前端发展中"大前端"被大家高频提起,那什么是"大"前端? 如何系统学习? 如何规划技术架构? 如何在实践中落地? 诸此种种"大"所产生的疑问,基于个人经验做了一些解释。 梳理出了一副结构化、详细深入、独到见解的"大前端"全景图,希望给求职、工作中的同学提供一点帮助,即便是茶余饭后的谈资,那么我的目的也就达到了。

目录
一、"大前端"的结构
(1)Web统一UI渲染
(2)大前端核心是跨平台
(3)微前端
(4)前端工程化
(5)BFF
(6)2D 图形渲染
Web端期望实现统一的UI渲染,通过复用技术通用标准、框架模式、工具,来降低开发门槛、扩宽使用场景、提升研发效率、降低维护成本。

UI层渲染核心问题
- 框架渲染问题
- 框架渲染与技术側的学习成本、开发者体验、工程效率息息相关。
- 基于开发实践出现了Template模版渲染、Virtual DOM渲染、 Canvaskit图层渲染
- 内容分发效率问题
- 内容渲染时机与用户体验需要一个平衡点,这个平衡需要考虑生产效率、分发效率。
- 例如SPA CSR兴起、SSR提升首屏体验、预渲染静态化、CDN内容动态化以及各大APP平台的NSR渲染
- 跨端开发问题
- android、ios、desktop、Smart TV等跨端上web探索,第一类是基于webview的渲染,第二类是基于数据和UI的计算合成native渲染

常见渲染层技术方案
-
- createPortal 提供了一种将子节点渲染到已 DOM 节点中的方式,该节点存在于 DOM 组件的层次结构之外
- flushSync 强制 React 同步刷新提供的回调函数中的任何更新。这确保了 DOM 会被立即更新
- hydrateRoot
- renderToPipeableStream 将一个 React 元素渲染为初始 HTML。返回一个带有 pipe(res) 方法的流,用于管道输出。abort() 用于中止请求。完美支持了 suspense 和 HTML 流,“延迟” 的内容块会通过内联的 <script> 标签嵌入
- renderToReadableStream 将一个 React 元素通过流的形式注入初始的 HTML 中
- (静态页面生成器)renderToStaticNodeStream 此方法与 renderToNodeStream 相似,但此方法不会在 React 内部创建的额外 DOM 属性,例如 data-reactroot
- renderToString 将一个 React 元素渲染成其初始的 HTML。React 将返回一个 HTML 字符串
- (静态页面生成器)renderToStaticMarkup 与 renderToString 相似,只是该方法不会创建 React 内部使用的额外 DOM 属性,如 data-reactroot
-
- 介绍:snabbdom以函数的形式来表达程序视图,但现有的解决方式基本都过于臃肿、性能不佳、功能缺乏、API 偏向于 OOP 或者缺少一些我所需要的功能
- vue vdom基于snabbdom实现

-
handlebars 模版语法 预编译类
- 数据绑定包括:表达式 {{ data.name }} 、块表达式{{#custom}}、内置块表达式{{#with}} {{#each}} 等
-
- EJS 能够缓存 JS 函数的中间代码,从而提升执行速度。例如:ejs.cache = LRU(100);
- <% 流程控制、<%- 引入包含、<%= 数据写入
-
- 介绍:由 javascript 实现的一系列 web标准,特别是 WHATWG 组织制定的DOM和 HTML 标准,用于在 nodejs 中使用。该项目的目标是模拟足够的Web浏览器子集,以便用于测试和挖掘真实世界的Web应用
优秀文档:
- Virtual DOM 的设计与实现
- VNode 的设计
- key 是 VNode 在同一父节点下的唯一标识
- type 表示 tagName,表示节点的 tag 类型
- data 是 IVNodeData 类型,包含了 节点属性、节点状态、事件 等信息
- children 表示子节点数组,对应了真实 dom 中的 childNodes
- text 表示 textContent
- elm 对应了真实 dom 元素
- isVNode 和 isSameVNode 是 VNode 相关的静态方法
- VNode生成函数
- diff 3种情况:
- 对于相同的部分,保持不变。
- 不一样,但是可复用。
- 都是文本节点,内容更新
- isSameVNode,tagName 和 key 都相同的时候,元素复用
- 都是容器节点,递归比对children
- 循环目标 children,能复用的节点,移动到当前位置,
- 没找到能复用的节点,就自己生成一个
- 多余删除
- 非尾部插入,非尾部删除处理????????
