til
Today I Learned
- Collection & record my daily learning.
- Tech + product + business.
PROGRESS
20240126
- Zeppelin Flink interpreter setting
20240120:
- Postman : pressure test
20240119
- Web : 會話控制方式:
- token
- session
- cookie
- ref
- cookie VS session
- sesssion intro
20240117
- TS transaction library : TypeORM
20240114
- Stock 技術分析 : KD指標(Stochastic Oscillator)
20240113
-
Java 受檢例外(Checked Exception), 執行時期例外(Runtime Exception)
-
受檢例外(Checked Exception)
- 在某些情況下例外的發生是可預期的,例如使用輸入輸出功能時,可能會由於硬體環境問題,而使得程式無法正常從硬體取得輸入或進行輸出,這種錯誤是可預期發生的,像這類的例外稱之為「受檢例外」(Checked Exception),對於受檢例外編譯器會要求您進行例外處理,
-
執行時期例外(Runtime Exception
- 像 NumberFortmatException 例外是「執行時期例外」(Runtime exception),也就是例外是發生在程式執行期間,並不一定可預期它的發生,編譯器不要求您一定要處理,對於執行時期例外若沒有處理,則例外會一直往外丟,最後由 JVM 來處理例外,JVM 所作的就是顯示例外堆疊訊息,之後結束程式。
-
Thoughts
- 如果您在方法中會有例外的發生,而您並不想在方法中直接處理,而想要由呼叫方法的呼叫者來處理,則您可以使用 "throws" 關鍵字來宣告這個方法將會丟出例外,例如 java.ioBufferedReader 的 readLine() 方法就聲明會丟出 java.io.IOException。使用 "throws" 聲明丟出例外的時機,通常是工具類別的某個工具方法,因為作為被呼叫的工具,本身並不需要將處理例外的方式給定義下來,所以在方法上使用"throws"聲明會丟出例外,由呼叫者自行決定如何處理例外是比較合適的,您可以如下使用 "throws" 來丟出例外:
-
Ref
-
20240112
- JS Promise
20240109
- VSCode NodeJs 語法提示
20240107
- Steps when FE loads HTML (how many requests FE sends to BE ??)
- https://www.youtube.com/watch?v=mw0fcq3V5rQ&list=PLmOn9nNkQxJGOPF4yPJ_H8lyn73KBcPtP&index=55
- get HTML
- get CSS
- get pic
- get JS
20240106
- Zeppelin SDK + Flink
20240103
- InnoDB
- 是MySQL和MariaDB的資料庫引擎之一,最初由MySQL AB發行。InnoDB由Innobase Oy公司所開發,2006年五月時由甲骨文公司併購。與傳統的ISAM與MyISAM相比,InnoDB的最大特色就是支援了ACID相容的事務(Transaction)功能,類似於PostgreSQL
- wiki
- Other Mysql engine : MyISAM
20231230
- Spring boot
@bean- 在用@Configuration修飾class後, 在方法上使用
@bean, 則該方法會自動被註冊入Spring容器, 進行IOC管理(inverse of control) - e.g. @Configuration類似於xml文件的配置, 而@bean類似於xml文件裡的配置k-v
- https://blog.51cto.com/u_15067225/2900410
- https://blog.csdn.net/z69183787/article/details/108105329
- https://youtu.be/BXjMbUVs0rY?si=uRgcgOF5grj1MPtb&t=548
- 在用@Configuration修飾class後, 在方法上使用
- Zookeeper distribution lock client library written in Java - curator
20231225
- Cache 三大現象
- 緩存穿透
- 緩存擊穿
- 緩存雪崩
20231222
- Spring boot exclude sub lib in pom dep
- Spring boot async (multi thread)
20231220
- Flink
- checkpoint
- checkpoint VS save point ?
- job manager VS task manager
- job manager ~= master
- task manager ~= worker manager
- https://nightlies.apache.org/flink/flink-docs-master/zh/docs/concepts/flink-architecture/
- https://nightlies.apache.org/flink/flink-docs-master/zh/docs/try-flink/flink-operations-playground/#:~:text=%E4%B8%80%E4%B8%AAFlink%20%E9%9B%86%E7%BE%A4%E6%80%BB%E6%98%AF,%E7%BB%84%E6%88%90%E4%BA%86%E4%B8%80%E4%B8%AAFlink%20Job%E3%80%82
- Kafka
- 資料不遺漏 實現方式?
- via
Ack - ref
- via
- Topic or partition can have ordering ?
- ONLY partition ordering (Topic is NOT ordering, or lost parallism), but cusumer can consume in ordering
- https://www.cnblogs.com/yisany/p/14736360.html
Exactly once底層實現方式? (Idempotence + Transaction)- 冪等性 Idempotence
- 事務性 Transaction
-

-

-

- https://www.lixueduan.com/posts/kafka/10-exactly-once-impl/
- https://blog.csdn.net/zc19921215/article/details/108466393#:~:text=Kafka%E5%B9%82%E7%AD%89%E6%80%A7%EF%BC%9A,number%E8%BF%99%E4%B8%A4%E4%B8%AA%E6%A6%82%E5%BF%B5%E3%80%82
- https://github.com/yennanliu/CS_basics/blob/master/doc/faq/kafka/faq_kafka.md#2-how-does-kafka-implement-exactly-once-
- 資料不遺漏 實現方式?
- Redis
- pros and cons
-
pros:
- 資料儲存在內存, 讀寫速度快,效能優異
- 支援資料持久化,便於資料備份、恢復
- 支援簡單的事務,操作滿足原子性
- 支援String、List、Hash、Set、Zset五種資料類型,滿足多場景需求
- 支持主從複製,實現讀寫分離,分擔讀的壓力
- 支援哨兵機制,實現自動故障轉移
- 效能極高 – Redis能讀的速度是110000次/s,寫的速度是81000次/s 。
- 豐富的資料類型 – Redis支援二進位案例的 Strings, Lists, Hashes, Sets 和 Ordered Sets 資料類型運算。
- 原子 – Redis的所有操作都是原子性的,同時Redis也支援對幾個操作全併後的原子性執行。
- 豐富的特性 – Redis也支援 publish/subscribe, 通知, key 過期等等特性。
-
cons:
- 資料儲存在內存,主機斷電則資料遺失
- 儲存容量受到實體記憶體的限制,只能用於小資料量的高效能操作
- 線上擴容比較困難,系統上線時必須確保有足夠的空間
- 用於快取時,易出現’緩存雪崩‘,’快取擊穿‘等問題
- 單執行緒 – Redis的所有操作都是單執行緒的,這會導致在高並發的情況下,Redis會成為效能的瓶頸。
- 不支援複雜的查詢 – Redis雖然提供了豐富的資料類型,但還是不支援複雜的查詢。
- 資料不是真正的刪除,而是被清除 – Redis刪除某個key後,會立即釋放內存,但是對於大key來說,內存釋放會比較慢。
-
- redis 上鎖 command
- pros and cons
- DB
- 上鎖 command
- Mysql鎖類型: (都是悲觀鎖)
- 全局鎖
# sql # lock flush tables with read lock # unlock unlock tables
- 表鎖
# lock #lock tables user read; LOCK TABLE T WRITE; # unlock #unlock tables UNLOCK table;
- 行鎖
select ... for update;
- 讀寫鎖
- 全局鎖
- 複合index, example create_time + user_id, 如果只有user_id 在where condition, 仍會有索引效果? -> NO, 如果 1)非使用全部複合index or 2)where 條件並非從左綴索引開始, 則複合index不發揮作用
- 複合索引遵循最左匹配原則,只有索引中最左列匹配到,下一列才有可能被匹配。 如果左邊欄位使用的是非等值查詢,則索引右邊的欄位將不會被查詢使用,也不會被排序使用。
- https://www.begtut.com/mysql/mysql-composite-index.html
- https://blog.csdn.net/riemann_/article/details/94840416
- https://www.cnblogs.com/lijiaman/p/14364171.html
- BE
- 分庫transaction 如何設計? 實現?
- 死鎖問題如何發生? 解決方式?
- DB isolcation ? 不同層級?

20231218
- Spring boot:
@Component- Spring 啟動後, 會掃描, 初始化該類的無參數構造方法, 並將初始化後的instance放入spring容器
- so the instance can be injected to the container (if NOT bean, service, controller...)
- https://youtu.be/dcmhIij3eNM?si=NW2Z4wW_5t6_HitP&t=113
- https://youtu.be/V5iKz8HPiI4?si=r28o--dQURuUW494&t=395
- Spring boot :
@PostConstruct- 保證該方法在無參數構造方法初始化後 立刻執行 (e.g. @Component -> @PostConstruct)
- https://youtu.be/dcmhIij3eNM?si=3KKKz3ldEPE0_RFo&t=122
// java
@Component
public class ZKClient{
@PostConstruct
public void init(){
}
}20231212
- Java Spring boot OAuth2 login with google
20231211
- Java : Sorting, Comparable VS Comparator
- https://www.pkslow.com/archives/java-sorting
- https://openhome.cc/zh-tw/java/collection/comparator/
- https://blog.csdn.net/dl962454/article/details/112731217
20231209
-
Java distribution lock POC
- Redis
- MySQL
- Zookeeper
- other 3rd party tools
-
Java CDC(Change Data Capture) POC
- https://medium.com/@systemdesignbychk/system-design-demystifying-change-data-capture-cdc-in-event-driven-microservices-using-debezium-7ed24336bc5a
- https://cloud.tencent.com/developer/article/1483833?fbclid=IwAR1IavrHB41EBjTavtrkIJUSLb1S6o4bKippEKl0L9u65vvwC4VlYPfiPLE
- https://github.com/confluentinc/demo-change-data-capture
20231206
- mybatis 帶入變數方式? 差別
- #{}和${}的區別是什麼? #{}是預編譯處理,${}是字元串替換。 Mybatis在處理#{}時,會將sql中的#{}替換為?號,調用PreparedStatement的set方法來賦值; Mybatis在處理${}時,就是把${}替換成變數的值。 使用#{}可以有效的防止SQL註入,提高系統安全性。 https://www.zendei.com/article/70565.html
- 批量插入語法?
- Mybatis VS Hibernate ? Hibernate屬於全自動ORM映射工具,使用Hibernate查詢關聯對象或者關聯集合對象時,可以根據對象關係模型直接獲取,所以它是全自動的。而Mybatis在查詢關聯對象或關聯集合對象時,需要手動編寫sql來完成,所以,稱之為半自動ORM映射工具。
-
redis, Zookeeper 實現分散式鎖
-
websocket實現原理
-
如何偵測死鎖? 看什麼metrics ? cmd ?
-
實現 thread 方式? 如何讓資源獨享?
-
java網路框架? Netty運作方式?
-
分庫分表方式?
-
http 連線斷開 步驟? (client <-> server)
- 4 hands shake
1. client 發起請求 2. server 接受請求 3. server 斷開連接 4. client 斷開連接 -
redis 支持數據結構?
- https://segmentfault.com/a/1190000040102333
- https://javaguide.cn/database/redis/redis-data-structures-01.html
- basic : string、list、hash、set、sorted set
- 也支援更高階資料結構, e.g.:HyperLogLog、Geo、BloomFilter
-
慢查詢? 如何優化?
-
String, StringBuilder, StringBuffer差別, 使用場景? 哪ㄧ個可以用在thread安全?
-
https://www.runoob.com/w3cnote/java-different-of-string-stringbuffer-stringbuilder.html
-
String VS StringBuffer 主要性能區別:
String 是不可變的對象, 因此在每次對String 類型進行改變的時候,都會產生一個新的String 對象,然後將指針指向新的String對象,所以經常改變內容的 字串最好不要用String ,因為每次產生物件都會對系統效能產生影響,特別當記憶體中無引用物件多了以後, JVM 的GC 就會開始運作,效能就會降低。 -
使用 StringBuffer 類別時,每次都會對 StringBuffer 物件本身進行操作,而不是產生新的物件並更改物件引用。 所以多數情況下推薦使用 StringBuffer ,特別是字串物件經常改變的情況。
-
use case - 如果要操作少量的數據,用String - 單線程操作大量數據,用StringBuilder - 多線程操作大量數據,用StringBuffer。
- java 如何實現比較二個String是否相等 ?
