ZhihuSpider是[鸭哥私房菜]网站后台的爬虫,是基于知乎网的爬虫。
{"首页"},
{"今日最热"},
{"本月最热"},
{"话题"},
{"关注"},
{"提问"},
{"回答"},
{"文章"},
{"收藏"},
{"关注的少量专栏"},
{"关注的专栏"},
{"关注的话题"},
{"测试关注者"},
{"测试所有关注者"},
{"发表文章"},
{"今日最热三十条"},
{"发表今日最热三十条文章"},
{"从种子用户开始获取所有用户"},
{"从准备队列中开始获取所有用户"},
{"专用测试"},
{"子话题"},
{"关注错误重试"},
{"更新用户信息"},
{"拉取子话题的精华回答"},
{"更新子话题的精华回答"},
{"精华话题json输出"},
{"风云人物json输出"},
{"统计数据json输出"},
{"登录知乎并获取cookies"},
{"随机发表精华话题到鸭哥推荐"},
{"更新单个用户信息"},
取一个优质种子(粉丝多,关注多)的用户来开始获取其粉丝和关注的核心信息,
存放于redis的准备爬取队列中,然后每次在准备队列中去取特定数量的出来,
先判断是否爬取过,若未爬取就进行爬取个人相关信息,也爬取其粉丝和关注并放入准备爬取队列中去,
爬取完后将特定核心信息存放于已爬取的哈希redis中。
这样的做法,会一层一层的爬取下去,基本上能爬取到所有有质量的,有参与度的用户信息。
获取知乎所有母话题id等信息,再获取所有母话题的子话题id等信息,
根据母子话题id等拼接精华话题url去爬取精华话题前几页最精华的话题,
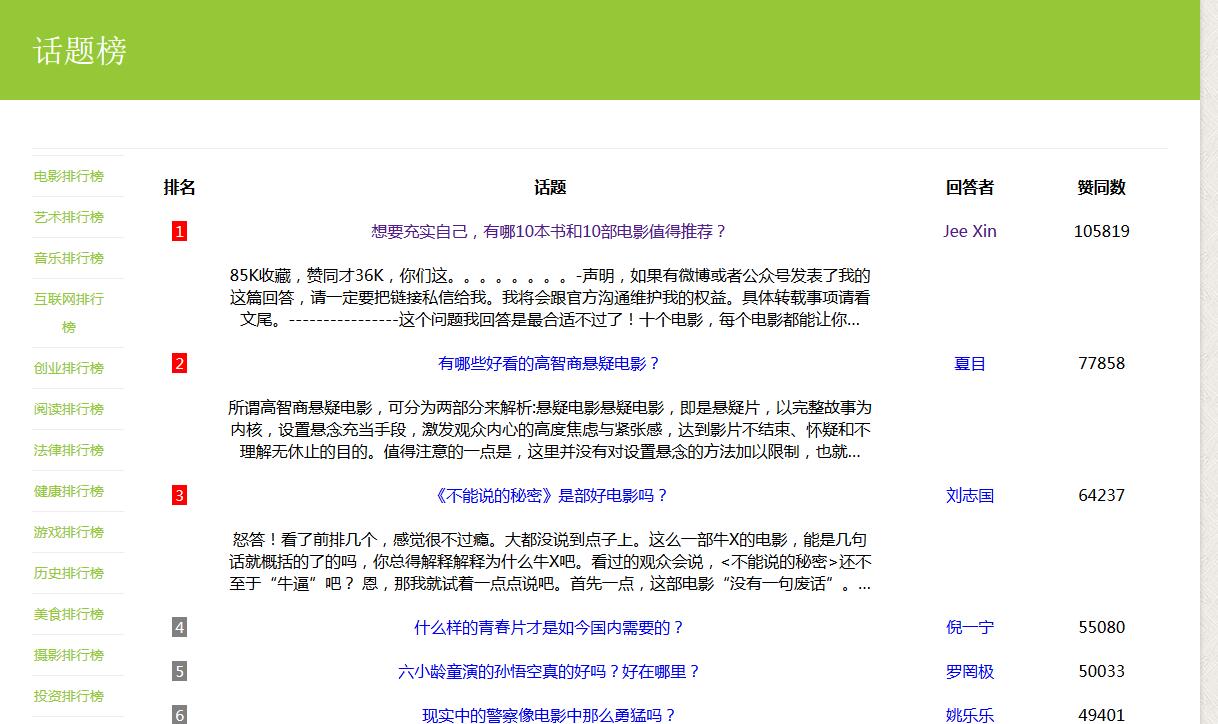
这样的做法,会爬取到所有话题的精华话题,有质量,有学习参考价值的讨论话题。
按照数据库精华话题更新时间排序,取出最久的100项话题,
然后再随机抽取10道精华话题来进行推荐,
这样的做法,会推荐到最精华的话题,然后又是随机的,保证了无人为参与性。
网站前端使用了wordpress框架,能够快速的搭建前端和创建相应数据库表,后台使用crontab定时执行脚本,
脚本执行程序,并将打算发表的数据插入到wordpress的文章相关表格中,这样即可在前端看到更新的文章。
