
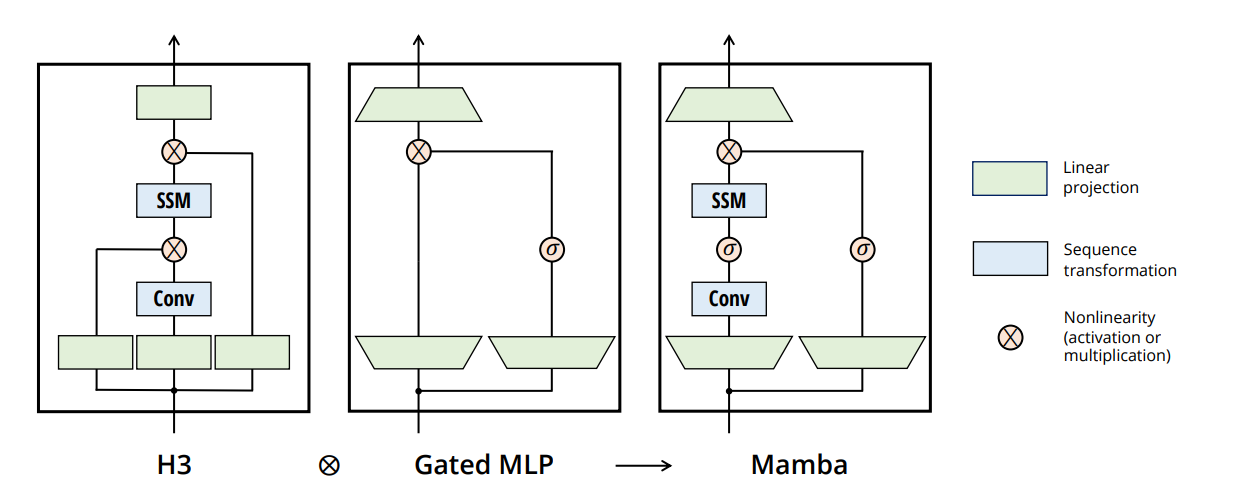
This is a PyTorch project that implements a minimalistic Mamba architecture described here. The Mamba model is a sequence-to-sequence model, suitable for various tasks, from signal processing, NLP, regression etc. It is also tested on TinySheakspeare dataset.
For more details on the transformer architecture, refer to the original paper: Mamba: Linear-Time Sequence Modeling with Selective State Spaces.
To get started with Transformer Plain, follow these steps:
-
Clone the repository:
git clone https://github.com/paulilioaica/Mamba-Pytorch cd Mamba-Pytorch/src/ -
Install the required dependencies:
pip install -r requirements.txt
-
Dataset: The Mamba project uses the TinySheakspeare dataset as a self-supervised task. This dataset consists of a collection of Shakespeare plays, which can be used for language modeling and other natural language processing tasks. The task is character-level prediction.
It automatically fetches it, but if by any case it fails, find it here
-
Configure the training parameters: Adjust the hyperparameters by passing your own arguments.
-
Train the model: Run the training script to start the self-supervised prediction training loop.
-
Evaluate the model: Use the trained model to make to generate text.
python main.py --batch_size 64 --sequence_len 30 --learning_rate 0.001 --num_epochs 10 --num_layers 3 --hidden_size 64 --rank 3 --state_size 10 --kernel_size 3 --device cuda
Epoch 1 Loss: 1.64884087392145
Epoch 2 Loss: 1.429981441432258
Epoch 3 Loss: 1.3725837546935196
Epoch 4 Loss: 1.334091197993747
Epoch 5 Loss: 1.299267634493379
Epoch 6 Loss: 1.2675694288666715
Epoch 7 Loss: 1.234475031751128
Epoch 8 Loss: 1.1965902572644944
Epoch 9 Loss: 1.1606470010534595
Epoch 10 Loss: 1.1184957633723098
Generated text after 10 epochs
To be or not to be so rid o' the state, of my son's face.
LUCIO:
Why, then, my lord, my lord.
LEONTES:
Why stay we
This project is licensed under the MIT License.