20231205
- Redis pros and cons
- 分散式交易 (Distributed Transactions)
- Java how to init Optional
20231129
- Spring boot read files under /resources
// java // exmaple File file = new File("src/main/resources/" + downloadUrl);
20231128
- RedisTemplate basic API (Java redis client)
20231127
- Fix using Swagger 2.x
- // Fix using Swagger 2.x : https://blog.51cto.com/u_15740726/5540690
- commit
20231124
- Spring boot redirect : RedirectView
- Jackson : json <--> java class instance
- Jedis : java lib for Redis
20231123
- Common security issue when web development
- XSS (Cross-site scripting)
- SQL Injection
- CSRF
- ClickJacking
- Open Redirect
- DOS
- Insecure Direct Object Reference Vulnerability
- https://www.cloudflare.com/zh-tw/learning/security/what-is-web-application-security/
- https://medium.com/starbugs/%E8%BA%AB%E7%82%BA-web-%E5%B7%A5%E7%A8%8B%E5%B8%AB-%E4%BD%A0%E4%B8%80%E5%AE%9A%E8%A6%81%E7%9F%A5%E9%81%93%E7%9A%84%E5%B9%BE%E5%80%8B-web-%E8%B3%87%E8%A8%8A%E5%AE%89%E5%85%A8%E8%AD%B0%E9%A1%8C-29b8a4af6e13
20231122
- Spring boot : @PathVariable VS @RequestParam
- https://www.baeldung.com/spring-pathvariable
- https://www.baeldung.com/spring-requestparam-vs-pathvariable
// example
// -------------------
// 1) PathVariable
// -------------------
@GetMapping("/foos/{id}")
@ResponseBody
public String getFooById(@PathVariable String id) {
return "ID: " + id;
}
-> endpoint
http://localhost:8080/spring-mvc-basics/foos/abc
----
ID: abc
// -------------------
// 2) RequestParam
// -------------------
@GetMapping("/foos")
@ResponseBody
public String getFooByIdUsingQueryParam(@RequestParam String id) {
return "ID: " + id;
}
-> endpoint
http://localhost:8080/spring-mvc-basics/foos?id=abc
----
ID: abc
20231121
-
TCP VS UDP
-
Java concurrency example: bank
20231118
- Java mockito
20231117
- Java : Dependency Injection (DI)
20231116
- junit.jupiter : fix "null pointer" error when use @Before
* -> so, do below * - 1) add annotaiton : @ExtendWith(MockitoExtension.class) * - 2) use @BeforeEach
20231114
- Java : throw exception VS try-catch
1.throw 是語句拋出一個異常,如throw new Exception();他不處理異常,直接拋出異常; 2.throws是表示方法拋出異常,需要呼叫者來處理,如果不想處理就一直向外拋,最後會有jvm來處理; 3.try catch 是自己來捕捉別人拋出的異常,然後在catch裡面去處理。
20231113
- Java : try-with-resource VS try-catch-final ?
- try-with-resource: prefer, code more elegant, resource closing already implemented automatically
- https://javaguide.cn/java/basis/syntactic-sugar.html#try-with-resource
- JS SocketJS: common API (e.g. Stomp.over,....)
- CAS (Compare And Swap) 算法
- https://javaguide.cn/java/concurrent/java-concurrent-questions-02.html#%E5%A6%82%E4%BD%95%E5%AE%9E%E7%8E%B0%E4%B9%90%E8%A7%82%E9%94%81
- 實現樂觀鎖(Optimistic lock)
- compare expected val and actual val, ONLY update if they are the same
20231112
- Redis GUI App
20231107
- Spring @Configuration
- recognized as config class, setup get bean method in it, then bean will be auto injected by Spring boot when app run
- https://youtu.be/17Igk4Podd4?si=LxQ353ybO4j4MjVz&t=767
20231106
- Software testing
- Unit test
- Functional test
- Integration test
- end-to-end test
- https://moduscreate.com/blog/an-overview-of-unit-integration-and-e2e-testing/
- https://www.twilio.com/blog/unit-integration-end-to-end-testing-difference
20231104
- STOMP (Simple Text Oriented Message Protocol)
- A WebSocket implementation by Spring boot
- https://blog.csdn.net/qq_21294185/article/details/130657375
- https://blog.csdn.net/u013749113/article/details/131455579
20231103
20231009
- Java spring boot :
object references an unsaved transient instance - save the transient instance before flushingerror// java // example @ManyToOne(cascade = CascadeType.PERSIST)
20231008
- Java design pattern
- 適配器模式 (Adapter Pattern)
- 創造一個適配器 ,它用於實現上面的接口,但是所有的方法都是空方法 ,這樣,我們就可以轉而定義自己的類來繼承下面這個類即可
- https://www.readfog.com/a/1639984655800307712
- https://www.runoob.com/design-pattern/adapter-pattern.html
- https://youtu.be/r4fdPmZuzmY?si=GmePG_JsutE60l0I&t=1320
- 適配器模式 (Adapter Pattern)
20231006
-
Ways do Client-Server bi communication
- Comet
- Web socket
-
Web socket
- WebSocket 是 HTML5 開始提供的一種在單個 TCP 連線上進行全雙工通訊的協定。
- WebSocket 使得使用者端和伺服器之間的資料交換變得更加簡單,允許伺服器端主動向使用者端推播資料。在 WebSocket API 中,瀏覽器和伺服器只需要完成一次握手,兩者之間就直接可以建立永續性的連線,並進行雙向資料傳輸。
- 在 WebSocket API 中,瀏覽器和伺服器只需要做一個握手的動作,然後,瀏覽器和伺服器之間就形成了一條快速通道。兩者之間就直接可以資料互相傳送。
- 簡單的說,就是一次握手,持續通訊。
- Ref
-
Comet
- Long Polling
- Streaming
20231005
- Javascript print class info instead of "Object"
// javascript // example console.log(JSON.stringify(myClass)))
- React Hook (useState, useEffect ...)
- https://medium.com/vita-for-one/react-hooks-%E5%AD%B8%E7%BF%92%E7%AD%86%E8%A8%98-usestate-useeffect-usecontext-b11c33e69bea#:~:text=useEffect%20%E6%B8%85%E7%90%86%E6%A9%9F%E5%88%B6,%E7%A8%AE%E6%98%AF%E9%9C%80%E8%A6%81%E6%B8%85%E7%90%86%E7%9A%84%E3%80%82
- https://medium.com/vita-for-one/react-hooks-%E5%AD%B8%E7%BF%92%E7%AD%86%E8%A8%98-usestate-useeffect-usecontext-b11c33e69bea#:~:text=useEffect%20%E6%B8%85%E7%90%86%E6%A9%9F%E5%88%B6,%E7%A8%AE%E6%98%AF%E9%9C%80%E8%A6%81%E6%B8%85%E7%90%86%E7%9A%84%E3%80%82
- https://www.readfog.com/a/1642414651295764480
20231001
- Java
- create SDK and import to project
- Arrays.asList VS new ArrayList() - https://www.baeldung.com/java-arrays-aslist-vs-new-arraylist#:~:text=asList%20method%20returns%20a%20type,the%20add%20and%20remove%20methods.
- Continue VS break VS pass - https://www.digitalocean.com/community/tutorials/how-to-use-break-continue-and-pass-statements-when-working-with-loops-in-python-3
20230903
- Hibernate : “Detached Entity Passed to Persist” Error
20230901
- Spring boot security + JWT
20230819
- Zipkin Spring Cloud
- Zipkin is an application that monitors and manages the Spring Cloud Sleuth logs of your Spring Boot application.
- Trace spring app request
- https://youtu.be/Cm75_MIo_aY?t=626
- https://www.1ju.org/spring-cloud/tracing-services-with-zipkin
20230816
- VPC peering via CDK
- Subnet type
- CDK VPC peering video
20230814
- VPC peering
- https://docs.aws.amazon.com/zh_tw/vpc/latest/peering/create-vpc-peering-connection.html
- https://docs.aws.amazon.com/zh_tw/vpc/latest/peering/create-vpc-peering-connection.html#same-account-same-region
- https://docs.aws.amazon.com/zh_tw/vpc/latest/peering/vpc-peering-routing.htmlhttps://docs.aws.amazon.com/zh_tw/vpc/latest/userguide/VPC_Route_Tables.html
- https://rdpapa.tw/2022/09/10/aws-vpc-peering/
- https://www.kmp.tw/post/awsvpcpeering/
- https://medium.com/@1000lin/aws-network-planning-d1424e171846
- VPC peering debug
- Create new VPC can be used by redshift ?
- VPC terms
- VPC (Virtual Private Cloud): 在實務上我們會將需要獨立的環境(網段),用VPC區隔開來。例如: vpc-sit、vpc-uat、vpc-prod、vit-workspace
- Subnet : Subnet就是在VPC的網段下,再細分不同的子網段。Subnet可區分為Public、Private和Vpn-Only三種,在subnet的Route Table中,能將流量route到Internet Gateway的屬於Public Subnet;如果只能將流量route到Virtual Private Gateway就是Vpn-Only Subnet; 否則就是Private Subnet
- Internet Gateway : Internet Gateway可以attach在vpc上,為該vpc提供向外access internet的能力。
- NAT Gateway : NAT Gateway扮演了讓Private Subnet可以透過Net Address Translation間接向外訪問Internet的能力;也就是Source NAT。
- Route Tables : 每個subnet都有一個Route Table,來決定Traffics的流向。
- Peering Connection : 二個獨立的VPC之間,若需要互相溝通,則需要建立Peering Connection,在本文的範例中,將用來打通vpc-workspace和vpc-sit之間的流量。
20230811
- Build BI System from Scratch -- Kinesis firehose s3 prefix
20230809
- Spark stream + kinesis
20230808
- Spring integration test
20230804
- Cloudwatch -> Kinesis
- Akka send to Kinesis
- connect to my Amazon Redshift cluster
- My cluster can't be accessed by an Amazon Elastic Compute Cloud (Amazon EC2) instance that is in a different VPC
- https://repost.aws/knowledge-center/cannot-connect-redshift-cluster
20230802
- SQL cross join
-- sql SELECT .. FROM table_A, table_B
20230731
- Java : equals() VS ==
20230726
- Route53 + API
20230723
- Maven package all dependency in jar
<!-- maven.xml -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.2</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
20230722
- Spring boot security social login: Github, Google
- Spring boot security - in memory user setup
- AWS Lambda calculates concurrent
- 什麼場景(不)適合使用Lambda
20230721
- Metabase environment variables
20230717
- Metabase connects to DB in VPC
- Setup subnet in redshift console for using existing VPC
- NAT gateways
20230715
- Step func workshop
20230710
-
Redshift
- COPY JSON to a table
- https://docs.aws.amazon.com/redshift/latest/dg/copy-usage_notes-copy-from-json.html
- https://www.bmc.com/blogs/amazon-redshift-copy-json-data/
- Monitoring Amazon Redshift using CloudWatch metrics
- troubleshoot high or full disk usage with Amazon Redshift
- Policy allow Redshift spectrum query s3
- COPY JSON to a table
-
URL VS URI
- https://codingbeginner01.com/difference-between-uri-and-url/
- https://www.cnblogs.com/blknemo/p/13198506.html#:~:text=URI%E5%92%8CURL%E7%9A%84%E5%8C%BA%E5%88%AB%20%E2%9F%B3&text=%E7%BB%9F%E4%B8%80%E8%B5%84%E6%BA%90%E6%A0%87%E8%AF%86%E7%AC%A6(Uniform,%E8%B5%84%E6%BA%90%E5%90%8D%E7%A7%B0%E7%9A%84%E5%AD%97%E7%AC%A6%E4%B8%B2%E3%80%82
20230705
- CDK create Postgre creds
20230630
- Share S3 with Redshift in different AWS account
- How do I COPY or UNLOAD data from Amazon Redshift to an Amazon S3 bucket in another account?
