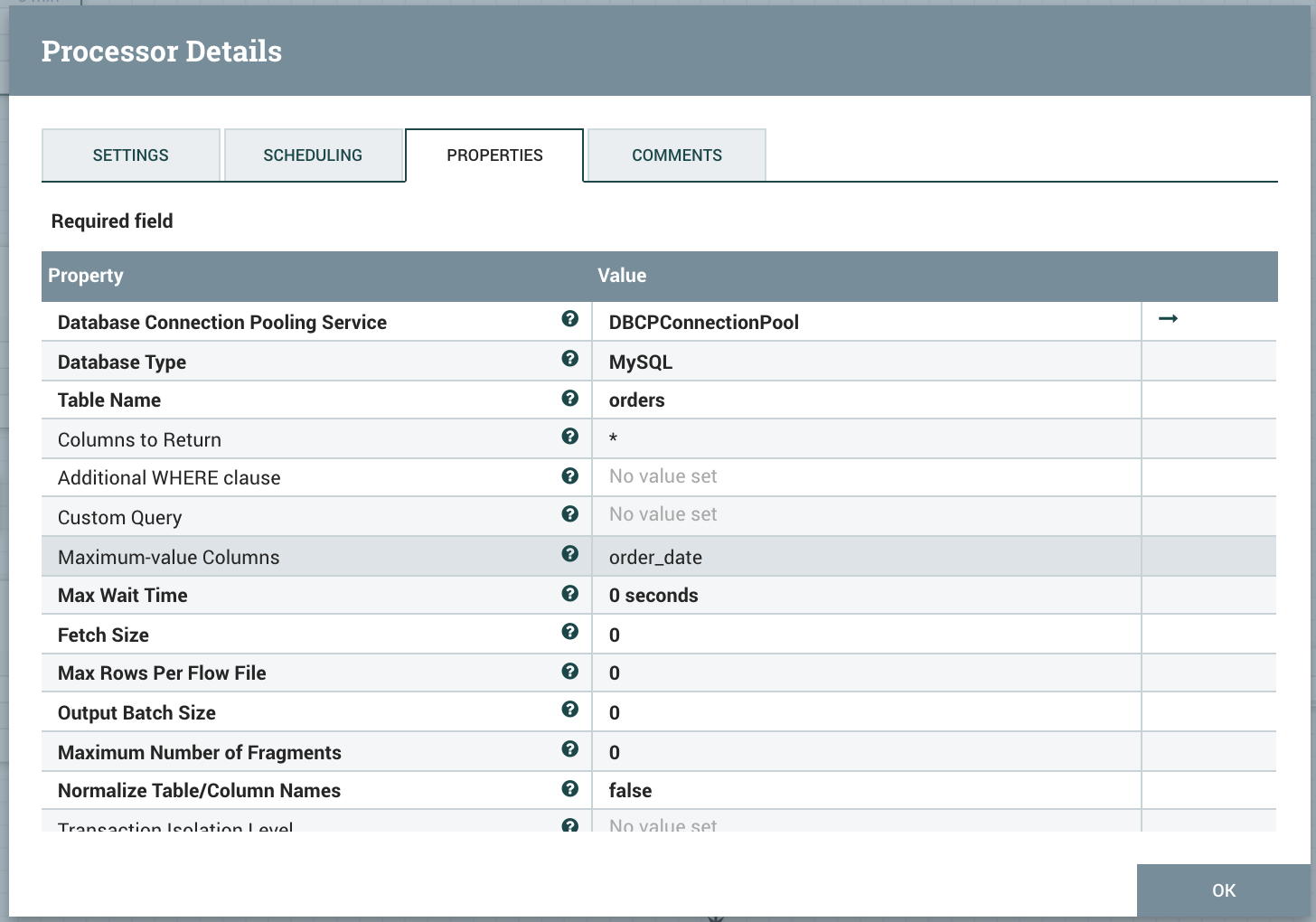
Use QueryDatabaseTable with Maximum-value column set to order_date.