- 不一样,不能复用。
- 新节点是容器节点,旧的是文本节点。删除文本,添加新节点
- 新节点是文本节点,旧的是容器节点。删除容器节点,添加文本节点。
- VNode 的设计
- jsdom 中文介绍
- 跨平台Web Canvas渲染引擎架构的设计与思考(内含实现方案)
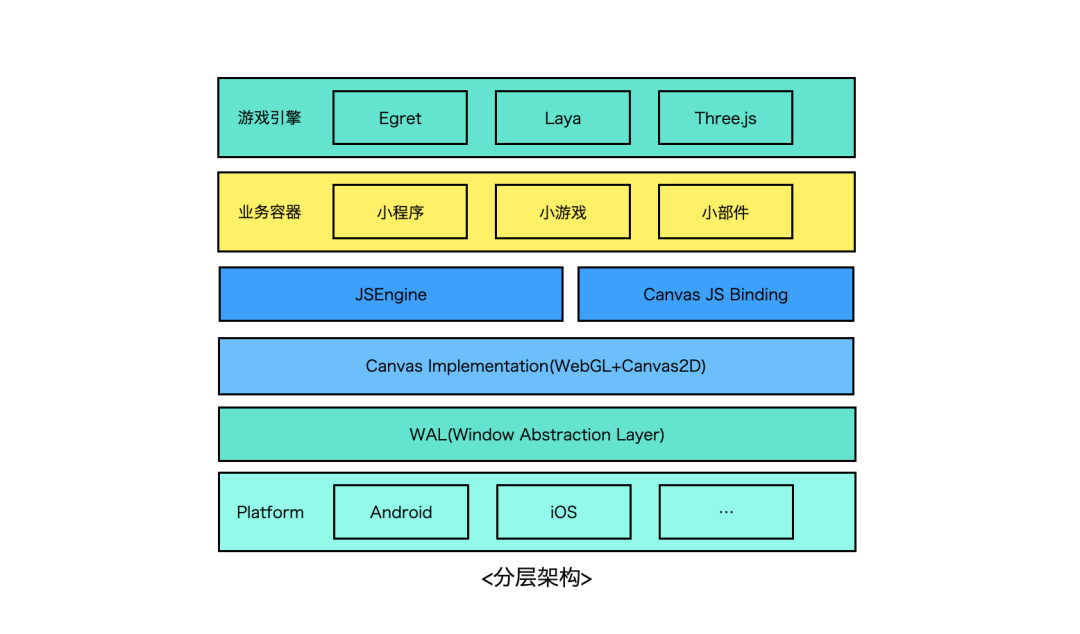
- 你知道吗?SSR、SSG、ISR、DPR 有什么区别?
- CanvasKit简介

打破平台的桎梏,是前端开发人的执念。

整体发展阶段如下:
- Hybrid APP(类原生体验)
- Cordova、Ionic
- Javascript Native APP (原生体验)
- React-native、Weex
- Flutter Native APP (原生体验)
- Flutter
- Progressive Web APP (类原生体验)
- PWA无需下载、快速启动、顺滑体验,提供可靠的、快速的、沉浸式的应用。
- 小程序 APP(类原生体验)
- weixin 、 douyin、alipay、baidu等
- 跨渠道的框架Taro、uni-app、mpvue、remax
Hybrid APP 分析

Js-bridge设计

微服务是一种开发软件的架构和组织方法,其中软件由通过明确定义的API进行通信的小型独立服务组成。把微服务的概念应用到前端, 前端微服务/微前端服务 就诞生了,简称其为微前端。
微前端框架一般具有以下三个特点:
- 技术栈无关:主框架不限制接入应用的技术栈,子应用具备完全自主权。
- 独立性强:独立开发、独立部署,子应用仓库独立。
- 增量升级
- 状态隔离:运行时每个子应用之间状态隔离。

微前端实现思路:
- 服务端集成,利用Nginx配置反向代理来实现不同路径映射到不同应用
- 运行时集成,使用 iframe ,通过配置不同的src加载不同的子应用页面
- 现有开源方案
- Single-Spa:最早的微前端框架,兼容多种前端技术栈
- 核心定义了一套协议,协议包含主应用的配置信息和子应用的生命周期,通过协议主应用可以知道在什么情况下激活哪个子应用。
- Qiankun:基于Single-Spa,阿里系开源微前端框架。
- Icestark:阿里飞冰微前端框架,兼容多种前端技术栈。
- Mooa:基于Angular的微前端服务框架
- Ara Framework:由服务端渲染延伸出的微前端框架。
- Webpack 5 Module Federation(模块联邦实现代码共享)
- 目的:一个单体应用拆分成多个独立构建,独立开发、独立部署的子模块
- 话术:本地模块和远程模块。本地模块即普通模块,是当前构建的一部分。远程模块不属于当前构建,并在运行时从所谓的容器中加载。
- 容器如何加载远程模块?即 chunk 异步加载操作,import()或者require.ensure 或 require([...])