- https://repost.aws/knowledge-center/redshift-s3-cross-account
- https://repost.aws/zh-Hans/knowledge-center/redshift-s3-cross-account
- https://stackoverflow.com/questions/36730820/copy-to-redshift-from-another-accounts-s3-bucket
20230627
- Spring Cloud AWS
- Airflow setup ssh conn
- Airflow XCom, xcom_pull, xcom_push
- Spring JDBC connection pool
20230626
- Mapping docker port
Flag value Description
-p 8080:80 Map TCP port 80 in the container to port 8080 on the Docker host.
20230626
- Elastic search
20230623
- Airflow Docker compose
- Kinesis dynamic partition keys
20230620
- Spring boot
- Controller makes HTTP call to the other endpoint (inside it)
20230619
- Specify an Amazon S3 Destination for the Delivery Stream (Kinesis)
- firehose namespace (Kinesis -> s3)
20230616
- squash commits via IntelliJ
20230609
- Redshift Spectrum external tables add partition
20230607
- Lambda : Passing data between Lambdas with AWS Step Functions
20230605
- Bulder pattern
- Spring boot - Swagger config
20230601
- S3 bucket size monitoring - console, cloudwatch, shell script
20230530
- AWS eventbridge
- AWS lambda return status
- AWS Step function run EMR spark-submit
- Redshift spectrum
20230529
- Init scala spark project with IntelliJ
- P90, P99
20230526
- Spark
- generate schema from case class
- StructType with ArrayType in nested structure
20230524
- EMR
- aws command run EMR notebook
- databricks spark-redshift lib
- VPC peering
- https://docs.aws.amazon.com/vpc/latest/peering/what-is-vpc-peering.html
- https://stackoverflow.com/questions/44968000/connection-timed-out-exception-with-spark-redshift-on-emr
- https://docs.databricks.com/external-data/amazon-redshift.html
- https://docs.databricks.com/administration-guide/cloud-configurations/aws/vpc-peering.html#programmatic-peering
20230524
- EMR, Lambda
- Lambda run EMR job
- Step function run EMR job
20230523
- EMR
- load external jar in EMR studio (notebook)
// V1 // notebook %%configure -f { "conf": { "spark.jars":"file:///usr/share/aws/redshift/jdbc/RedshiftJDBC.jar,file:///usr/share/aws/redshift/spark-redshift/lib/spark-redshift.jar,file:///usr/share/aws/redshift/spark-redshift/lib/spark-avro.jar,file:///usr/share/aws/redshift/spark-redshift/lib/minimal-json.jar" } } // V2 // notebook %%configure -f { "conf": { "spark.jars": "s3://YOUR_BUCKET/YOUR_DRIVER.jar" } } - dump data to EMR
- load external jar in EMR studio (notebook)
- Spark
- flatten array within a Dataframe in Spark
// scala spark scala> val nested = spark.read.option("multiline",true).json("nested.json") nested: org.apache.spark.sql.DataFrame = [array: array<struct<a:string,b:bigint,c:string,d:string,e:bigint>>]
- flatten array within a Dataframe in Spark
20230519
- AWS Lambda
- install, deploy, use 3rd party libraries in Lambda py script
20230517
- Python
- Logging facility for Python
20230515
- Spark
- Vue
- negelect format error when build
20230513
- Java
- Multiply a String by an Integer (duplicate String N times)
// java private static String multiplyString(String str, int multiplier){ StringBuilder sb = new StringBuilder(); for (int i = 0; i < multiplier; i++) { sb.append(str); } return sb.toString(); }
- Reverse String
// java public static String reverseString(String str) { return new StringBuilder(str).reverse().toString(); }
- Multiply a String by an Integer (duplicate String N times)
20230509
- AWS Lambda
- Lambda call API and write to S3
- Processing large payloads with Amazon API Gateway asynchronously
20230508
- Python
20230505
- Python
20230430
- ELK
- Macbook M1 install ELK docker
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.10.2
- Macbook M1 install ELK docker
20230428
- Python
- How To Use the
__str__()and__repr__()Methods in Python- https://www.digitalocean.com/community/tutorials/python-str-repr-functions
- The str() method returns a human-readable, or informal, string representation of an object.
- The repr() method returns a more information-rich, or official, string representation of an object. This method is called by the built-in repr() function. If possible, the string returned should be a valid Python expression that can be used to recreate the object.
- Note that str() and repr() return the same value, because str() calls repr() when str() isn’t implemented.
# python # implement a class with __repr__() class Ocean: def __init__(self, sea_creature_name, sea_creature_age): self.name = sea_creature_name self.age = sea_creature_age def __str__(self): return f'The creature type is {self.name} and the age is {self.age}' def __repr__(self): return f'Ocean(\'{self.name}\', {self.age})' c = Ocean('Jellyfish', 5) print(str(c)) print(repr(c))
- How To Use the
20230424
- Redshift spectrum update with s3 partition
20230420
- JWT (Json web tokens)
- JSON web token (JWT), pronounced "jot", is an open standard (RFC 7519) that defines a compact and self-contained way for securely transmitting information between parties as a JSON object. Again, JWT is a standard, meaning that all JWTs are tokens, but not all tokens are JWTs.
- Because of its relatively small size, a JWT can be sent through a URL, through a POST parameter, or inside an HTTP header, and it is transmitted quickly. A JWT contains all the required information about an entity to avoid querying a database more than once. The recipient of a JWT also does not need to call a server to validate the token.
- https://medium.com/%E4%BC%81%E9%B5%9D%E4%B9%9F%E6%87%82%E7%A8%8B%E5%BC%8F%E8%A8%AD%E8%A8%88/jwt-json-web-token-%E5%8E%9F%E7%90%86%E4%BB%8B%E7%B4%B9-74abfafad7ba
- https://jwt.io/
- https://auth0.com/docs/secure/tokens/json-web-tokens
- https://www.metabase.com/docs/latest/people-and-groups/authenticating-with-jwt#enabling-jwt-authentication
- https://github.com/metabase/sso-examples

20230417
- SSL/TLS certificate
- Cloudfront - Lambda@Edge function (Viewer request, Origin request, Origin response, Viewer response)
20230319
- Deep copy, shallow copy




20230316
- AWS
20230315
- AWS
20230314
- AWS RDS
20230313
- CDK
20230312
- Typescript
- ? in attr name
// typescript let a{name: string, age: number}; let b{name: string, age?: number}; // age attr for b is optional // test b = {name: 'iori'};
- readonly
- class constructor : this
- extends
- override
- super
- https://youtu.be/UDBhubQGmVs?t=26
- https://youtu.be/UDBhubQGmVs?t=361 : important!!, super used in constructor
- generic type
- ? in attr name
20230310
- how to solve "The maximum number of addresses has been reached" for AWS VPC Elastic IP addresses?
- Go to https://us-east-1.console.aws.amazon.com/servicequotas/home/services/ec2/quotas and search for "IP". Then, choose "EC2-VPC Elastic IPs".
- https://stackoverflow.com/questions/71807998/how-to-resolve-the-maximum-number-of-addresses-has-been-reached-for-aws-vpc-el
20230309
- CDK
20230304
- Java
- volatile
Java volatile 關鍵字作用是,使系統中所有線程對該關鍵字修飾的變量共享可見,可以禁止線程的工作內存對volatile修飾的變量進行緩存。- https://www.baeldung.com/java-volatile
- https://jenkov.com/tutorials/java-concurrency/volatile.html
- https://zhuanlan.zhihu.com/p/151289085
- https://blog.csdn.net/u012723673/article/details/80682208
- https://cloud.tencent.com/developer/article/1803803
- https://zhuanlan.zhihu.com/p/145902867
- example
// java, Singleton double check (use volatile) public class Singleton{ // NOTE here private static volatile Singleton singleton; private Singleton(){}; public static Singleton getInstance(){ if(singleton == null){ synchronized(Singleton.class){ if (singleton == null){ singleton = new Singleton(); } } } return singleton; } }
- volatile
20230301
- AWS CloudFront
Amazon CloudFront 是一種內容交付網路 (CDN),可加速向最終使用者交付靜態和動態 Web 內容。` CloudFront 透過稱為邊緣節點的全球資料中心網路交付內容。當最終使用者請求您使用 CloudFront 提供的內容時,該請求將被路由至距離最終使用者最近且延遲最低的邊緣節點。- https://aws.amazon.com/tw/cloudfront/getting-started/
- https://docs.aws.amazon.com/zh_tw/AmazonCloudFront/latest/DeveloperGuide/GettingStarted.html
- tutorial
- https://ithelp.ithome.com.tw/articles/10192080
- step 1) set S3 bucket as NON public
- step 2) go to S3 bucket set up "Bucket policy" as below
- step 3) then create cloudfront distribution with "Originaccess control settings (recommended)"
{ "Version": "2008-10-17", "Id": "PolicyForCloudFrontPrivateContent", "Statement": [ { "Sid": "AllowCloudFrontServicePrincipal", "Effect": "Allow", "Principal": { "Service": "cloudfront.amazonaws.com" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::yen-test-20230413/*", "Condition": { "StringEquals": { "AWS:SourceArn": "arn:aws:cloudfront::77777777777:distribution/EUPA2IOLE7S30" } } } ] } - https://ithelp.ithome.com.tw/articles/10192080
- video
20230226
- Spring boot
- logic deletion
- print SQL in log
20230225
- Spring boot
- Entity add field NOT exists in DB table:
@TableField(exist = false)- code
- https://youtu.be/5aWkhC7plsc?t=646
// java @TableField(exist = false) private List<CategoryEntity> children;
- Entity add field NOT exists in DB table:
20230222
- Java
- Spring @Async VS CompletableFuture
20230214
- Java
- Future VS Promise, CompletableFuture ... (async call)
- Spring boot
- JpaRepository
- JpaRepository 是作為 Repository 應用的一種繼承的「抽象介面」,他允許我們可以透過介面的使用,就直接與資料庫進行映射與溝通。
- https://medium.com/learning-from-jhipster/20-controller-service-repository%E7%9A%84%E5%BB%BA%E7%AB%8B-1-jparepository-%E7%9A%84%E4%BD%BF%E7%94%A8-6606de7c9d41
- https://ithelp.ithome.com.tw/articles/10194906
- JpaRepository
- Redshift
20230212
- Map Reduce
- Reduce
// syntax: // array.reduce(function(total, currentValue, currentIndex, arr), initialValue) // or // array.reduce(callback[, initialValue]); function(total, currentValue, index, arr): It is a required parameter used to run for each array element. It contains four parameters which are listed below: - total: It is the required parameter used to specify an initialValue or the previously returned value of a function. - currentValue: It is the needed parameter and is used to determine the value of a current element. - currentIndex: It is the optional parameter used to specify an array index of the current element. - arr: It is the optional parameter used to determine an array object the current element belongs to. initialValue: The optional parameter specifies the value to be passed to the function as an initial value.// javascript // example: const data = [5, 10, 15, 20, 25]; const res = data.reduce((total,currentValue) => { return total + currentValue; }); console.log(res); // 75
20230210
20230209
- LDAP (Lightweight Directory Access Protocol)
- Others
20230208
- Message queue
- TTL: time to live
- https://youtu.be/xDK72L-XZps?t=455
- msg survive time
- TTL: time to live
20230207
- Distribution system
- 分布式事務方案 (Distribution transaction)
- 2PC (2 phase commit) (XA)
- 3PC (3 phase commit) (automated TCC)
- TCC (Try, Commit, and Cancel (TCC))
- Local Messaging
- Transactional Messaging
- Best-effort Notification
- Ref
- https://youtu.be/fBGmuUdNejM
- https://www.alibabacloud.com/blog/an-in-depth-analysis-of-distributed-transaction-solutions_597232#:~:text=Try%2C%20Commit%2C%20and%20Cancel%20(,%2C%20commit%2C%20and%20cancel%20interfaces.