开发语言是c语言,使用curl来爬数据,使用htmlcxx来解析html文件,使用cJson来生成json文件。
使用redis来缓存,使用hiredis来处理redis,数据库使用mysql,前端网站使用Wordpress。
程序依赖的mysql库和爬虫需要的第三方库需要更新为自己系统上的路径,修改Makefile文件中的
BYCO_HTML_DIR=/home/byco/ZhihuSpider/ZhihuSpider/zhihu_spider/html_common
INCLUDE += -I/usr/local/mysql/include/ -I${BYCO_HTML_DIR} -I/usr/local/include/hiredis
LIBS := -L/usr/local/mysql/lib -lmysqlclient -L/usr/local/lib/ -lhiredis
安装redis,mysql,hiredis
db.conf和db_wp.conf连接数据库名密码改为自己的环境下的
redis_op.cpp默认写死redis的ip和端口为"127.0.0.1" ,6379
由于知乎个人主页信息页结构改动,程序中解析个人主页信息代码有bug,抽空再改。
745226897
[鸭哥私房菜网站于20180209永久关闭]
2016年
3月底,开始写爬知乎的程序pull_zhihu的0.1版本,功能有解析今日最热,本月最热,关注,提问,回答,文章,收藏,专栏,话题等等
4月5号,在阿里旗下的万网买域名soonu.cn和在易名**买smimi.net
6号,申请免费的阿里云数据库,云服务器没名额了
7号,免费试用7天腾讯云服务,免费申请亚马逊云一年服务,安装mysql,同步pull_zhihu到亚马逊云上,建立byco用户,创建专用目录byco
8号,解决vi不能输入中文和中文会乱码问题,解决pull_zhihu无法调用libmysqlclient.so.20的问题,开始设计pull_zhihu的相关表格,mysql创建byco用户并赋予增删查改权限,创建cookies表,用户信息表,用户哈希表,用户参与情况表,话题表,子话题表等