- 容器加载如何并暴露访问?加载模块(异步的)并执行模块(同步的),容器可嵌套,循环引用
- 共享模块:既可重写的又可作为向嵌套容器提供重写的模块。可理解为每个构建中的相同模块,例如相同的库
- 模块版本问题:packageName 选项允许通过设置包名来查找所需的版本。默认情况下,它会自动推断模块请求,当想禁用自动推断时,请将 requiredVersion 设置为 false 。
- Single-Spa:最早的微前端框架,兼容多种前端技术栈
优秀文档:
什么是前端工程化?
前端工程是软件工程子类,是将软件工程的方法和原理运用在前端开发中, 目的是实现高效开发,有效协同,质量可控。 落地至技术层面是持续优化,从开发阶段的代码转变成生产环境的代码的一系列步骤。主要包括构建,分支管理, 自动化测试, 部署等。
主要看两个路径:
- 技术演化:傻瓜化 -> 模版化 -> 流程化 -> 自动化 -> 智能化
- 视角转化:工程 -> 项目 -> 团队 -> 平台 -> 开放&开源
当技术演化至流程化,需要依赖场景并结合效率、规范、安全,打造团队甚至平台级的效率工程产品。 这个过程是需要平衡的,从团队规模和业务规模上去理解,优先解决效率瓶颈、资源瓶颈,技术债务是可以后面补偿的。
工程化手段
- 前后端分离
- 前后端职责不清、沟通存在障碍、信息不透明在前端发展早期是管理问题,而今是主要是技术问题。
- 需要以代码库分离、部署分离为基础,前端保证渲染和用户交互,后端保证数据及服务稳定。
- 在协作层面,并行开发是基本要求。做到数据逻辑收敛、交互逻辑收敛。
- 那技术上到底如何厘清业务逻辑?是前端还是后端。在协作上怎样补充,需要对齐这个约定。
- 基础建设
- 模版化
- 开发模版,填充具体逻辑。(例如IDE设置代码模版)
- 示例代码,仿照创建新功能。(例如状态管理的reducer示例、部署脚本、nginx脚本、docker脚本)
- 工具化
- 大部分模版化模块可以通过工具,一键式生成。甚至通过文件系统监听,自动化生成。
- 开发过程CV操作是低效且不可靠的,因此脚手架、自定义命令,可以保证安全和一致性
- 很多技术手段是分散的,图片预处理压缩(如果项目没集成)、lighthouse跑分,可统一集成
- 套餐化
- 移动端、PC端、大屏
- 框架层react、vue、angular
- ts、postcss、tailwind、babel、editor、lint、gitignore、prettier、husky、ci/cd yml、browserslist等配置
- 根据业务场景定制,例如数据可视化、用户拖拽可编辑、纯展示类等
- Mock化
- 后台接口数据
- APP接口数据
- 本地化数据
- 流程依赖数据
- 组件化
- 基础UI组件库
- 业务组件库
- 可视化组件库
- 动效组件库
- 字体库
- 编辑器组件库(文本、流程图、脑图等)
- CI/CD
- CI 持续集成,包括代码提交、检查、构建、测试
- CD 持续部署,包括镜像或者软件包管理、部署、服务实例验证、应用监控、质量和性能预警反馈
- 服务设施
- sonar 、sentry、grafana、prometheus、k8s、dynamic polyfill、Mobile Test、sentry、gitlab
- 模版化
- 代码治理
- 应用监控
- 工程能力升级
CPU vs GPU
CPU 和 GPU 都属于处理单元,但是结构不同。
CPU 处理任务管道化,处理任务的速度完全取决于处理单个任务的时间,所以处理单个任务的能力十分的强大。
GPU 是由大量的小型处理单元构成的,一幅图像是由成千上万的像素点组成,每次处理一个像素都是一个简单任务,GPU能够保证同时处理所有的像素点。
- WebGL
- WebGL通过引入一个与 OpenGL ES 2.0 非常一致的 API 来做到这一点,该 API 可以在 HTML5 元素中使用。 这种一致性使 API 可以利用用户设备提供的硬件图形加速。
- Data in WebGL, GLSL 为 Shader 提供了三种不同作用的数据存储,每种都有一个特定的用例
- WebGL 2
- 是 WebGL 的一个主要更新,它通过WebGL2RenderingContext 接口提供。
- 它基于 OpenGL ES 3.0,新功能包括
- canvas
- Canvas API 用于在网页上进行 2D 图形处理。
WebGL渲染管线
渲染管线是显示芯片内部处理图形信号相互独立的并行处理单元,主要分为以下几步:
- 顶点着色器处理顶点 (对传入GPU中的顶点信息进行处理,需要进行裁剪空间变换、平移、缩放、旋转等操作。这些操作都是对顶点进行的,它直接改变了顶点的位置。 )
- 图元装配
- 光栅化
- 片元着色器着色
- 测试 & 混合
着色器(Shader)
着色器是一种计算程序,主要用于进行图形处理。分为如下几类:
- 顶点着色器(Vertex Shader)
- 片元着色器(Fragment Shader)
- 存储限定符
- attribute: 只能出现在顶点着色器中,表示每个顶点的数据。在光栅化过程中会对attribute变量进行插值处理。可以从外部往WebGL内部中传递数据
- uniform: 可以出现在顶点着色器和片元着色器中,表示统一的值,每个顶点/片元使用的这个值都是一样的。
- varying: 可以出现在顶点着色器和片元着色器中,表示变化的值,在光栅化阶段,GPU将attribute变量插值处理后的结果赋给了varying变量,它是链接顶点着色器和片元着色器变量之间的桥梁。
数据传递
- 传递Attribute变量 (传递attribute变量的数据需要使用 WebGLBuffer这个WebGL内置的数据结构)
- 传递Uniform变量
- 通过API获取uniform变量在WebGL程序中的地址(gl.getUniformLocation)
- 再通过API这个地址中填充数据即可(gl.uniform1f, gl.uniform1i, gl.uniform2f......)