- https://medium.com/@dongfuye/the-seven-most-classic-solutions-for-distributed-transaction-management-3f915f331e15
- https://betterprogramming.pub/a-tcc-distributed-transaction-made-easy-with-go-c0a38d2a8c44
- https://www.dtm.pub/
- TCC
-
- 分布式事務方案 (Distribution transaction)
- Metadata discover
- IntelliJ create test from a class directly

20230205
- Java
- 本地事務隔離級別, 傳播行為
20230203
- 驗證(Authentication)與授權(Authorization)
Authentication(驗證):確認使用者是否真的是其所宣稱的那個人的過程。 Authorization(授權):根據使用者的角色來授予應有的權限。- https://youtu.be/L8M_eXV0OVk?si=4Ce72KAIBAzdN9Kw&t=33
- Authentication : can access the App (software)
- example : can access a friend's house
- Authorization : can use the function in an App
- example : can access rooms in the house
- Authentication : can access the App (software)
- https://matthung0807.blogspot.com/2018/03/authenticationauthorization.html
- https://www.ithome.com.tw/voice/134389
- https://www.onelogin.com/learn/authentication-vs-authorization#:~:text=Authentication%20and%20authorization%20are%20two,authorization%20determines%20their%20access%20rights.
- https://youtu.be/L8M_eXV0OVk?si=4Ce72KAIBAzdN9Kw&t=33
20230201
- Redshift
- optimazation
- https://zhuanlan.zhihu.com/p/398754264
- https://blog.csdn.net/awschina/article/details/121759986
- https://www.infoq.cn/article/yudaymzeokmbr3zgwxag
- https://aws.amazon.com/cn/blogs/china/overview-of-ten-amazon-redshift-performance-tuning-techniques/
- https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/c-optimizing-query-performance.html
- table design
sharding, partition, ordering, design ideas!!!
- optimazation
20230126
- Docker
- docker container connect to local mysql (macbook)
- Redshift
20230125
- gitignore
- negelect all files with below name (spring boot)
- https://youtu.be/4NLgelF5-rk?t=546
- https://github.com/yennanliu/SpringPlayground/blob/main/.gitignore#L36
**/mvnw
**/mvnw.cwd
**/.idea
**/.mvn
**/.iml
**/.cmd
**/target/
.idea20230124
- Java spring boot/cloud
- Idea intelliJ : Create multiple modules under a project
20230121
- Java spring boot + RabbitMQ
- json serialize / deserialize
20230114
- Java spring boot : multi thread pool
20230108
- Java
- ThreadLocal : share data in the same thread
- Linux
- Access-Control list (ACL)
- https://youtu.be/0vYydtG1Xi4?t=1517
ownwer group others- R: read
- W : write
- X : execute
- modfiy ACL via
chmod
- Access-Control list (ACL)
20221213
- HTML
- DB
20221211
- MySQL
group_concat()function- https://www.yiibai.com/mysql/group_concat.html#:~:text=GROUP_CONCAT%20%E5%87%BD%E6%95%B0%E8%BF%94%E5%9B%9E%E4%BA%8C%E8%BF%9B%E5%88%B6%E6%88%96,%E5%8F%98%E9%87%8F%E6%9D%A5%E6%89%A9%E5%B1%95%E6%9C%80%E5%A4%A7%E9%95%BF%E5%BA%A6%E3%80%82
- https://www.footmark.com.tw/news/database/mysql/mysql-group-concat-json/
- https://www.w3resource.com/mysql/aggregate-functions-and-grouping/aggregate-functions-and-grouping-group_concat.php
- https://youtu.be/k9i6bOMt4rg?t=500
20221130
- Java
- sort double list
// java testList.sort((a, b) -> Double.compare(b, a));
- sort double list
20221129
- SQL
- compress SQL code
- Mysql text type : TEXT, TINYTEXT, MEDIUMTEXT, LONGTEXT
- https://www.analyticsvidhya.com/blog/2020/11/guide-data-types-mysql-data-science-beginners/#:~:text=LONGTEXT%20can%20store%20the%20maximum,LONGTEXT%20takes%204%2DBytes%20overhead.
- https://blog.csdn.net/youcijibi/article/details/80673811
# mysql cmd alter table my_db.my_table modify sql_template LONGTEXT
20221115
- Sringboot Java
- ObjectMapper : json <--> Java Object transformation
20221114
- AWS S3 token expire with IAM, access key...
20221111
- Millisecond to day/hour/min..
20221105
- Java
// java public ServiceException(Integer code, String message) { super(message); // TODO: double check this this.code = code; }
- Spring boot
20221105
- Java
- generic type
java 中泛型标记符: E - Element (在集合中使用,因为集合中存放的是元素) T - Type(Java 类) K - Key(键) V - Value(值) N - Number(数值类型) ? - 表示不确定的 java 类型 - stream
- generic type
20221104
- Spring boot
// java @Target({METHOD, FIELD, ANNOTATION_TYPE, CONSTRUCTOR, PARAMETER}) // TODO : double check it @Retention(RUNTIME) @Documented @Constraint(validatedBy = {EnumValue.EnumValueValidator.class})
- Java
- Class<?>
20221102
- Java
Collectors.groupingBy
Map<String, List<MyReport>> monthReportMap = myReport.stream() .collect(Collectors.groupingBy(MyReport::getOwnerGroupKey));
20221029
- Java
- parse object (whatever type) to json
- https://youtu.be/wGtcsi65arQ?t=494
- https://blog.csdn.net/xuexi_gan/article/details/114915890
- https://www.runoob.com/w3cnote/fastjson-intro.html
// java Map<String, List<Catelog2Vo>> result = JSON.parseObject(CatelogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {} );
- parse object (whatever type) to json
20221028
- Java
- AWS
- S3 presignedURL max expire time
- https://docs.aws.amazon.com/AmazonS3/latest/API/sigv4-query-string-auth.html
- Provides the time period, in seconds, for which the generated presigned URL is valid. For example, 86400 (24 hours). This value is an integer. The minimum value you can set is 1, and the maximum is 604800 (seven days).
- A presigned URL can be valid for a maximum of seven days because the signing key you use in signature calculation is valid for up to seven days.
- https://stackoverflow.com/questions/24014306/aws-s3-pre-signed-url-without-expiry-date
- https://docs.amazonaws.cn/en_us/AmazonS3/latest/userguide/ShareObjectPreSignedURL.html
- https://docs.aws.amazon.com/AmazonS3/latest/API/sigv4-query-string-auth.html
- S3 presignedURL max expire time
20221024
- Java
20221023
- System monitoring
- Skywalking
- https://dubbo.apache.org/zh/docs/v2.7/admin/ops/skywalking/#:~:text=%E5%88%86%E5%B8%83%E5%BC%8F%E8%B7%9F%E8%B8%AA-,Apache%20Skywalking%20%E7%AE%80%E4%BB%8B,%E9%97%B4%E5%85%B3%E7%B3%BB%E4%BB%A5%E5%8F%8A%E6%9C%8D%E5%8A%A1%E6%8C%87%E6%A0%87%E3%80%82
- https://juejin.cn/post/7002389720315461640
- https://www.jianshu.com/p/ffa7ddcda4ab
- General
- Skywalking


20221022
- Java
- Java Collectors toMap()
- https://www.baeldung.com/java-collectors-tomap
- https://vimsky.com/zh-tw/examples/usage/collectors-tomap-method-in-java-with-examples.html
- https://youtu.be/lq-xGkEm140?t=693
// java data.stream().collect(Collectors.toMap( k -> k.getId(), v -> {return v.gatValue()} ))
- Java Collectors toMap()
- Nginx conf
-

20221019
- Java
- x == null VS x.equals(null)
- can also use
spring StringUtils.isEmptycheck if empty
20221013
- Spring boot
20221004
- Spring boot
- MapStruct
XXXDTO <----> XXXVO <----> XXXBO <----> ....transformation- https://www.tpisoftware.com/tpu/articleDetails/2443
- https://springboot.io/t/topic/4162
- https://www.itread01.com/details/MnRvMA==.html
- MapStruct
20221003
- Java
20220929
- sdkman
20220927
- Java
- Stream map op (get collections of Stream map result)
-
- Ref
// java List<String> brand_list = car_list.stream().map(x -> { String brand = x.getBrand(); return brand; }).collect(Collectors.toList());
- Stream map op (get collections of Stream map result)

20220919
- Spring boot
- user-defined general exceptions
20220915
- Spring boot
thisVSself
20220915
- Spring boot
20220914
- Mybatis plus lambda
- Spring booot
- HTTP
- Eng soft skill
20220912
- Spring boot
Validation,valid切面導向程式設計(Aspect Oriented Programming,AOP
- Scala
ZIOcourse- https://rockthejvm.com/p/zio
- ZIO is a Scala toolkit that allows us to write powerful, concurrent, and high-performance applications in Scala using pure functional programming.
- https://github.com/rockthejvm/zio-course
- https://rockthejvm.com/p/zio
20220907
- Mysql
20220904
- Web dev
- 跨域請求 Cross-Origin Resource Sharing (CORS)
- Java
20220903
- Spring boot
- Java
- set default val if null
// sample code (menu1.getSort() == null ? 0);
- set default val if null
20220901
- PageHelper doc
20220830
- AWS S3
- Why is my presigned URL for an Amazon S3 bucket expiring before the expiration time that I specified?
- Examples: Signature Calculations in AWS Signature Version 4 (java)
- How do I utilize AWS Signature v4 when generating a presigned S3 URL?
- How to check presignedURL expire time (Signature Version 4)?
- https://stackoverflow.com/questions/46865679/amazon-s3-how-to-check-if-presigned-url-is-expired
Amz-Expires is the expiration time in seconds, while X-Amz-Date is the the timestamp
20220822
- Spring boot
- cron scheduling
- spring cron generator/explanation (with cron code)
* "0 0 * * * *" = the top of every hour of every day. * "*/10 * * * * *" = every ten seconds. * "0 0 8-10 * * *" = 8, 9 and 10 o'clock of every day. * "0 0 8,10 * * *" = 8 and 10 o'clock of every day. * "0 0/30 8-10 * * *" = 8:00, 8:30, 9:00, 9:30 and 10 o'clock every day. * "0 0 9-17 * * MON-FRI" = on the hour nine-to-five weekdays * "0 0 0 25 12 ?" = every Christmas Day at midnight
20220816
- AWS S3
- 存取控制清單(Access Control List, ACL
Timeout waiting for connection from pool while calling S3client.getObject
20220814
- Spring boot
- RestTemplate
- https://openhome.cc/Gossip/Spring/RestTemplate.html
- https://elim168.github.io/spring/bean/30.Spring%E4%B9%8BRestTemplate%E4%BB%8B%E7%BB%8D.html#:~:text=RestTemplate%E6%98%AFSpring%20Web%E6%A8%A1%E5%9D%97,RestTemplate%E6%93%8D%E4%BD%9C%E5%B0%86%E9%9D%9E%E5%B8%B8%E6%96%B9%E4%BE%BF%E3%80%82
- https://www.796t.com/article.php?id=38894
- https://zhuanlan.zhihu.com/p/78261630
- RestTemplate
- Apache JMeter
- designed to load test functional behavior and measure performance. It was originally designed for testing Web Applications but has since expanded to other test functions.