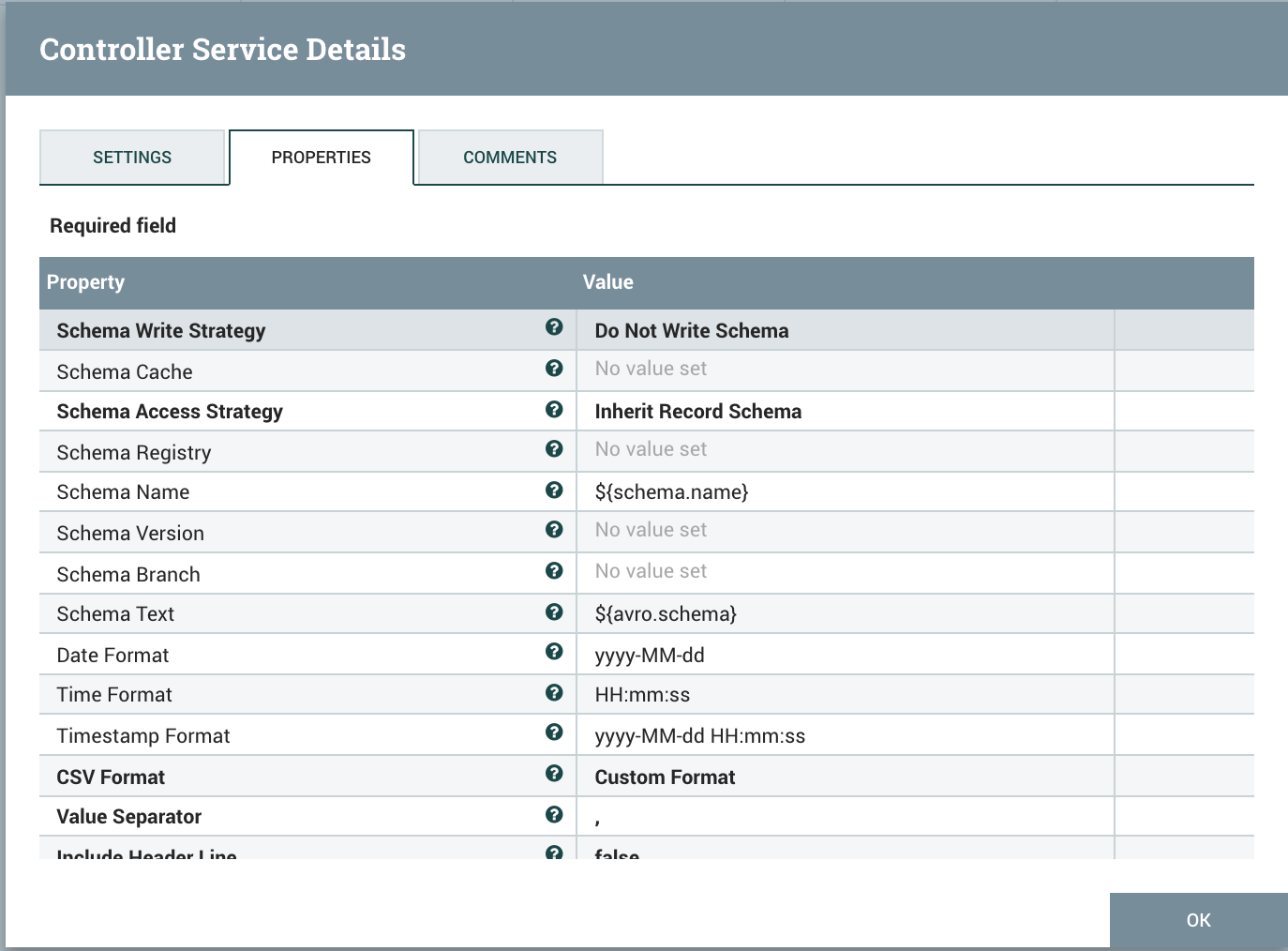
Use ConvertRecord with AvroReader and CSVRecordSetWriter controller service. Make sure the date, time, and timestamp format are properly set