- 传递纹理
- 创建纹理对象(WebGLTexture)(gl.createTexture())
- 绑定纹理对象(gl.bindTexture)
- 设置纹理参数
- 传入纹理(gl.texImage2D)
图片加载方式,一种是线性加载,而另一种则是渐进式加载。
什么决定了图片的加载方式呢?图片的压缩算法。
- 线性加载是离散余弦变化算法
- jpeg渐进式图片加载
选择合适的图片格式
-
JPEG(有损压缩) 适用于呈现色彩丰富的图片
- 以 24 位存储单个图,可以呈现多达 1600 万种颜色
- 把图片体积压缩至原有体积的 50% 以下时,JPG 仍然可以保持住 60% 的品质
- 处理矢量图形和 Logo 等线条感较强、颜色对比强烈的图像时,人为压缩的图片模糊会相当明显
- 不支持透明度处理
- 三种格式标准JPEG格式、渐进式JPEG格式、JPEG2000
- 四种压缩
- 基于DCT的顺序编码 线性
- 基于DCT的累进编码 渐进式
- 基于DCT的分层编码 渐进式
- 基于空间DPCM的无损压缩
-
PNG 可移植网络图形格式是由 W3C 开发的图片格式 (无损压缩的高保真的图片格式)
- 同时支持 8 位 (256 种颜色)和 24 位(1600 万种颜色)
- 对线条的处理更加细腻,对透明度有良好的支持
- 支持透明度处理,透明图片可选择使用 PNG
- LZ77派生算法压缩比率更高
- 主要用它来呈现小的 Logo、颜色简单且对比强烈的图片或背景等。
-
GIF 是一种最多支持 256 种颜色的 8 位无损图片格式
- 支持动画,适合去展示一些无限循环的动画
- 对于一些只有简单色彩的图片非常合适
- 采用LZW(串表)压缩算法进行编码
-
BMP
- 图像信息丰富
- 不进行压缩占用空间大
-
WebP
- 同时提供了有损压缩与无损压缩
- 可以显示动态图片
- 支持透明
- 移动端 IOS 系统基本不支持
点阵图和矢量图,区别在于缩放会失真
优秀文档:
- CPU versus GPU with the Canvas Web API
- 介绍:CanvasAPI是一个丰富和性能强的API,用于在Web浏览器中绘制和操作2D图形。它与HTML元素或OffscreenCanvas一起使用。当将内容渲染到canvas时,浏览器可以选择使用CPU或GPU。这篇文章着眼于浏览器是如何做出这一决定的,以及这对性能的影响。
- 浏览器策略
- 当创建Canvas时,浏览器需要考虑如何存储。它可能在主内存中存储数据,调用cpu上运行方法去渲染,也可能在GPU创建canvas,调用GPU指令绘制它。
- Media Source Extensions
云原生:云计算环境中构建、部署和管理现代应用程序的软件方法
期望应用程序具有如下特性:
- 拓展性
- 灵活性
- 弹性
从而获得收益:
- 提效
- 降本
- 高可用
云原生应用程序架构:
- 不可变基础设施
- 微服务
- 声明式API
- 容器
- 服务网格
- Amazon Identity and Access Management (IAM)
- 资源和服务的精细化控制
- 用户组 - 用户 - 角色
CSP (内容安全策略) 是一个附加的安全层,有助于探测和减轻某些类型的攻击,包括跨站脚本攻击(XSS)和数据注入攻击
- 跨站脚本攻击,CSP 的主要目标是减少和报告 XSS 攻击,通过指定有效域——即浏览器认可的可执行脚本的有效来源——使服务器管理者有能力减少或消除 XSS 攻击所依赖的载体
- 数据包嗅探攻击,除限制可以加载内容的域,服务器还可指明哪种协议允许使用
- Content-Security-Policy:default-src 'self'; img-src *; media-src media1.com media2.com; script-src userscripts.example.com
- 报告 (report-only)模式 Content-Security-Policy-Report-Only: policy
- 启用违例报告 Content-Security-Policy: default-src 'self'; report-uri http://reportcollector.example.com/collector.cgi
信息安全基本原理
混合内容 (en-US) 公钥固定 (en-US) 同源策略 安全环境 保护你的网站 子资源完整性 传输层安全协议 HTTP Public Key Pinning (HPKP) Secure contexts 弱签名算法 浏览器的同源策略 确保你的站点安全
Cookie 安全性 HttpOnly