- https://jmeter.apache.org/download_jmeter.cgi
- https://ithelp.ithome.com.tw/articles/10203900#:~:text=%E7%B0%A1%E4%BB%8B,Mac%20OS%20X%20%E4%B8%8A%E5%9F%B7%E8%A1%8C%E3%80%82
- https://ithelp.ithome.com.tw/articles/10186852
- https://stackoverflow.com/questions/22610316/how-do-i-install-jmeter-on-a-mac
20220811
- Freemarker
freemarker.template.TemplateNotFoundException: Template not found for name “xxx.ftl“
<!-- example V1 --> <!-- put below in <build></build> in pom.xml --> <resources> <resource> <directory>${basedir}/src/main/java</directory> <includes> <include>**/*.*</include> </includes> <excludes> <exclude>**/*.java</exclude> </excludes> <filtering>false</filtering> </resource> </resources> <!-- example V2 --> <resources> <resource> <directory>src/main/resources</directory> <includes> <include>**/*.*</include> </includes> </resource> </resources>
20220809
- AWS S3
- download s3 file by the URL in a browser
- presigned URL from S3 object
20220806
- Spring boot
- 跨域訪問
- jsoup
- CORS (cross-origin resource sharing)
- 跨域訪問
20220805
- FreeMarker
Apache FreeMarker™ is a template engine: a Java library to generate text output (HTML web pages, e-mails, configuration files, source code, etc.) based on templates and changing data.- https://freemarker.apache.org/
- http://freemarker.foofun.cn/index.html
- http://blog.appx.tw/2017/05/10/freemarker1/
- http://blog.appx.tw/2017/05/11/freemarker2/
- DB
20220804
- Apollo
conf ordering : Apollo VS local conf (e.g. application.yml, bootstrap.properties..)- https://www.modb.pro/db/126648
- https://blog.csdn.net/lonelymanontheway/article/details/119968760
- Conclusion :
will load Apollo conf only if both (Apollo, local) are set
20220803
- AWS
- Spring cron setting (e.g. :
@Scheduled(cron = "0 0 12 * * * ")) lombok @Accessors(chain=true)https://blog.51cto.com/wangzhenjun/4314997
// traditional
Person person = new Person();
person.setName("wang");
person.setSex("male");
person.setEmail("123@XXX.com");
person.setDate(new Date());
person.setAddr("NY");
// with @Accessors(chain = true)
Person person = new Person();
person.setName("wang").setSex("male").setEmail("123@xxx.com").setDate(new Date()).setAddr("NY");20220802
- XXL-JOB
- Java AWS S3 SDK
import com.amazonaws.services.s3.AmazonS3;
import com.amazonaws.services.s3.AmazonS3ClientBuilder;
import com.amazonaws.services.s3.AmazonS3URI;20220731
- Java
20220728
- Java
- JSONObject -> HashMap
- Python
- GIL(Global Interpreter Lock)
- GIL VS regular lock, and their low level implementation
- Mutable & Immutable Objects in Python
- python multiprocessing vs multithreading
20220727
- Airflow
- Airflow as KafkaProducer, send event to kafka topic
- Backend
- Distributed lock -
Zookeeper, Redis, MysqlZookeeperis better solution in general- https://codertw.com/%E7%A8%8B%E5%BC%8F%E8%AA%9E%E8%A8%80/717420/
- https://www.796t.com/p/1123418.html
- https://gitbook.cn/books/5dd75cffd251cc422ab2e7fb/index.html
- https://blog.yowko.com/redlocknet-redis-lock/
- https://yuanchieh.page/posts/2020/2020-01-14_redis-lock-redlock-%E5%8E%9F%E7%90%86%E5%88%86%E6%9E%90%E8%88%87%E5%AF%A6%E4%BD%9C/
- https://redis.io/docs/reference/patterns/distributed-locks/
- ScheduledThreadPool (Java)
- Distributed lock -
20220726
- Spring boot form
- Mybatis
- via
resultMapdo java attr - Db column name mapping org.apache.ibatis.binding.BindingException: Invalid bound statement (not found)error- https://blog.csdn.net/weixin_43570367/article/details/103147854 -> can try to rebuild maven project first
- via
20220724
- Nginx :
Reverse Proxy web server- Web Serveer VS Application Server, Forward Proxy VS Reverse Proxy, 反向代理
- https://medium.com/starbugs/web-server-nginx-1-cf5188459108
- https://www.maxlist.xyz/2020/06/18/flask-nginx/
- https://zh.m.wikipedia.org/zh-hant/Nginx#:~:text=Nginx%EF%BC%88%E7%99%BC%E9%9F%B3%E5%90%8C%E3%80%8Cengine%20X,%E5%85%AC%E5%8F%B8%E4%BB%A5%E6%8F%90%E4%BE%9B%E6%94%AF%E6%8C%81%E6%9C%8D%E5%8B%99%E3%80%82
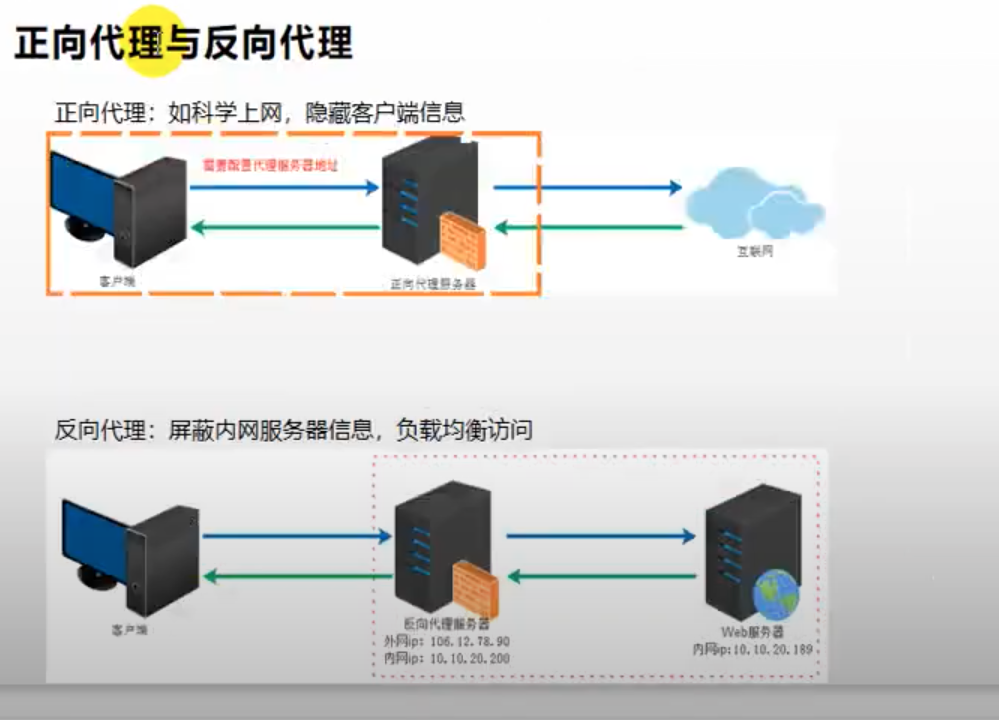
- 前向代理(Proxy)(網路代理)
- 也稱網路代理,是一種特殊的網路服務,允許一個終端(一般為客戶端)通過這個服務與另一個終端(一般為伺服器)進行非直接的連接。一些閘道器、路由器等網路裝置具備網路代理功能。一般認為代理服務有利於保障網路終端的隱私或安全,在一定程度上能夠阻止網路攻擊。
- 前向代理作為客戶端的代理,將從網際網路上取得的資源返回給一個或多個的客戶端,伺服器端(如Web伺服器)只知道代理的IP位址而不知道客戶端的IP位
- https://zh.wikipedia.org/zh-tw/%E4%BB%A3%E7%90%86%E6%9C%8D%E5%8A%A1%E5%99%A8
- 反向代理
- 反向代理在電腦網路中是代理伺服器的一種。伺服器根據客戶端的請求,從其關聯的一組或多組後端伺服器(如Web伺服器)上取得資源,然後再將這些資源返回給客戶端,
客戶端只會得知反向代理的IP位址,而不知道在代理伺服器後面的伺服器叢集的存在。 - 而反向代理是作為伺服器端(如Web伺服器)的代理使用,而不是客戶端。客戶端藉由前向代理可以間接存取很多不同網際網路伺服器(叢集)的資源
- https://zh.wikipedia.org/zh-tw/%E5%8F%8D%E5%90%91%E4%BB%A3%E7%90%86#:~:text=%E5%8F%8D%E5%90%91%E4%BB%A3%E7%90%86%E5%9C%A8%E9%9B%BB%E8%85%A6,%E4%BC%BA%E6%9C%8D%E5%99%A8%E5%8F%A2%E9%9B%86%E7%9A%84%E5%AD%98%E5%9C%A8%E3%80%82
- 反向代理在電腦網路中是代理伺服器的一種。伺服器根據客戶端的請求,從其關聯的一組或多組後端伺服器(如Web伺服器)上取得資源,然後再將這些資源返回給客戶端,
-
-
- Web Serveer VS Application Server, Forward Proxy VS Reverse Proxy, 反向代理


20220722
- Mybatis plus
- queryWrapper
- com.baomidou.mybatisplus.extension.service.impl.ServiceImpl
20220719
- Java
20220718
- Spring boot
- POJO、PO、DTO、VO、BO
- brief :
- PO (persistent object)
- DTO (Data Transfer Object)
- VO (value object)
- DAO (data access object)
- BO (business object)
- Ref :
- brief :
- POJO、PO、DTO、VO、BO
20220716
- Mybatis grammer
- dynamic SQL
- Postman
- HTTP request to
gray deployment- TODO
- HTTP request to
- Devop
- Using Services to Implement Simple Grayscale Release and Blue-Green Deployment
20220715
- Java
20220709
- Mybatis paging (分頁)
- https://www.cnblogs.com/tanghaorong/p/14017180.html
- https://tw.gitbook.net/mybatis/mybatis_pagination.html
- https://blog.csdn.net/feinifi/article/details/88769101
- https://juejin.cn/post/6996303139540467749
- https://aijishu.com/a/1060000000023074
- https://www.google.com/search?q=mybatis+%E5%88%86%E9%A0%81&rlz=1C5CHFA_enTW908TW908&oq=mybatis+%E5%88%86%E9%A0%81&aqs=chrome..69i57j0i5i30j0i8i30.3887j0j7&sourceid=chrome&ie=UTF-8
- code
- https://github.com/yennanliu/SpringPlayground/blob/dev-017-prod-api-group-sub-group/springEcommerceGuli/backend/EcommerceGuli/gulimall-product/src/main/java/com/yen/gulimall/product/config/MybatisConfig.java
- https://github.com/yennanliu/SpringPlayground/tree/dev-017-prod-api-group-sub-group/springBasics/PaginationDemo
20220708
- Mybatis
20220705
- Mysql
20220703
- Spring Boot
20220701
- Spring Boot
20220629
- Spring boot
Error creating bean with name 'dataSource' defined in class path resource@RequestBody VS @RequestParam- POSTMAN sends user-defined-class with
@RequestParamvia GET request
20220627
- Micro service
- CircuitBreaker (服務熔斷)
- Spring boot
- Paging
- Unit test
20220624
- MyBatis
- mapper.xml, java bean - JDBC table col name mapping
- enable camel style (java bean <-> SQL fields)
Pom.xml- scope (e.g.
<scope>compile</scope>,<scope>provided</scope>...)
- scope (e.g.
20220622
-
Mybatis
Error:java: Can‘t generate mapping method with primitive return type.
-
Mybatis plus
-
mysql insert with increment id
20220621
- Maven (pom.xml)
- Mybatis dynamic SQL
- spring-cloud-starter-feign
20220617
- Spring boot
- @RestController VS @Controller
- 如果返回 String 或者 json 的話就直接類上用 @RestController
- 如果想要頁面跳轉的話,就使用 @Controller
- 如果只有在某方法上返回 json,其他方法跳轉頁面,則在類上新增 @Controller,在需要返回 String 和 json 的方法上新增 @ResponseBody 註解
- https://www.796t.com/content/1546330804.html
- https://blog.csdn.net/ld1170813335/article/details/78690713
- @RestController VS @Controller
20220615
- Spring boot/cloud
- use user-defined modules
- Download API code example
- https://www.callicoder.com/spring-boot-file-upload-download-rest-api-example/
- http://www.mastertheboss.com/jboss-frameworks/resteasy/using-rest-services-to-manage-download-and-upload-of-files/
- https://www.devglan.com/spring-boot/spring-boot-file-upload-download#:~:text=Spring%20Boot%20File%20Download%20from%20Local%20File%20System&text=It%20is%20a%20simple%20GET,as%20application%2Foctet%2Dstream.