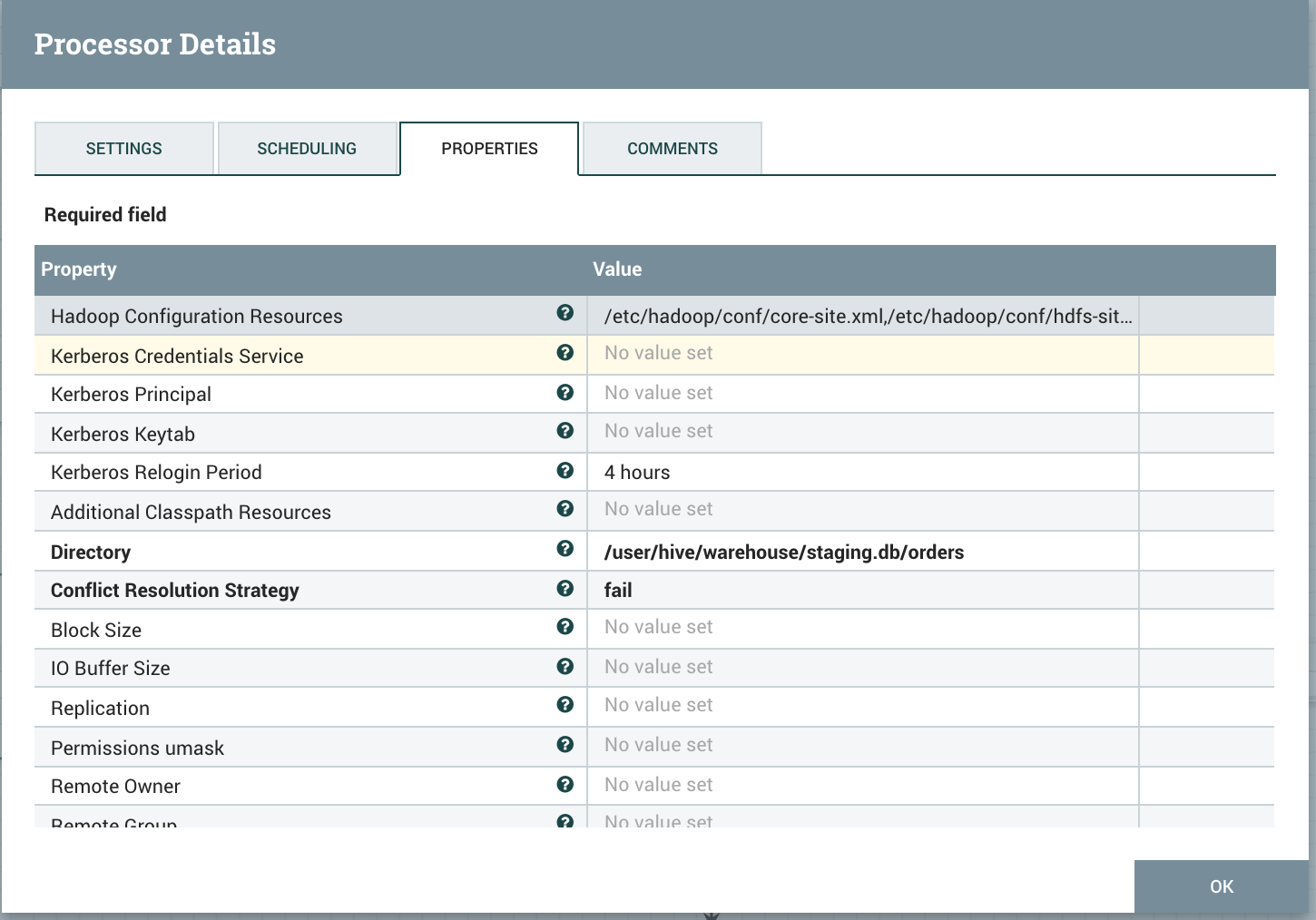
Link with PutHDFS
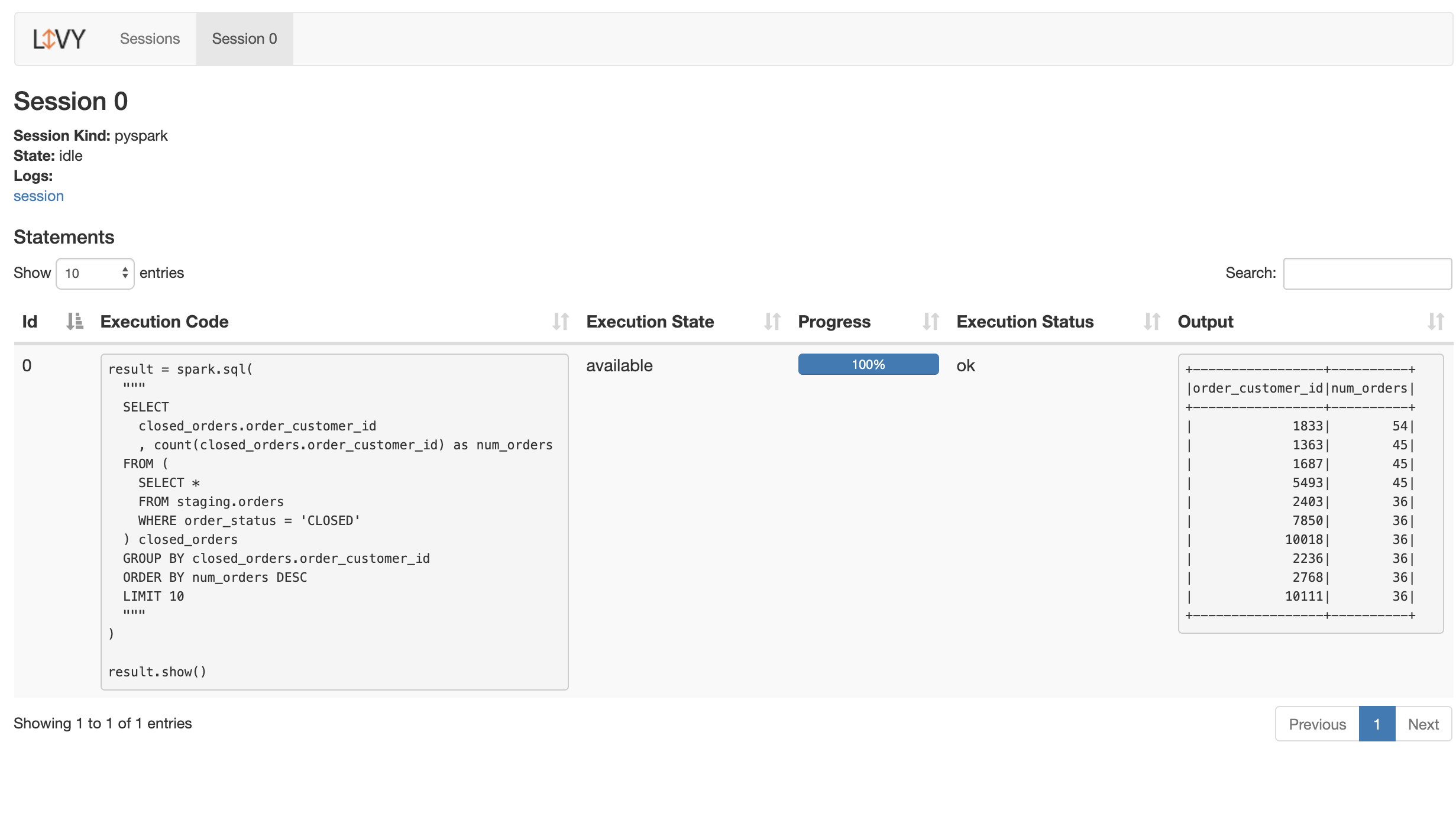
Create a transformation script using Pyspark
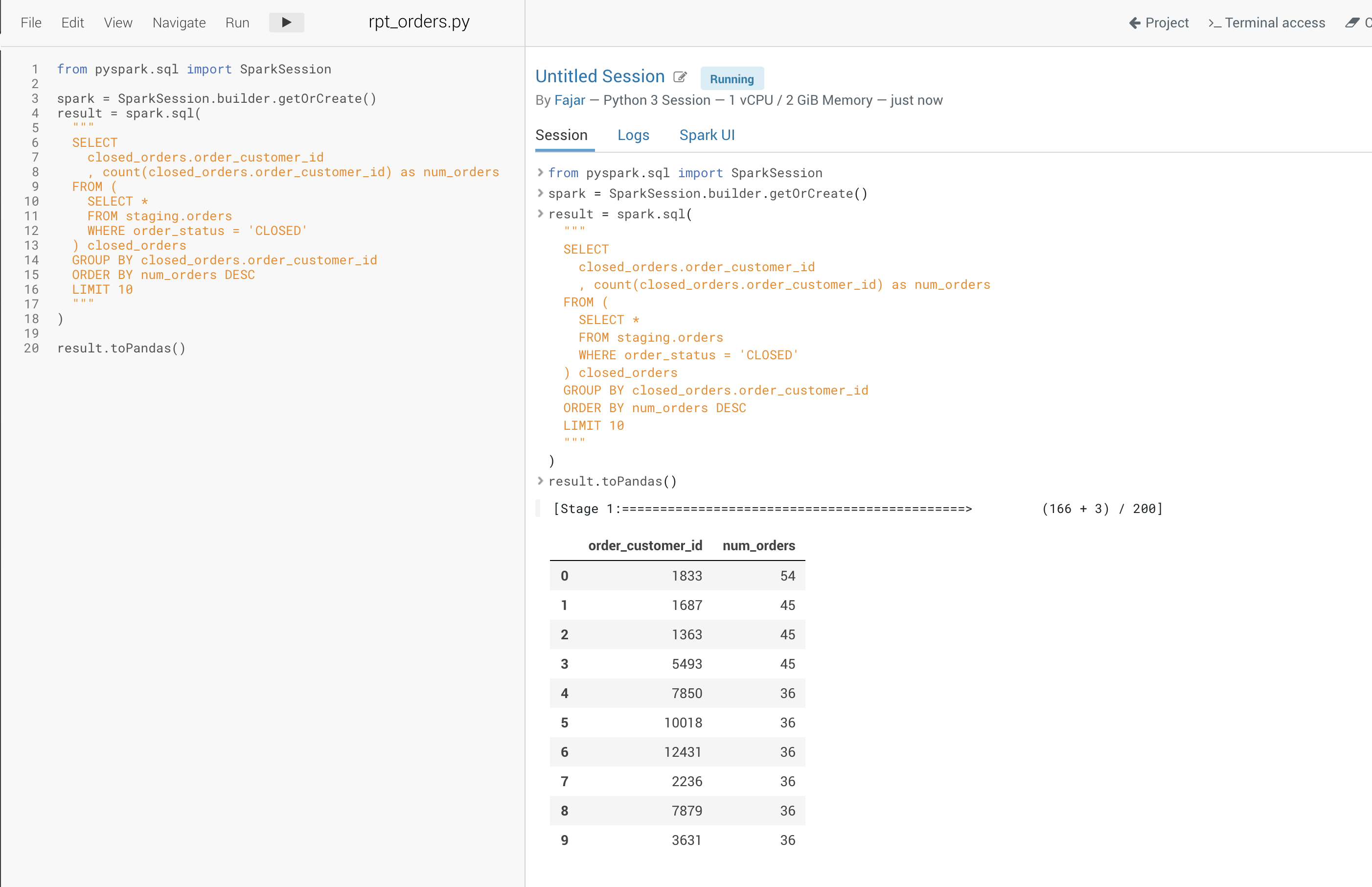
