Code and data for Evaluating Explanations for Reading Comprehension with Realistic Counterfactuals.
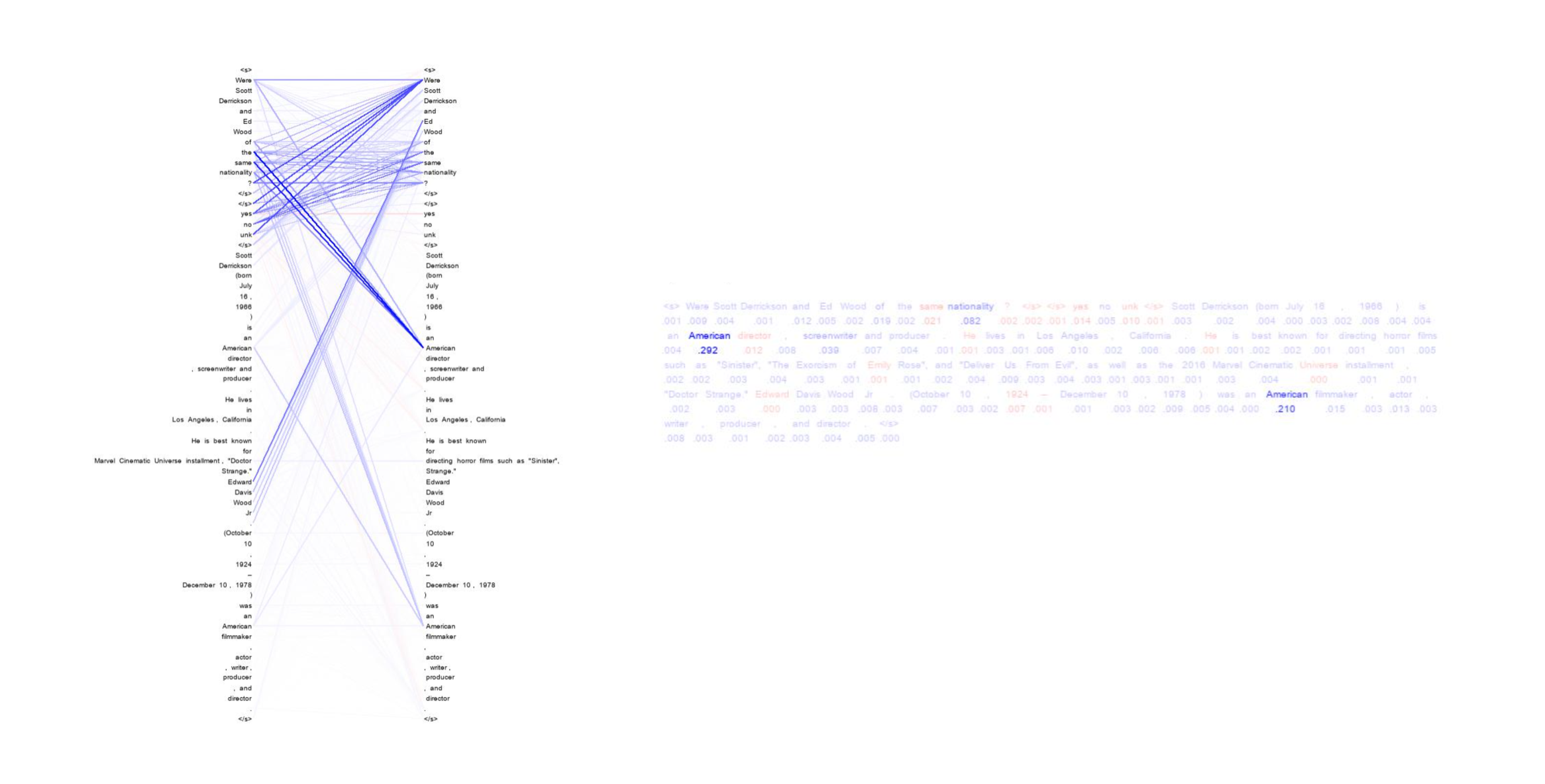
Figure shows the visualization of explanations generated by our techique for a HotpotQA example.
We as well provide implementations/visualizations of several explaination techiques (both classical and recent) for Reading Comprehension, including Lime (Ribeiro et al., 2016), Shap (Lundberg and Lee, 2017), Integrated Gradient (Sundararajan et al., 2017), Archipelago (Tsang et al., 2020), and Attention Attribution (Hao et al., 2021).
- python==3.8
- huggingface-transformers==3.3.1
- pytorch==1.6.0
Please use this version of huggingface-transformers, since the API changes pretty quickly.
Annotations for Counterfactuals
Our annotations for HotpotQA counterfactuals can be found in hotpot_counterfactuals (50 for Bridge Type questions and 50 for Yes-No Type questions).
Our HotpotQA base model is a select-and-answer style model. We first select 2 paragraphs using a document ranker model (a roberta classification model) to construct the context, and then use a RoBERTa QA model to answer the question. Here, we only train the QA part and use provided scores to select paragraphs. Detailed implmentation of the document ranker can be found in NaiveHotpotBaseline.
a. put the HotpotQA in directory datasets/hotpot.
b. run python make_hpqa_dataset.py. This will generate Squad-style dataset files in outputs direcotry. Naming convention follows [split]-[dataset].json, where [dataset] is hpqa. For training split, we use the gold paragraphs to train the model, for dev/bridge-perturb/yesno-perturb split we use paragraphs selected using the ranker provided outputs in misc/dev_ranker_preds.bin. Please refer to this implementation (NaiveHotpotBaseline) for details.
c. run sh run_qa.sh train hpqa [exp_id] to train the roberta model. This will write all outputs to exps/[dataset]-[exp_id]. Please refer to the script for details of hyper-parameters.
d. store the trained model at checkpoints/hpqa_roberta-base. Create this folder and copy the needed files (pytorch_model.bin, config.json, and etc.) there.
e. verify the trained model using sh run_qa.sh eval hpqa dev. It should be able to achieve an exact match of 63% and f1 score o 77.0, comparable to strong single vanilla-bert-based model.
We support the following explanation [method]s. (Experiments DiffMask are implemented in a separate repository).
- lime: Lime (Ribeiro et al., 2016)
- shap: Shap (Lundberg and Lee, 2017)
- tokig: (token-level) Integrated Gradient (Sundararajan et al., 2017)
- arch: Archipelago (Tsang et al., 2020)
- atattr: Attention Attribution (Hao et al., 2021)
- latattr: layerwise attention attribution (Ours)
a. run sh run_interp.sh hpqa [method] run [split] to generate interpretation files for outputs/[split]-hpqa.json using [method]. For the following experiments we only need to generate interpretations files for yesno-perturb and bridge-perturb. E.g, sh run_interp.sh hpqa latattr run yesno-perturb. Note that interaction-based methods can take a long time. The generated interpretation files are bin files stored at interpretations/[method]/[dataset]-[split]-[model] directory, which can be loaded by torch.load.
b. (optional) we support visualizing the interpretations for [tokig, atattr, latattr] by runing sh run_interp.sh hpqa [method] vis [split]. This will generate figures stored at visualizations/[method]/[dataset]-[split]-[model]. (See the example in the beggining.)
a. to evaluate for Yes-No type examples, run
python eval_hotpot_exp/eval_yesno --method [method].
It will make couterfactuals based on the annotation files and construct the simulation task. Make sure you've generated the interpretations file before evaluating.
b. for Bridge type questions, similarly, run
python eval_hotpot_exp/eval_bridge --method [method].