- Spring Boot + AWS S3 Download Bucket File
20220614
- Deployment Strategies:
Blue-Green, Canary (AKA 灰度發布 gray deployment), Red-Black Deployment- https://harness.io/blog/continuous-verification/blue-green-canary-deployment-strategies/
- https://segmentfault.com/a/1190000040892537/en
- https://dev.to/mostlyjason/intro-to-deployment-strategies-blue-green-canary-and-more-3a3
- http://www.uj5u.com/qita/281580.html
- https://codertw.com/%E7%A8%8B%E5%BC%8F%E8%AA%9E%E8%A8%80/725615/
- Red-Black Deployment
20220606
- Spring boot
- BeanUtils.copyProperties
- Mybatis plus
- AWS
20220604
- Spring boot
- ApplicationRunner VS CommandLineRunner
- https://segmentfault.com/a/1190000039421968
- https://juejin.cn/post/6844903589232508942
- https://blog.csdn.net/qq_20919883/article/details/111412077
- https://www.gushiciku.cn/pl/pZxA/zh-tw
- ApplicationRunner跟CommandLineRunner是區別是在run方法裡接收的參數不同,
- CommandLineRuner接收的參數是String... args
- ApplicationRunner的run方法的參數是ApplicationArguments
- ApplicationRunner VS CommandLineRunner
20220603
- Apache Dubbo
- Spring Cloud
- https://www.youtube.com/watch?v=P5o-6Od5cfc&list=PLmOn9nNkQxJESDPnrV6v_aiFgsehwLgku&index=34
- https://www.gushiciku.cn/pl/pUgh/zh-tw
- https://ithelp.ithome.com.tw/articles/10192488
- https://zhuanlan.zhihu.com/p/369125275#:~:text=Spring%20Cloud%E6%98%AF%E4%B8%80%E4%B8%AA%E4%B8%80,%E5%92%8C%E9%9B%86%E7%BE%A4%E7%8A%B6%E6%80%81%E7%AE%A1%E7%90%86%E7%AD%89)%E3%80%82
20220601
- DW layer :
ODS,DM,DWD,DWS,DIM- https://help.aliyun.com/apsara/enterprise/v_3_15_0_20210816/dide/enterprise-ascm-user-guide/overview-of-data-warehouse-planning-1.html
- https://blog.51cto.com/u_15162069/2772331
- https://blog.csdn.net/pmdream/article/details/113601956
- https://chowdera.com/2021/12/202112310752342124.html
- https://www.cnblogs.com/yoyo008/p/15213829.html
20220531
- Spring boot
Consider defining a bean of type ‘xxx.mapper.UserMapper‘ in your configuration
- Project management
- PRD (business requirements document)
- The BRD describes the problems the project is trying to solve and the required outcomes necessary to deliver value.
- https://www.lucidchart.com/blog/tips-for-a-perfect-business-requirements-document#:~:text=The%20foundation%20of%20a%20successful,everyone%20on%20the%20same%20page.
- PRD (business requirements document)
20220530
- REST request
PUT VS POST- https://blog.51cto.com/u_15301829/3095822#:~:text=%E5%9C%A8http%E4%B8%AD%EF%BC%8Cput%E8%A2%AB,%E7%9A%84%EF%BC%8C%E9%82%A3%E5%B0%B1%E6%98%AF%E5%B9%82%E7%AD%89%E3%80%82
- https://www.w3help.cc/a/202109/1093210.html
- https://hackmd.io/@monkenWu/Sk9Q5VoV4/https%3A%2F%2Fhackmd.io%2F%40gen6UjQISdy0QDN62cYPYQ%2FHJh9zOE7V?type=book
20220528
- JMS (Java Message Service) VS RabbitMQ
- RabbitMQ
20220527
- Postman
- send request via raw paste
20220526
- Spring boot
- Flyway : DB migration (version control)
20220523
20220522
- Spring boot
- webflux : sync, async request
- Data
- data validation
- Integrity
- Uniqueness
- Consistency
- Accuracy
- Delay
- data validation
20220521
-
Internet
cert驗證機制- API cert ? (SSL relative)
- DNS
-
Spring boot
- mybatis plus
- JPA
20220519
- Spring boot
- DW/DB
20220514
- Spring boot
@bean@Autowired- 透過AppConfig元件進行建立兩項Bean類別元件,當我們服務啟動的時候,會自動將Bean載入Spring IoC容器中,故我們亦可透過ApplicationContext方式取得Bean類別,亦可透過註解方式(@Autowired)獲取Bean類別
20220426
- CS general
20220425
- Java Spring
- https://www.baeldung.com/spring-cloud-netflix-eureka : Introduction to Spring Cloud Netflix
- https://netflix.github.io/ : netflix oss
- https://spring.io/projects/spring-cloud-netflix : Spring Cloud Netflix
- CS general topics
- https://hexus.net/tech/tech-explained/ram/702-ddr-ii-how-it-works/ : DDR II : how it works
- https://en.wikipedia.org/wiki/Round-robin_scheduling : round robin scheduling
- https://en.wikipedia.org/wiki/C10k_problem : c10k problem
20220418
- GraphQL
20220406
- GraphQL
20220401
- DB
- Hbase
- dynamoDB
- column based VS row based storage
20220323
- GraphQL
20220322
- Scala
- make GraphQL API call with scala
- Java
- reflection, dynamic Proxy
- API
- Comparing API Architectural Styles: SOAP vs REST vs GraphQL vs RPC
20220321
- Java
- JVM error handling
- how to config different apps run with different conf in SAME JVM
- different spring aps run in the same JVM for example
20220314
- webSocket
20220313
- Hexo : tool for static personnel site
20220223
- Python
- Sorting time complexity
- quick sort : O(NlogN) ~ O(N**2)
- merge sort : O(NlogN) ~ O(N**2)
- arr.sort() # time complexity ? -> use quick sort by default
- py OOP
- https://learn.markteaching.com/%E3%80%90python-%E6%95%99%E5%AD%B8%E3%80%91oop-%E7%B9%BC%E6%89%BF-%E5%B0%81%E8%A3%9D-%E5%A4%9A%E5%9E%8B-%E5%9F%BA%E6%9C%AC%E7%94%A8%E6%B3%95-example/
- https://www.learncodewithmike.com/2020/01/python-class.html
- https://june.monster/python-101-object-oriented-programming/
- Sorting time complexity
20220209
- Scala/Java
- MockConsumer : for kafka unit test
20220208
- Scala
- Python
20220207
- Spark
20220125
- Kafka
- get offset (per topic, partition)
- https://gist.github.com/erhwenkuo/019ada38e645b4b76862918fe5205c9c
- https://gist.github.com/erhwenkuo/bc4020112367af7abb78357963306ce0
- Flink
- kafka client
- https://github.com/yennanliu/scala-kafka-client/blob/master/akka/src/main/scala/cakesolutions/kafka/akka/TrackPartitions.scala
- https://github.com/yennanliu/KafkaHelloWorld/tree/master/src/main/scala/Consumer
- https://github.com/yennanliu/KafkaHelloWorld/blob/master/src/main/scala/common/KafkaProducerRecord.scala
- kafka client
20220124
- Flink
- implement
FlinkKafkaConsumerread kafka traffic indefined period
- implement
20220120
- Flink
- bugs :
org.apache.flink.runtime.fs.hdfs.HadoopRecoverableFsDataOutputStream.safelyTruncateFile - kafka consumer with custom offset
- bugs :
20220115
- Python
- Java
20220105
- Spark
- write to HDFS setting
- https://spark.apache.org/docs/2.3.0/configuration.html
- https://www.cnblogs.com/chhyan-dream/p/13492589.html
- If you plan to read and write from HDFS using Spark, there are two Hadoop configuration files that should be included on Spark’s classpath:
- hdfs-site.xml, which provides default behaviors for the HDFS client.
- core-site.xml, which sets the default filesystem name.
- The location of these configuration files varies across Hadoop versions, but a common location is inside of /etc/hadoop/conf. Some tools create configurations on-the-fly, but offer a mechanism to download copies of them. To make these files visible to Spark, set HADOOP_CONF_DIR in $SPARK_HOME/conf/spark-env.sh to a location containing the configuration files.
- write to HDFS setting
20211221
- Flink
- Flink internal memory model
20211215
- Scala
20211208
- Spark3
- https://spark.apache.org/docs/latest/monitoring.html : Monitoring and Instrumentation
20211207
- Flink
- Rolling policy
- file sink cycle
- conf checks
20211203
- Flink
- flink memory management ref
- https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/memory/mem_setup_tm/
- https://nightlies.apache.org/flink/flink-docs-release-1.12/deployment/memory/mem_setup.html#configure-total-memory
- https://www.modb.pro/db/142743
- https://www.gushiciku.cn/pl/abdS/zh-hk
- https://jxeditor.github.io/2020/12/14/Flink%E7%B3%BB%E7%BB%9F%E9%85%8D%E7%BD%AE%E5%8F%82%E6%95%B0%E4%B8%80%E8%A7%88/
- flink memory management ref
20211110
-
Java
- java.lang.OutOfMemoryError: unable-to-create-new-native-thread
-
Spark stream foreachRDD
20211109
- Spark
- SF : Understanding Spark serialization
20211108
- Spark
20211026
-
Scala
-
Spark
- Spark Standalone Mode
20210923
- Python
20210912
20210908
- Python
if __name__ == '__main__'
- Java
20210722
- Scala
- generic type
- upper/lower bound
20210720
- Java
- mini progrject : Employer system
- Scala
- flat map
transform tofor - design pattern
- proxy
- decorator
- flat map
- Flink
- SQL, Table API
- status programming
- exactly once
20210717
-
Java
-
Flink
-
Spark
- make Spark CAN coneect to remote HIVE
- put core-site.xml .... in main/resources ->
- make Spark CAN coneect to remote HIVE
-
Scala
- RMI in Scala
- FP map filter and remove
20210716
- Java
- Hadoop filesystem for HDFS IO
20210703
- Java
- Scala
- Design pattern : factory
- Design pattern : abstract factory
20210702
- Java
- Spark
- combineByKey
- Flink
- Window API
20210629
- Spark
- spark.speculation (Boolean)
If set to "true", performs speculative execution of tasks. This means if one or more tasks are running slowly in a stage, they will be re-launched.- https://spark.apache.org/docs/2.3.0/configuration.html
- https://stackoverflow.com/questions/45265682/speculative-execution-mapreduce-spark
- spark.speculation (Boolean)
20210624
- Spark stream
- spark stream save offset (in java)
- spark stream Spark Streaming
numRecords must not be negativeerror
20210612
- https://medium.com/erens-tech-book/%E7%90%86%E8%A7%A3-process-thread-94a40721b492
- https://docs.python.org/zh-tw/3.8/library/collections.html#collections.defaultdict
20210531
- Flink
- keyedStream and its op
- datastream -> keyedStream
- datastream op
20210530
- Scala
- AKKA mini project : yellow chicken messenger
- AKKA internet programming (via pcpip)
- closure, curry review
- AKKA mini project : yellow chicken messenger
- Java
- abstract class, method, examples
- polymorphism, downcasting review
- Spring framework
- search twitter via controller
- code review
- Flink
- DataStream API : basics
- DataStream API : transformation
- DataStream API : aggregation
- user defined source
- Hadoop
- file IO upload (via java client)
- file IO download (via java client)
- check file or directory (via java client)
- Django
- ListView, DetailView
20210517
- Flink
- Spark
- aggregatedBykey -> foldedBykey -> reducedBykey
- Java
- block : more examples (static block, regular block)
20210516
- Hadoop
- java client app : more file IO demos
20210515
- Hadoop
- java client app : file IO, file delete, repartition
- Spark
- reducebyKey VS groupby
- map source code
- Scala
- AKKA intro
- AKKA factory
- AKKA actror
- async
- Java
- singleton use cases
- "餓漢式" VS "懶漢式" and its demo code
20210512
- Flink
- Rolling policy
- Row-encoded Formats
- Custom RollingPolicy : Rolling policy to override the DefaultRollingPolicy
- bucketCheckInterval (default = 1 min) : Millisecond interval for checking time based rolling policies
- Bulk-encoded Formats
- Bulk Formats can only have
OnCheckpointRollingPolicy, which rolls (ONLY) on every checkpoint.