9号,设置系统的编码格式固定为en_US.UTF-8,设置mysql的zhihu库固定为utf8,pull_zhihu建立与表字段一一对应的结构体,建立cpp文件写mysql的增删查改函数。
19号,安装php,mysql建立wordpress数据库,试验亚马逊云建立美国站点
20号,安装apache,mysql建立新用户user_word,针对wordpress库使用,亚马逊云安全组入站开放80和3389端口供apache和wordpress使用,安装php5-mysql
21号,安装好php,从别的机器拷贝了libphp5.so,libnss3.so,libnssutil3.so,libssl.so等等64位到/usr/lib64/,在apache的httpd.conf加入支持php模板,建立好wordpress第一版和表格,解决无法登录wordpress后台问题,wordpress的user_word用户授予创建,删除表格权限。wordpress暂定为“鸭哥私房菜”。
22号,设置wordpress主题,安装curl,安装php的curl扩展,安装m4,安装autoconf,php.ini设置扩展curl.so,重启apache
24号,修改页面为留言板功能
25号,修改网站的布局,菜单,留言板等等
26号,了解wordpress自动创建的表格的意思
27号,程序帮助说明,插入wp_posts文章表格代码,
28号,发表文章到wordpress上,以一个文章内多个话题连接,答题,链接的格式发表
5月3号,安装redis,配置redis,测试redis
5号,安装hiredis,更新系统动态库配置,pull_zhihu中增加redis_op的cpp和h文件,makefile连接相应的库文件和目录,设计获取所有用户流程思路
6号,摘取csdn的一段封装的hiredis的c++代码,调用并测试,获取特定种子用户的粉丝唯一的data-id。
7号,获取种子用户的粉丝信息,分页拉取,获取种子用户的粉丝量和关注量和data-id。手贱删除了volum导致亚马逊美国云实例启动不了,缺少了/dev/sda1/,也没有做快照备份,导致无法恢复,只能重新搭建服务器了,workpress和mysql数据库数据都要重新弄