优秀文档
V8 提供了 JavaScript 执行的运行时环境,其它Javascript引擎:SpiderMonkey、JavascriptCore、 Chakra。实现标准 ECMA ES-262 标准
- 垃圾回收机制
- 固定生命周期,分配内存、使用读写、不需要释放。在此过程中系统自动管理
- 栈的内存空间,只保存简单数据类型的内存,由操作系统自动分配和自动释放
- 堆空间中的内存,由于大小不固定,系统无法自动释放,需要JS引擎来管理释放内存
- 垃圾回收算法:标记清理、引用计数
- V8使用不同的垃圾回收器:新生代、老生代 (这是对大、长)
- 新生代垃圾回收器 - Scavenge 牺牲空间换取时间的复制算法,新生代堆分为使用区、空闲区,存活对象复制至空闲区、非存活对象释放,区域角色互换
- 老生代垃圾回收 - Mark-Sweep & Mark-Compact 即标记清除 和 标记整理
- 晋升机制,长期活跃即经历2个子代、空间占用空闲区25%。
HTTP 版本
- HTTP 0.9
- 仅支持GET请求,通过URL携带参数获得资源,无请求头。
- HTTP 1.0 (缺点:每次请求需建立新的TCP连接,资源开销、时间开销大。可手动开启keep-alive)
- 增加支持Post、Head等请求方法,增加请求头,可支持多种内容数据类型,不局限于文本格式。
- HTTP 1.1 (缺点:同一个域名6个并发连接限制,应用层队头阻塞-长响应队头阻塞)
- 默认采用keep-alive 短时复用TCP连接。
- 单个TCP同时处理一个请求
- 管道方式同一个TCP连接同时发送请求,服务端按请求顺序返回响应(仅实现了客户端并发,默认不开启)
- 分块传输编码,产生一块数据,就发送一块,采用"流模式"(stream)取代"缓存模式"(buffer)
- 新增了请求方式 PUT、PATCH、OPTIONS、DELETE
- 支持文件断点续传,RANGE:bytes
- HTTP 2.0 (缺点:同一个域名6个并发连接限制,TCP丢包或延迟队头阻塞-长响应队头阻塞)
- 二进制分帧层 HTTP消息分解互不依赖的帧,可交错发送
- 多路复用
- 头信息压缩
- 服务器推送
- HTTP 3.0
- QUIC
HTTP 断点续传
- 即通过定义请求头 Range 和响应头 content-range,来实现切片传输。
- 标识文件唯一性的方法,通过 MD5、last-modified 、etag,进行校验。或者If-Range头
HTTP 缓存
- 强缓存
- Cache-Control 用于指示代理和 UA 使用何种缓存策略
- no-cache 为本次响应不可直接用于后续请求
- no-store 为禁止缓存
- private为仅 UA 可缓存
- public为大家都可以缓存
- max-age、Expires、Vary 缓存有效性 (Vary: * ,所有头部不做区分。)
- Cache-Control 用于指示代理和 UA 使用何种缓存策略
- 协商缓存 (304)
- etag - 请求头携带If-None-Match
- Last-Modified 请求头携带If-Modified-Since,使用修改时间
- 启发式缓存
- 如果一个可以缓存的请求没有设置Expires和Cache-Control,但是响应头有设置Last-Modified信息,这种情况下浏览器会有一个默认的缓存策略:(Date - Last-Modified)*0.1,这就是启发式缓存。
HTTP 内容协商 同一个 URL 可以提供多份不同的内容 协商方式主要有两类:
- 服务端可用版本列表让客户端选择,300 Multiple Choices
- 服务端根据客户端发送的请求头中某些字段自动发送最合适的版本
由于客户端和服务端之间可能存在一个或多个中间代理,缓存服务最基本的要求是给用户返回正确的文档。
所以 HTTP 协议规定,服务端提供的内容取决于用户代理「常规 Accept 协商字段之外」的请求头字段, 那么响应头中必须包含 Vary 字段,且 Vary 的内容必须包含 User-Agent。同理, 如果服务端同时使用请求头中 User-Agent 和 Cookie 这两个字段来生成内容,那么响应中的 Vary 字段看上去应该是这样的:
Vary: User-Agent, Cookie
浏览器的同源策略 同源定义 协议/主机/端口元组 (IE忽略端口)
跨源网络访问
- 跨源写操作
- 跨源资源嵌入 script、link、img、video、font-face、iframe
- 跨源读操作
如何允许跨源访问?使用 CORS 来允许跨源访问 如何阻止跨源访问?