- Bulk Formats can only have
- ref1
- ref2
- ref3
- ref4
- Row-encoded Formats
- Rolling policy
- Hadoop
- distcp command argument
20210511
- Scala
- build.sbt shadow dependency when assembly to jar
20210510
- Java
- static intro
- static method, use example, use case
- Spark
- zip
- Hadoop
- java client install, intro
20210509
- Django
- Flink
- submit jobs
- stand alone VS yarn
- stand alone VS yarn architecture
- Note : only stand alone mood has
flink UI(or will use yarn UI) - flink CLI
- core cocept : task manager, job manager, resource manager task slot... ( may different in stand alone VS yarn mood)
20210508
- AWS EMR
- basics : master node, task node, worker node ..
- how namenode, datanode installed in EMR clusters
- minimum requirement for a working EMR clusters
- hive : basics
- hive 1.x over mapreduce VS hive 2.x on tez
- beestream
20210507
- HDFS
- Spark
- union, intersect, Cartesian product
20210506
- Flink
- save kafka event to HDFS
20210505
- Flink
- process from socket
- process from kafka
- process from socket and save to HDFS
- submit job command to local job manager
- stand alone mood VS job manager- task manager - worker mode
- Spark
- source code : repartition VS coalesce
- source code : filter
- source code : distinct
- process stream from multiple kafaka topic and save to different HDFS bucket
20210503
- Java
- class Encapsulation
- Spark
- RDD partition, map, flatMap source code go through
- Hadoop
- hdfs architecture
- basic
- HA
- data block & size -> default block size : 128 MB
- common hdfs issues
- factors affect HDFS IO speed
- partition
- block size
- file counts
- hard disk speed (data transmission)
- metastore
- hdfs architecture
20210501
- DynamoDB
- read capacity unit (RCU)
- write capacity unit (WCU)
- architecture
- index, secondary index
- sorting key
- partition
- read/write consistency
- basic commands
20210430
- Scala
- mini project : customer system - modify/delete customer
- Java
- unit-test intro
- toString, equals re-write
- Django
- user permission, comment permission
- local auth, comment auth
20210429
- Spark
- mapPartition - define partition explicitly
- "nearby rules" ( mapping with anonymous func)
20210427
- Scala
- Java
20210426
- Spark
- Scala
- mini project : customer system - adding customer
- Java
==VS equals- re-write
equals
- Hadoop
- hadoop source code intro
- compile Hadoop source code
- Flink
- submit task, and test
20210425
- Java
==introequalsintro
20210424
- Java
- object's finalize() method
- java's gc (garbage collection) mechanism
- Spark
- spark core source code visit
- ways create RDD
- defince RDD partition explicitly
- Hadoop
- sync time within clusters
20210421
- Scala
- Java
- polymorphism upcasting
- polymorphism downcasting
20210418
- Hadoop
- Thing to note when lanuch hadoop cluster in "distributed" mood
20210417
- Django
- form model (generate form from Django class)
- login auth
- Scala
- DatetimeUtils
- Java
- polymorphism examples
- Spark
- stand alone VS yarn VS local
- spark yarn mood job history config setup
20210416
- Java
- polymorphism intro
- Scala
- "control abstraction"
20210415
- Spark
- case class -> RDD -> df (?)
- Array -> RDD -> df
- df -> Parquet (append mood)
20210413
- Python
- multi processing
- multi threading
20210410
- Django
- form interact with views, urls and DB
- Scala
- Currying Function
- closure
- Java
- steps by stpes : children class instantiation
- Spark
- SparkYarnCluster running mode intro
20210409
- MapReduce
- MapReduce OOM exception (out of memory)
- Hadoop Streaming
- Java
- super call attr, methods...
- super call constructor
- Spark
-
- SparkYarnStandAlone running mode intro
-
20210408
- Zookeeper
20210407
- Scala
20210406
- Java
- override details
20210405
- Scala
- anonymous function
- Java
- debug in Eclipse
- debug in Eclipse in a project
- Saprk
- spark stand alone architecture
- spark stand alone env setup/build
20210404
- Scala
- partialFunction
- Django
- model
- admin app
20210401
- gRPC intro : ref
- Java
- Spring
- cache
- Spring
- Hadoop
- checksum
- FileSystem javs class
20210331
- Scala
- pattern matching "nest structure" 1
- Java
- Inheritance intro
- Spark-stream
20210330
- Scala
- pattern matching "inner" expression :
case first::second::rest => println(first, second, rest.length)
- pattern matching "inner" expression :
- Java
- mini project : CMutility
- project summary
- mini project : CMutility
- Hadoop
- scp
- sudo chown give file permission from root to user : code
- Docker support file system
20210329
- Scala
- case class
- Java
- mini project : CMutility
- "CustomView" delete client
- mini project : CMutility
- Distcp
- what if file already existed in the "destination path" ?
- https://hadoop.apache.org/docs/current/hadoop-distcp/DistCp.html
- By default, files already existing at the destination are skipped (i.e. not replaced by the source file). A count of skipped files is reported at the end of each job, but it may be inaccurate if a copier failed for some subset of its files, but succeeded on a later attempt.
- atomic commit
- https://hadoop.apache.org/docs/current/hadoop-distcp/DistCp.html
-atomic {-tmp <tmp_dir>}-atomic instructs DistCp to copy the source data to a temporary target location, and then move the temporary target to the final-location atomically. Data will either be available at final target in a complete and consistent form, or not at all. Optionally, -tmp may be used to specify the location of the tmp-target. If not specified, a default is chosen. Note: tmp_dir must be on the final target cluster.
- what if file already existed in the "destination path" ?
20210328
- Scala
- var match pattern
- for loop match pattern
- Nest class (inner, outer) review
- Java
- mini project : CMutility
- "CustomView" delete/modify client
- mini project : CMutility
- Django
- restaurants app
- views, urls, db model, db migration
- restaurants app
20210326
- Scala
- pattern match with tuple
- Java
- mini project : CMutility
- "CustomView" development
- mini project : CMutility
- Flink
- env set up (config, scripts) intro
20210325
- Airflow
20210324
- Scala
- pattern match with List, class array
- Airflow
20210323
- Airflow
- Hadoop
- Hadoop run jar (built from scala)
20210322
- Scala
- value with pattern match
- Spark-streaming
- updateStatusBykey more examples
20210321
- Airflow
- dynamic workflows in DAG
- Scala
- pattern match "daemon"
- pattern match more examples
- Java
- import
- MVC more understanding
20210320
- Scala
- Java
- package intro
- MVC intro
- Spark-streaming
- transform
- updateStatusBykey
20210319
- Server
- generate public key so can ssh connect to remote server : ref : useful for airflow
- Unix
- Hadoop
20210318
- Scala
- group op : stream, view, concurrent
- Java
thisexample,thiscall constructor
20210311
- Java
- Encapsulation basic usage
- Scala
- flatMap, filter (functional programming)
- Spark
- executor memory
- executor OOM
- groupBykey
- cache VS persist
20210310
- Java
- Scala
- Map operation (functional programming)
- high order function intro
- ref
- Functions that accept functions
20210309
- Hive
- make db, create table, load jar, load data, add partition : ref code
- Bash
- Scala
- set
- Java
- Encapsulation implementation (getter, setter)
20210308
- HDFS
- Java
20210307
- Java
- Encapsulation intro
- Scala
- Map (immuatable, mutable)
- Map create, get values from Map
- go through Map, add/delete elements from Map
- HDFS
- Flink
20210306
-
Scala
-
Spark-streaming
- digest from kafka (low level api)
-
Hadoop
20210305
- Spark-streaming
- Kafka integration : spark-streaming-kafka jar
- KafkaUtils : read stream from kafka
- KafkaCluster : save the offset
- mainly using kafka
low levelAPI- low level : Direct Dstrean
- high level : Receiver Dstream
- ref
- Kafka integration : spark-streaming-kafka jar
- Scala
- Queue op : enqueue, dequeue, last, head...
- Java
- class design part 2, class in-memory (stack, heap)
- Spring with css, jquery
- Apache Flume :
- Kafka:
- kafka connect:
- Big Data SMACK:
Apache Spark, Mesos, Akka, Cassandra, and Kafka
20210304
- Scala
- Queue : basic ops
- Spark
- spark read ORC data : ref
# pyspark
orc_data = spark.read.orc(orc_path)
orc_data.createOrReplaceTempView("orc_table")20210303
- Scala
- List basics ops 1-3
- tuple
- Scala object <--> Java object
- Java
- recursion
- method pass dynamic param
20210302
- Scala
- apply re-visit
- case class VS case class instance
- HDFS
- stale datanode
20210301
- Java
- value transfer : basic data structure
- value transfer : reference class/array
- Scala
- Java collections <--> Scala collections
- 1-D, N-D (dimension) array
- tuple
- list
- update list method : (1), (2)
20210228
- Scala
- dynamic array
- 1-D (dimension) array
- immutable, mutable relation
20210225
-
Java
- Lambda function
- array class in-memory
-
Scala
- immutable and mutable
- immutable and mutable layer
20210224
- Spark
- Scala
20210223
-
Scala
- companion
- Object VS class : ref
-
Java
- static method/value....
20210221
- Flink
- flink save to HDFS
- flink api with scala 2.12.X (to fix)
- Luigi
- allocate workers to jobs
- Airflow
- default config, init DB get DAG reloaded
- Java
- object, class in-momory
- Spring RESTful
- Scala
- implicit value
- implicit class
- implicit method
- implicit transformation
- "class in class"
- SBT
- allocate more resources on scala/sbt build server : ref
20210217
- Hadoop
- QoS (quality of service) : use Qos deal with namenode slowdown
20210215
- Java
- class im-memory -ref
- class basics
20210214
- Flink
- scala example implementation
- Scala
- review : super in parent, children class, constructor
20210210
- Hadoop
- Hadoop rebalancing
- Hadoop NN active, standby (HA)
- Hadoop config
- Hadoop pseudo mode
- HDFS formatting
- Hadoop MR (map reduce) job (wordcount)
- Hadoop check logs
- Scala
- trait (sth similar to java interface)
- trait basics, trait "dynamic import"
- trait implementation
- Java
- interface
- Git
- git stash, git stash apply
20210201
- Scala
- Companion, Singleton
- Anonymity sub class
- abstract class
- Hadoop
- HDFS trash
- "small files" in Namenode
- copy files
- Java
- Bit operation (>>, <<, ..)
- logic operation (||, &&, |, &, ^, ...)
20210129
- Hadoop
- kerberos, core-site.xml...
- Airflow
- ssh to local machine (via insert setting to connections table in DB)
- example
- Scala
- super method, re-write method
20210125
- Hadoop
- Scala
- super method in class
- transform class type
- rewrite method
- Spark streaming
- left, right join
20210124
- Hadoop kerberos
- Hadoop realms
20210123
- Java Visibility of Variables and Methods
20210120
-
Scala
- import packages
- OOP design 1st part
-
Hadoop
- namespace intro
- connection between namenode, datanode
- set up namespace in datanode
- white, black list
-
Spark stream
- join stream
-
Airflow
- docker-compose airflow
20210114
20210112
- Scala
- constructor parameter, attribution
- @BeanProperty
- Scala class create steps
- Java
- basic data type revisit : char, double, float...
- variable
- operator
20210111
- Spark-streaming
- joining streaming to static source
20210110
- System design
- GFS (google file system)
- big table
- Scala
- constructor
- Java
- constructor
- Hadoop
- haddop 1 VS hadoop 2
- hadoop version
- hadoop ecosystem (in layers)
- hadoop architecture
20210108
- Java
- JDK, JRE, JVM
- JDK : java development kit (for java program development), including JRE.
- JRE : java runtime environment (offer environment for java program running), including JVM.
- JVM : java virtual machine (the virtual machine that runs java program).
- summary:
- JDK = JRE + development kit ( e.g. javac ..)