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
result = spark.sql(
"""
SELECT
closed_orders.order_customer_id
, count(closed_orders.order_customer_id) as num_orders
FROM (
SELECT *
FROM staging.orders
WHERE order_status = 'CLOSED'
) closed_orders
GROUP BY closed_orders.order_customer_id
ORDER BY num_orders DESC
LIMIT 10
"""
)
result.toPandas()
Link the PutHDFS with ExecuteSparkInteractive
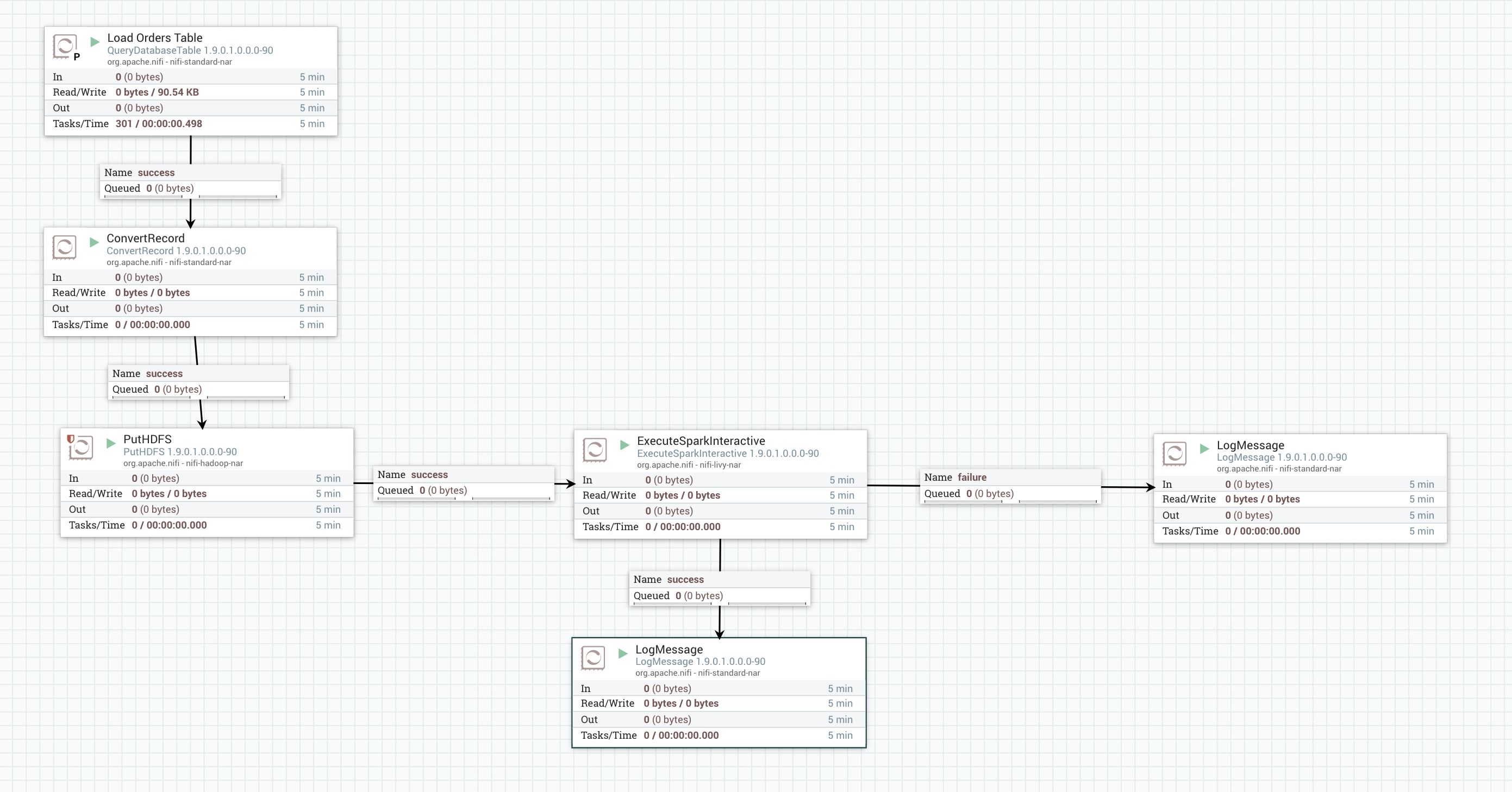
The final flow should look like this
Once executed, Livy will show the execution output