12号,开启亚马逊东京云,建立新的实例
13号,同步pull_zhihu到东京云,修改系统编码为en_US.UTF-8,系统配置为zh_CN.GB2312,和使得vi支持中文输入,建立byco组,byco用户,创建专用目录byco,
16号,安装apr,pcre,apr-util,libxml2,mysql,php,apache,wordpress安装包,建立了wordpress库,word用户等等
17号,自定义wordpress,设置菜单,建立鸭哥热点,鸭哥推荐,鸭哥问答,关于这里,常见问题,留言板等,安装插件wp-touch,wp-super-cache,安装i-excel主题,设置访问ip地址就可以直接访问wordpress,设置站点url和wordpress地址,上传logo,创建分类目录,创建关于这里等页面,设置留言板模板,使php扩展mysql等等
18号,安装redis,配置redis,测试redis
19号,安装hiredis,创建爬知乎数据库创表语句,修改连接mysql语句地址,使之加载libmysqlclient.so.20库
23号,写插入t_topics话题和t_sub_topic子话题的sql语句。
24号,select所有话题的父id的sql语句,写获取所有父话题下的1000个以内的子话题的名字,url,id的函数,寻找子话题的url,测试curl子话题url。
25号,修改mysql的编码为utf8mb4,使之支持utf8四个字节和emoji表情等,修改my.cnf的编码为utf8mb4,测试中文是否能写入数据库
6月1号,发布今日热点30篇到wp上,爬取15873条子话题的名字和url到数据库中去,开始爬种子用户的关注和粉丝
14号,根据更新时间久的来更新个人信息数据和个人参与信息数据和userhash数据表数据
15号,测试
16号,创建精华话题表格
17号,拉取子话题精华话题数据,插入精华话题数据
18号,更新子话题精华话题表格的数据函数实现
21号,更新精华话题少量bug修改和优化,当子话题队列redis的key或没有数据时,取数据库子话题表传入插入,并每次取20条数据进行精华话题数据的更新。