- 阻止跨源写操作,只要检测请求中的一个不可推测的标记 (CSRF token) 即可
- 阻止资源的跨源读取 需要保证该资源是不可嵌入的
- 阻止跨源嵌入 需要确保你的资源不能通过以上列出的可嵌入资源格式使用
跨源数据存储访问
- 如 localStorage 和 IndexedDB,是以源进行分割
- Cookies 使用不同的源定义方式
跨源资源共享 CORS 是一种基于 HTTP 头的机制,该机制通过允许服务器标示除了它自己以外的其它 origin(域,协议和端口),使得浏览器允许这些 origin 访问加载自己的资源 跨源资源的"预检"请求
优秀文档:
React
优秀文档:
- Typescript
- 基础类型:字符串、数字、布尔值、数组、元组、枚举、any、void、null、undefined、never、object、类型断言
- 高级类型:Required、Partial、Readonly、 Pick<T, K extends keyof T> 、Exclude<T, U>、Extract<T, U>、Omit<T, K extends keyof any>、NonNullable< T >、Record<K extends keyof any, T>
- interface
- 可索引类型
- type
- JavaScript 中精度问题以及解决方案(IEEE 754 的标准)
- 浮点数精度问题
- 大数精度问题
- toFixed 四舍五入结果不准确
- Javascript 的二进制流
- Blob 对象表示一个不可变、原始数据的类文件对象
- File 对象是特殊类型的 Blob
- JavaScript 类型化数组 (将实现拆分为缓冲和视图两部分)
- ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区,不能直接操作 ArrayBuffer 的内容,而是要通过类型数组对象或 DataView 对象来操作
- SharedArrayBuffer 内存使用
- 类型数组视图 Int8Array,Uint32Array,Float64Array 等等
- 数据视图 DataView 是一种底层接口,它提供有可以操作缓冲区中任意数据的读写接口
- 文件操作
- FileReader
- URL.createObjectURL() 内存读取并生成内存URL
- 流操作 API (这是一个实验中的功能)
- ReadableStream 接口呈现了一个可读取的二进制流操作
- WritableStream 接口为将流数据写入目的地(称为 sink)提供了一个标准的抽象。该对象带有内置的背压和队列
// 1.防抖函数
function _debounce(func,m) {
let timer = null
return function () {
const args = arguments;
if(timer) {
clearTimeout(timer);
}
timer = setTimeout(function() {
func.apply(this, args)
}, m)
}
}
function clg(){
console.log(...arguments)
}
clg(1)
clg(2)
const dClg = _debounce(clg, 5)
dClg(3)
dClg(4)
dClg(5)
// 2.斐波那契额数列
function fib1(n) {
console.log('*****fn1',n)
if(n < 0) throw new Error('输入的数字不能小于0');
if (n < 2) {
return n;
}
return fib1(n - 1) + fib1(n - 2);
}
// 存在重复执行问题
fib1(5)
// 优化后
function fib2(n) {
if(n < 0) throw new Error('输入的数字不能小于0');
if (n < 2) return n;
function _fib(n, a, b) {
console.log('*****fn2',n)
if (n === 0) return a;
return _fib(n - 1, b, a + b);
}
return _fib(n, 0, 1);
}
fib2(5)
function* fib3(n) {
if(n < 0) throw new Error('输入的数字不能小于0');
let f0 = 1,
f1 = 1,
count = 0;
while (count < n) {
yield f0;
[f0, f1] = [f1, f0 + f1];
count++;
}
}
const fn = fib3(5)
fn.next()
fn.next()
fn.next()
fn.next()
fn.next()
fn.next()
fn.next()
/**
* 4.题目:实现 add(1)(2)(3)
*
*/
function curry(fn, ...args1) {
const next = function(...args2) {
return curry.call(this, fn,...args1,...args2)
}
next.toString = function(){
return fn(...args1);
}
next.valueOf = function(){
return fn(...args1);
}
return next
}
const addC = curry(function(...args){
return args.reduce((a,b)=>a * b,1)
})
const valueOf = function(fn) {
return +fn
}
const a = valueOf(addC(1)(2)(3))
console.log(a)
/**
* 5.题目:数组转结构化数据
*
*/
const data = [
{
value: "**",
index: 0,
},{
value: "江苏",