- JRE = JVM + JAVA SE library
- ref
- Scala
- default value, class, class Polymorphism, more OOP
- Spark-streaming
- sliding window VS tumbling window
- Hadoop
NameNode (nn): storage metadata for data, e.g. : created_time, doc name, doc structure, partition, access level ..DataNode (dn): storage data (data block) and data block informationSecondary NameNode (2nn): monitor hadoop backend processing, do snapshot on hadoop data
20210107
- Scala
- class attribute value, class member value
- default value must with explicit type
- Java
- Hadoop
- Spark-streaming
- watermarking on windows
- watermarking on output modes (append..)
20210106
- Spark-streaming
- watermark
- watermark with window
- Scala
- error handling
- exception
- try-catch-finally
- Scala OOP
- everything in Scala is "object"
20210105
20210104
- Hadoop
- klist
- kinit
- hadoop client connect to clusters
- hadoop compress
- Flink
- value broadcast
- cache
- distributed cache
- ref code
20210103
- Hadoop
- Spark-streaming
- Tumbling window VS sliding window
- Tumbling window :
Non-overlapwindow - Sliding window :
Overlapwindow
- Tumbling window :
- Tumbling window VS sliding window
20210102
- Scala
- recursion
- function
- without return : Unit
- type inference
- case class
- Spark-streaming
- working with kafka
- kafka stream serialization & deserialization
- kafka AVRO sinks
- kafka AVRO sources
- Stateless VS Stateful
- Hive
- general intro
- architecture
20201226
- Java
- Ternary Operator
- Scala
- Control logic
20201225
- Spark
- Streaming basic
- Streaming config
- Streaming from port
20201224
-
Scala
Implicitimplicitis the way that you dont need to pass parameters explicitly in functions in Scala, but Scala will be able to find them from theimplitict scopeonce you defined them. Use implicit can make your function more general and easy to import/deal with different cases per pattern- ref
- Scala
control logic(if else..)
-
HDFS
- compression HDFS file
-
Flink
- java code exmaple
- pipeline workflow
- clusters build doc
- build project with maven
-
Airflow
- work with macro, timestamp
20201223
-
Scala
- run object method directly in application scala
- Scala read std in from CLI
- Scala read args in from CLI
-
Hive
20201222
20201217
-
git
- git stash
- git stash list
- git stash pop stash@{2}
- git stash pop ( = git stash pop stash@{0})
- git stash apply stash@{0} ( = git stash pop stash@{0} )
- git stash drop stash@{0}
- ref
-
hadoop distcp arguments
-
Scala
- implicits
- partial function
- partial apply function
20201216
- sbt
- sbt docker
- Scala
- Typeconfig
- load different config
20201211
- Hadoop
- hadoop distcp
- atomic
- update
- replace
- hadoop distcp
- SBT
- sbt-docker
- sbt publish
- Scala
- AppConfig
- Configfactory
20201210
- Kafka
20201209
- Kafka
- consumer low level API
- source code go through
- Scala
- Any, AnyValue, AnyRef
- implicit transform
- can give "low level" dtype to "high level" dtype, but not vice versa
- Hive
- alter table command
- update schema
- external VS internal table
- ddl build, alter table
- sbt
- build-info
- sbt version
- sbt assembly, sbt plugin
20201125
- Scala
- comment -> auto generate API doc
- var, val point to storage space
- how scala use/re-write part of java lib as well as write itself one
- sbt publish
- Hive
- repartition
- Apache ORC
- the smallest, fastest columnar storage for Hadoop workloads.
- Jenkins
- check
.gitwhen specific branch is merged/... then run
- check
20201124
- Spark
- dataframe concat 2 / multitple columns
- saveToTable/save partition by list of columns
- data skew consideration (per executor)
- Hive
- external table
- partition
- create table from parquet file
- Airflow
- run hive distcp
- run spark
20201124
- Kafka
- Producer hive level API implementation
- kafka stream
- source code
- Scala
- scala compile process
- scala basic syntax/style revisit
- scala VS java
- Java
- Spring RESTful API dev
20201116
- Kafka
- high level API
- low level API
- re-write method
- re-load method
- Java API consumer
- Java API producer
- Zookeeper
- zookeeper file structure (storage for meta)
- Apache Flume
- Apache Nifi
- Spark
- RM (resource manager)
- AM (application manager)
20201115
- Kafka
- Java API consumer source code
- Java API producer source code
20201111
-
Hive
- save partitioned hive tabl
- insert file/HDFS file to existing hive table
-
Spark
- set up metastore, warehouse path for hive IO
- write df to hive with option
20201107
- Redis
- 5 main data structure
- Strings
- Lists
- Sets
- can save "offset" of kafka consumer, avoid "duplicated consuming" issue
- Hashes
- Sorted sets
- Bitmaps and HyperLogLogs (also supports)
- ref
- 5 main data structure
- Java
- project naming
- "domain name inverse" + "project name" + "module" + "program type"
- example:
- com.yen + bigdata.spark + services + aaa.java
- "module" : controller, service, bin...
- Multi-threading
- Multi-process
- thread
- runnable
- callable
- process cycle
- NEW
- RUNNABLE
- READY
- RUNNING
- BLOCKED
- WATING
- TIMED_WATING
- TERMINATED
- process priority
- process sleep
- process yield
- project naming
- Flink
- Watermark
- ordering stream
- non-ordering stream
- multi-thread stream
- Window
- Watermark
20201106
- Luigi
- luigi.Task
- luigi basic concepts review
- luigi get arg, config...
- Hadoop
- discp
- Hive
- hive partitioned table
- spark save to hive partitioned table
- Docker
- spark/hadoop physical/pseudo memory using setting
- Spark
- run via yarn/client...
- Python args
20201030
-
SBT
-
Spark
- Dataframe filter
df.filter("col1 not like 'MSL%' and col2 not like 'HCP%'").show- https://stackoverflow.com/questions/42951905/spark-dataframe-filter
- Dataframe filter
-
Hadoop-Spark set up via Docker-compose
20201028
- Shell
- run 1 shell func inside the other shell func
- Spark
- Spark-submit tuning : memory usage caculation
- network traffic
- more data size -> more traffic -> cost more time
20201027
- Spark
- Spark-submit config
- Spark-submit tuning
- Spark-submit with different env
- Java
- build project with maven
- maven commands
- pom.xml set up
- add dependency in pom.xml
- unit test in java
20201026
- Kafka
- partition mode
- offset background concept
- load data with load
20201020
-
Flink
- Broadcast VS accumulator
-
MongoDB
- PyMongo API : find, find_one
-
Design pattern
20201018
- Flink
- Broadcast (in DataStream/Flink)
- Java
- Random access files
- serialize/deserialize
- transform data into binary for
- transmission
- storage
- transform data into binary for
- Buffer
- NIO
20201017
-
Scala
- Class VS Object
-
Distributed system
- Load balancer -> "register center", e.g. Zookeeper
- Kafka
- Message center dispense within multiple distributed system
- Leanring resource
-
Java
- File IO
- stream transformation
- Spring framework
-
Flink
- Table api, SQL api
- Leanring resource
-
Zookeeper
- as "information center, can do some cache"
- python zookeeper client :
- Load balancer -> Zookeeper
20201014
- Python
- multi - processing
- tuning
- get pid, parent pid..
- start, join
- example
- multi - processing
- HDFS
- REST http API
- webhdfs check
- Hadoop
- kerberos
- core-default.xml
- connection auth
20201008
- HDFS
- client connect to HDFS (file IO)
- webhdfs -> simpe file move/OP
- pyarrow -> lot of files, heavy OP, or serializatio
- Java connect to HDFS
- client connect to HDFS (file IO)
20201006
- Java
- Stream
- Array List
- Flink
- Batch, Sink API
- Spark
- custom Spark shell port in config
- Kafka
- acks
- acks=0 —the write is considered successful the moment the request is sent out. No need to wait for a response.
- acks=1 — the leader must receive the record and respond before the write is considered successful.
- acks=all — all online in sync replicas must receive the write. If there are less than min.insync.replicas online, then the write won’t be processed.
- acks
20201004
- Kafka
- Asyc producer (sending msg)
- serializer - deserializer
- Flink
- Java
- Map, HashMap, HashMapTree...
20200930
- HDFS
- hdfs copy, create directory, check file size
- do above OP via python (subprocess, queue...)
20200929
- Scala
- Try orElse getOrElse
- Try catch excaption
- Try[Unit]
- Any
- HDFS
- file op, compress, ls, mv...
- Python
- subprocess
- check_output
- persist-queue
- persist-queue implements a file-based queue and a serial of sqlite3-based queues
- subprocess
20200928
- RabbitMQ
- Scala examples
- RPC (Remote procedure call) example
- API
- GRPC
- REST VS GRPC VS GRAPHQL VS OPENAPI...
- Java
- for each
- HashSet
- MapSet
- Map
- sorting
- Git
- git squash
- git log
20200927
- Flink
- config on Hadoop, Yarn
- run flink via Hadoop, stand alone
- scala Flink shell
- Hadoop
- Build hadoop namenode-datanode
- set up zookeeper
- think about HA
20200926
- Kafaka
- kfaka stream
- join
- transformation
- group by
- kafka unit test
- kfaka stream
20200924
- RabbitMQ
- config
- inport/export queue setting
- Elasticsearch
- Define logging dtype
- dtype
20200923
- RabbitMQ
- intro
- simple sender, receiver model
- working queue
- broker (exchanger)
- publish/subscribe
20200920
- Flink
- cluster mood
- standalone
- Flink on yarn
- Flink works with HDFS/yarn..
- cluster mood
20200919
- Java
- System & Runtime class
- Math & Random class
- Java basic data strcture class (byte char short long int Boolean float double )
- Scala
- logger (log4j)
- Kafka
- Partitioner
20200918
- Scala
- date format
- long
- log4j
- joda-time
- json4s
20200915
- SBT
- Java
- netty
- Common lib (java.lang)
20200913
- ES
- REST command
- ES api command
- ES general concepts
- Java
- garbage collection (GC)
20200911
- Java
- Error handling
- error
- exception
- try{} catch{Exception e}
- throws
- finally
- Error handling
20200910
- Scala
- Some
- Future (in JS as well ?)
- Finagle (lib for API/http call)
- import, re-write class, trait, method...
- Getters, Setters
20200909
- Scala
- type
- option
::- implicit - 1, implicit- 2
20200908
- Scala
- option
- this
- Future
- sbt-buildinfo
- RabbitMQ
- Spark
- regex expression in spark
20200907
- Scala
- case class
- Sealed Class
- import from compiled jar
- json4s
- Spark
- send df to ES
20200906
- Flink
- intro
20200905
- Java
- Lambda internal class
- Lambda function
- functional programming
20200904
- Dev-op
- Ansible
- IntelliJ
- ctrl + ctrl (in IntelliJ console) => find "main" script
- Scala
- Twitter-server
- SBT
- sbt run
20200903
-
Git
git fetchVSgit clonegit clone= git fetch + git merge- git fetch : only copy files from remote branch to local branch, NO MERGE
- git clone : copy files from remote branch to local branch, AND MERGE
- git merge
- git cherry-pick
- git rebase
- examples
-
Java
- Polymorphism
-
Scala
- implicit
-
BQ
- AMZ Leadership Principles
20200830
- Scala
- Implicit
- Dev-op
- Ansible playbook
- Invest
- Stock exposure
20200829
- Java
- abstract
- interface
- Python
20200828
20200827
- Spark
- load parquet
20200826
- Java
- object class
- rewrite method
- final
- Scala
- UpperCass
- option
- find
- Some
- exists
- contains
- isDefined
20200825
- Git
git rebasegit rebase --continuegit rebase --abort- ref : rebase step by step
- git pull = git clone + git merge
20200823
- Tech
- Product Development
- Agile
- Waterfall
- Java
- Class extends
- Class method
rewrite super
- Scala
super- Finatra HTTP Server
- Python
- Invest
- Basic Financial statements
- Profit and Loss Account
- Balance Sheet
- Cash Flow Statement
- Statement of Stockholders Equity
- Apple inc. 2019 Q4 financial report
- Apple inc. financial report (yahoo finance)
- Basic Financial statements
20200822
- Java
- Method reload
- Method iteration
- Method construct
thisstaticvarstaticmethodstaticcode
- Scala
- Python
- Invest