22号,过滤从母话题去获取子话题中的子话题名含有特殊字符,解决含有特殊字符无法插入的错误bug
24号,增加取精华话题top5,并使用cJson构建json格式,并写入到/json/xxx.json文件中,使得访问特定url可以得到json数据
25号,写toprank.html,左边为链接,右边为iframe
26号,写commontoprank.html表格
27号,写根据json数据来建立表格的js文件
7月
1号,获取所有母话题id对应的精华话题top50的json数据
2号,在精华话题排行榜表格中增加母话题id字段
4号,根据精华话题排行榜母话题来分各大排行榜来获取json数据
5号,寻找html传参到jsp文件的方法,并测试(最终发现apache不支持jsp解析,寻找其他方法解决)
6号,完成toprank.html传参数key到commontoprank.php中去,由get_json_data.js模块去调用相关的json数据,在鸭哥私房菜的排行榜页面增加相关排行榜。获取精华话题top50数据用unsigned来排序,并发现需要解决iframe不兼容各大浏览器的问题
7号,撰写网站中的关于这里,常见问题的内容并发布
8号,获取发表今日热点文章时,同步更新今日热点文章所属目录为鸭哥热点4;修改今日热点没有玩家连接和名字时即为知乎用户或匿名用户时的bug处理;
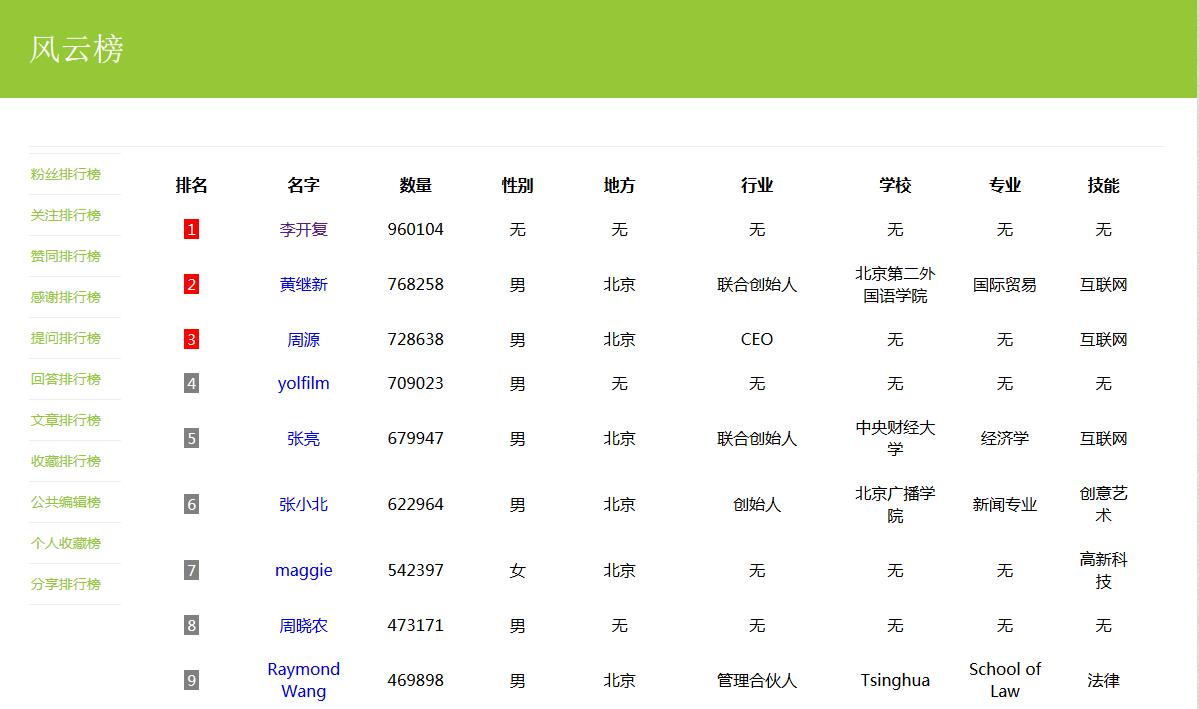
11号,完成五十大风云人物(按粉丝数,按回答问题数量,按点赞数,按感谢数,按文章数,按关注数,按分享数等等制作各大排行榜)功能
12号,完成iframe在火狐和ie等浏览器中兼容展示的问题,解决留言板页面不能留言bug,取消留言板出现前后页面链接,增加留言提示内容,修改留言评论总数汇总提示,
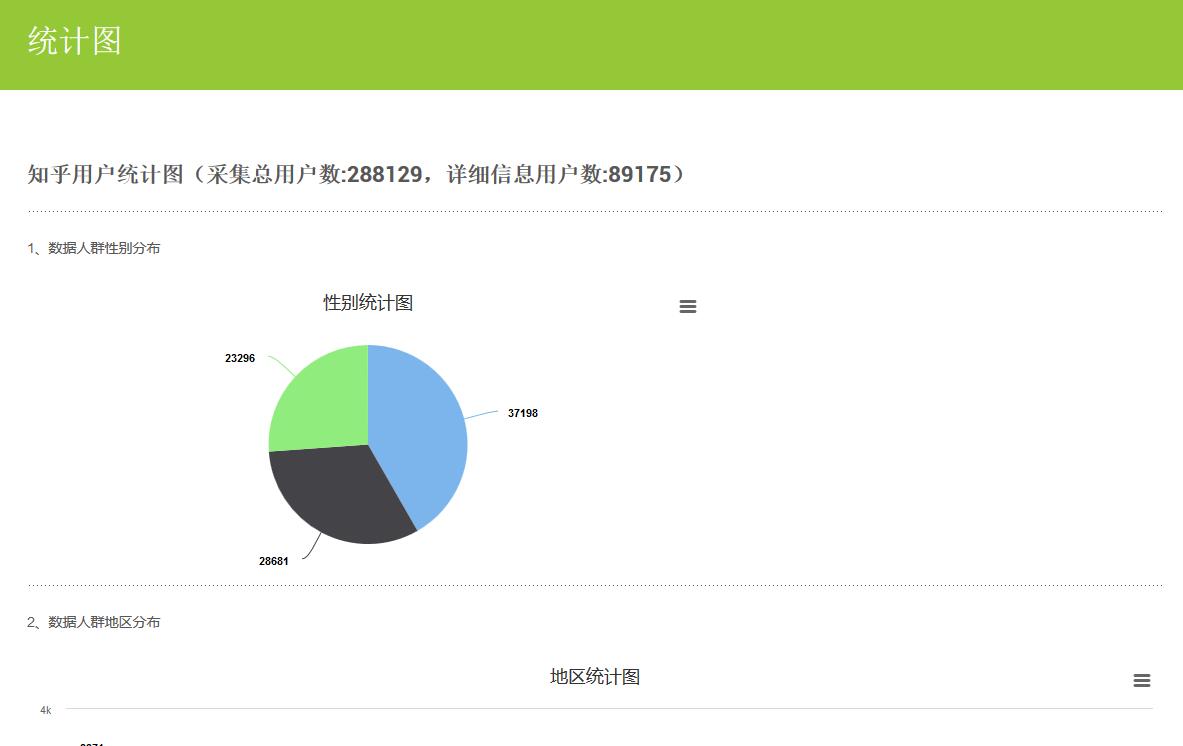
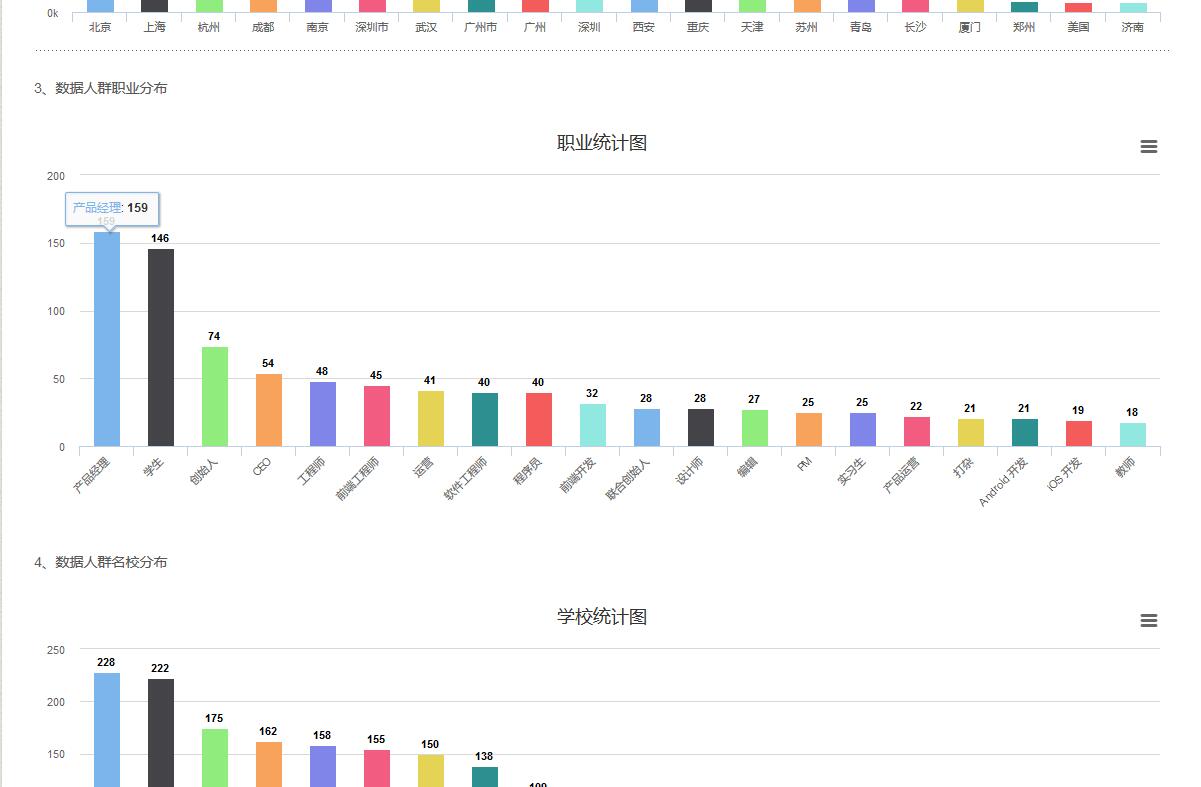
13号,解决评论用户头像被屏蔽导致无法显示的问题,完成了分布统计图的功能并加入到菜单中为“统计图”,解决菜单目录中会出现Category Archives字样。