index: 1,
parent: 0,
}
,{
value: "北京",
index: 2,
parent: 0,
},{
value: "睢宁",
index: 4,
parent: 3,
}
,{
value: "徐州",
index: 3,
parent: 1,
}
,{
value: "朝阳",
index: 5,
parent: 2,
}
]
function matchNode(root, current){
let isMatch = false;
root.map((v)=>{
if(v.index === current.parent) {
if(!v.children) v.children = [];
v.children.push(current)
isMatch = true;
} else if(v.children) {
isMatch = matchNode(v.children, current) || isMatch
}
})
return isMatch;
}
function matchList(root, list) {
const newList = list.filter((v)=>{
const isMatch = matchNode(root, v);
return !isMatch;
})
return newList
// while(newList.length > 0) {
// console.log(newList.length)
// matchList(root, newList)
// }
}
function tranverse(data) {
const rootList = []
const list = data.filter(v => {
if(typeof v.parent === 'undefined') rootList.push(v)
return typeof v.parent !== 'undefined'
})
try{
let result = list
while(result.length > 0) {
result = matchList(rootList, result)
}
} catch(e){
console.log(e.exception)
}
return rootList
}
const result = tranverse(data)
/**
* 6.题目:Promise.prototype.sequential; 串行并发,节约型、忽略型
*
*/
Promise.sequential = function(arr, options) {
const ALL_SUCCESS_SEQUENTISLL_STATUS = {
IGNORE: 0, // 0 串行请求,忽略错误 忽略型
STOP: 1 //1 串行请求,遇到错误即停止,节约型
}
const list = [];
const {
ALL_SUCCESS_SEQUENTISLL
} = options;
return arr.reduce((pro, current)=>{
return pro.then(
(x)=> {
if(ALL_SUCCESS_SEQUENTISLL === ALL_SUCCESS_SEQUENTISLL_STATUS.IGNORE) {
return current.then((v)=>list.push(v),()=>list.push(null))
}
if(ALL_SUCCESS_SEQUENTISLL === ALL_SUCCESS_SEQUENTISLL_STATUS.STOP) {
return current.then((v)=>list.push(v),()=>Promise.reject())
}
}
)
}, Promise.resolve())
.then(()=>list,()=>list)
}
const list = Promise.sequential([
new Promise((resolve,reject) => resolve(1)),
new Promise((resolve,reject) => resolve(2)),
new Promise((resolve,reject) => reject(3)),
new Promise((resolve,reject) => resolve(4))
],{
ALL_SUCCESS_SEQUENTISLL: 1
}).then( function(result){
console.log('result****',result)
})
/**
* 7.题目:链式调用
*
*/
class LinkResolve {
constructor(func) {
this.func = func;
}
value = null
list= []
}
LinkResolve.prototype.done = function(value){
return this.list.length > 1 ? this.func(...this.list): this.list?.[0]
}
LinkResolve.prototype.then = function(value){
this.list.push(value)
return this
}
const fn = new LinkResolve((...args)=> args.reduce((a,b)=>a + b));
const result = fn.then(1).then(4).then(5).done();
console.log(result)
/**
* 7.题目:Proxy
*
*/
const data = {
value: 0
};
const proxy = new Proxy(data, {
get: function(target, key) {
console.log('get alue')
return target[key]
},
set: function(target, key, value) {
