PyTorch implementation for ACL-IJCNLP 2021 Findings paper: Discriminative Reasoning for Document-level Relation Extraction
Document-level relation extraction (DocRE) models generally use graph networks to implicitly model the reasoning skill (i.e., pattern recognition, logical reasoning, coreference reasoning, etc.) related to the relation between one entity pair in a document. In this paper, we propose a novel discriminative reasoning framework to explicitly model the paths of these reasoning skills between each entity pair in this document. Thus, a discriminative reasoning network is designed to estimate the relation probability distribution of different reasoning paths based on the constructed graph and vectorized document contexts for each entity pair, thereby recognizing their relation. Experimental results show that our method outperforms the previous state-of-the-art performance on the large-scale DocRE dataset.
- Architecture
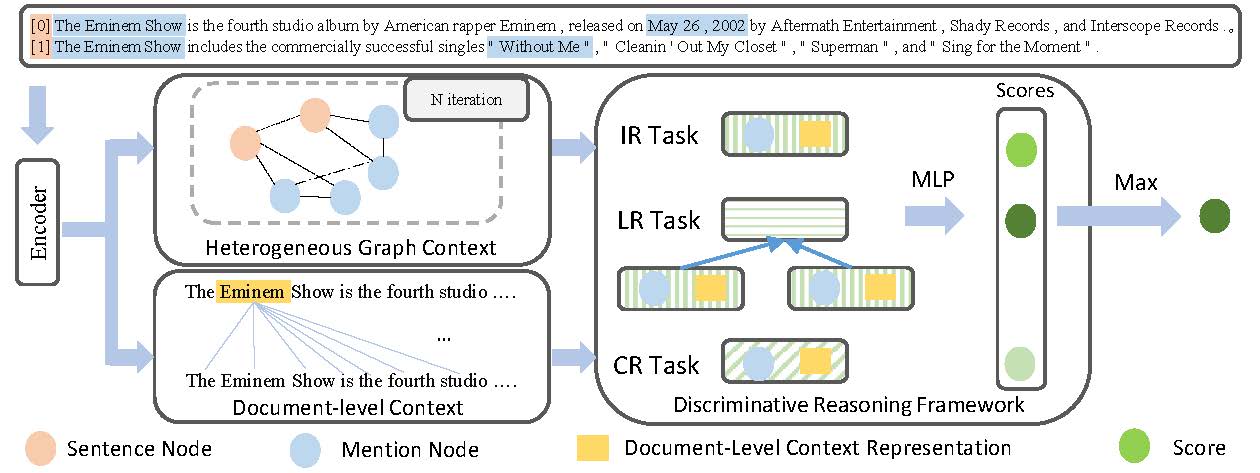

DRN/
├─ code/
├── checkpoint/: save model checkpoints
├── logs/: save training / evaluation logs
├── models/:
├── DRN.py: DRN model for GloVe or BERT version
├── taskdecompose.py: discriminative reasoning framework
├── graph.py: graph neural network module
├── config.py: process command arguments
├── data.py: define Datasets / Dataloader
├── test.py: evaluation code
├── train.py: training code
├── utils.py: some tools for training / evaluation
├── *.sh: training / evaluation shell scripts
├─ data/docred: raw data and preprocessed data about DocRED dataset
├── prepro_data/
├─ LICENSE
├─ README.md
- python (3.7.9)
- cuda (10.2)
- Ubuntu-18.0.4 (4.4.0-148-generic)
- numpy (1.19.1)
- matplotlib (3.3.1)
- torch (1.7.1)
- transformers (4.1.1)
- scikit-learn (0.23.2)
- wandb (0.10.12)
-
Download data from Google Drive link shared by DocRED authors
-
Put
train_annotated.json,dev.json,test.json,word2id.json,ner2id.json,rel2id.json,vec.npyinto the directorydata/docred/ -
If you want to use other datasets, please first process them to fit the same format as DocRED.
-
We randomly sampled 72 documents form the dev set which contain 916 relation instances, and we annotated the reasoning type. The annotated reasoning type data file is in the
data/docred/reason_type.txt. The data is formated asserial_document_id serial_instance_id document_id head_entity_id tail_entity_id reasoning_type. Reaoning type 1,2,3 is denoted as intra-sentence reasoning, logical reasoning and coreference reasoning separately.
The package transformers would take some time to download the pretrained model for the first time.
>> cd code
>> ./runXXX.sh gpu_id # like ./run_BERT.sh 2
>> tail -f -n 2000 logs/train_xxx.log>> cd code
>> ./evalXXX.sh gpu_id threshold(optional) # like ./eval_BERT.sh 0 0.5521
>> tail -f -n 2000 logs/test_xxx.logPS: we recommend to use threshold = -1 (which is the default, you can omit this arguments at this time) for dev set, the log will print the optimal threshold in dev set, and you can use this optimal value as threshold to evaluate test set.
-
You will get json output file for test set at step 5.
-
And then you can rename it as
result.jsonand compress it asresult.zip. -
At last, you can submit the
result.zipto CodaLab.
This project is licensed under the MIT License - see the LICENSE file for details.
Our code is adapted from GAIN. Thanks for their good work. If you use this work or code, please kindly cite the following paper:
@inproceedings{wangx-ACL-2021-drn,
author = {Wang Xu, Kehai Chen and Tiejun Zhao},
booktitle = {Findings of The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL 2021 Findings)},
title = {Discriminative Reasoning for Document-level Relation Extraction},
year = {2021}
}