14号,测试curl获取登录知乎后返回的cookies的方法
15号,修改数据库表表格cookies的字段,并插入账号和密码。完成使用账号和密码登录知乎,并返回cookies保存的功能。实现保存的cookies来完成爬取数据的功能。
16号,将之前购买的smimi.net域名解析到亚马逊云ip上。使之可以通过www.smimi.net 来登录鸭哥私房菜,并同步修改文章地址和js文件中之前写的获取ip地址为域名地址。
19号,规划定时的crontab
20号,开始crontab,开始跑程序爬数据,更新数据,页面表格和div进行百分比显示,以便兼容手机访问时数据显示不完全的问题。注册七牛云
21号,实现鸭哥推荐(随机最新更新的100条精华话题问答,然后再从中随机10条来推荐),去除鸭哥问答菜单,删除旧文章,
22号,注册友盟账号,并添加www.smimi.net 域名,并将生成的cnzz脚本语句添加到主题中的底部.php中,实现统计访问人数,次数,ip等等数据,修改系统时间
8月
16号,增加内存监控脚本,增加空间不足检查脚本,并加入crontab定时检测。修复粉丝和关注页面由于知乎页面结构变化而导致无法获取信息的bug。
17号,页尾增加知乎和原作者版权所有,并和原来的格局规划,cnzz增加查看密码,关于这里内容修改和展示优化
18号,在线制作了鸭哥私房菜的logo,网站去除搜索框和搜索功能,网站上线推广文书写
19号,修改网站联系的qq号,增加了首页和赞助页面和菜单项,增加官方qq和修改qq空间内容,定时检测内存脚本改为每一分钟检测,优化关于这里和常见问题页面的内容,测试点击网站各功能
20号,网站上线,推广发布网站。宣传网站
22号,截图pc端的在qq和微信中宣传
23号,修改首页第四幅图的话,监控内存脚本暂时去除重启apache功能
24号,吃
25号,喝
26号,玩
2017年
没管过,没打开过!!!
2018年
2月9号,代码sql等备份,删除亚马逊云AWS上的鸭哥私房菜实例,并关闭和注销了账号,www.smimi.net 关闭域名解析,并上架易名**进行域名售卖,将知乎、微博,github,鸭哥公众号相关的域名跳转进行修改。
再见了~鸭哥私房菜