console.log('set alue')
target[key] = value
}
});
console.log(proxy.value)
proxy.value = 5;
console.log(proxy.value)
/**
* 8.题目:文件操作及二进制流
*
*
*/
// * Blob(blobParts[, options])
//(1)对象表示一个不可变、原始数据的类文件对象,它的数据可以按文本或二进制的格式进行读取
//(2)也可以转换成 ReadableStream 来用于数据操作。
const b = new Blob(['XXXXXX'],{type: "text/plain", endings: "transparent"})
const f = new File(['YYYYYY'],'a.k',{type: 'text/plain'})
const buffer = new ArrayBuffer(16)
const view = new Int8Array(buffer)
const dataView = new DataView(buffer)
dataView.getInt16()
// FileReader
const reader = new FileReader();
reader.onload = function(e) {
console.log('reader-',e.target.result)
}
// reader.readAsArrayBuffer(b)
// reader.readAsBinaryString(b) // 已废弃
reader.readAsText(b)
// reader.readAsDataURL(b)
const obj = URL.createObjectURL(f)
console.log(obj)优秀文档:
包括基础建设和软能力建设,狭义上理解是技术架构和技术建设,广义上包括制度、流程、规范、培训、梯队等软能力建设。
在业务快速增长时,技术需要匹配。用户量级、产品复杂度、系统复杂度以及技术更新换代,需要做好平衡。 避免靠加班、使蛮力支持业务,假使业务进行跨越式增长,在技术团队规模上应该是有预见性的解决人员瓶颈问题、系统瓶颈问题、质量瓶颈问题。 因此技术建设此时很重要,帮助业务更好的活在未来 。
技术收益和业务收益并重,核心是提效、体验、稳定性。
在初创阶段:集中在基础技术收益,通过脚手架 、组件库 、CI/CD,在编码阶段、持续集成阶段提高研发效率
在爬坡阶段:集中在业务收益,通过建设业务系统,提升需求吞吐量。
在平台阶段:主要是平衡技术收益和业务收益,建设中台能力,打通关键阻塞点,开启流程化、自动化提高迭代效率。
关键点分析:
- 研发流程
- 需求评审
- 明确参与评审各方,避免二次传达
- 评审结果及异议,确定需求范围
- 人力资源及排期,是否冲突
- 确定需求优先级
- 质量评审
- 测试范围,测试标准
- 数据及物料,依赖外部资源及协调方
- 定量分析,性能数据&问题统计
- 设计评审
- 功能流程设计
- 版本兼容性
- 系统兼容性
- 最终交付物,账号/URL地址/入口
- 交付验收
- 参与交付人员
- 集成版本定版及封版
- 风险管理
- 风险原因
- 风险事件
- 风险损失
- 需求评审
- 开发规范&文档(团队共识)
- Git规范
- 编码规范
- 命名规范
- 埋点规范
- 组件规范
- 性能规范
- 安全规范
- 新人文档
- 技术文档
- 业务文档
- 工程管理
- 项目托管
- 代码托管
- 构建平台
- 镜像托管
- 部署平台
- 健康检查
- 监控日志
- 资产沉淀
- 工具
- 组件
- 可视化系统
- 云生产模式
- 性能体验
- 节点压测
- 全链路压测
- 用户体验
- 首屏体验
- 二次缓存体验
- 安全防控
- 防盗链
- xss跨站脚本攻击,反射型、存储型、DOM型,输入防范、CSP防范
- CSRF
- 点击劫持
- HSTS
- CDN劫持 SRI验证签名
- 内容安全策略(CSP)
- 统计监控
- 用户行为监控
- 性能监控
- 异常监控
- 质量保障
- 自动化测试
- 系统探针
基本概念:
- 屏幕尺寸
- 物理像素(设备像素)显示分辨率的像素单位
- 设备独立像素 通常是操作系统设定的屏幕分辨率的抽象单位,一个设备独立像素由若干个物理像素组成
- 逻辑像素
- CSS 像素
- window.devicePixelRatio 是当前显示设备的物理像素分辨率与 CSS 像素分辨率之比
- 静态布局 网页上的所有元素的尺寸一律使用px作为单位,不考虑浏览器尺寸,一律统一显示。
- 流式布局(Liquid Layout)页面元素的宽度按照屏幕分辨率进行适配调整,但整体布局不变。代表作栅栏系统(网格系统)
- 自适应布局(Adaptive Layout)创建多个静态布局,每个静态布局对应一个屏幕分辨率范围。改变屏幕分辨率可以切换不同的静态局部(页面元素位置发生改变),但在每个静态布局中,页面元素不随窗口大小的调整发生变化
- 响应式布局(Responsive Layout)响应式设计的目标是确保一个页面在所有终端上(各种尺寸的PC、手机、手表、冰箱的Web浏览器等等)都能显示出令人满意的效果,对CSS编写者而言,在实现上不拘泥于具体手法,但通常是糅合了流式布局+弹性布局,再搭配媒体查询技术使用呈现更好的用户体验
- 弹性布局(rem/em布局)改变浏览器宽度,页面所有元素的高宽都等比例缩放
自适应(AWD)和响应式(RWD)
自适应是网页内容根据设备的不同而进行适应,通过检测视口分辨率,来判断当前访问的设备是pc端、平板还是手机,从而请求服务层,返回不同的页面; 自适应是对CDN不友好的,一般CDN的行为在分配时不考虑访问设备
响应式布局是网页的布局针对屏幕大小的尺寸而进行响应,一套界面即可适用于所有尺寸及终端。糅合了流式布局+弹性布局,再搭配媒体查询技术使用
适配方案的设计策略
- 精简并优化导航体系
- 移除不必要的特效
- 合理的字体排版
- 控件排布关系可进行调整
- 优化按钮或可点击元素的位置及热区大小
- 复杂任务向PC转移
优秀文档: