Dentro de nuestro proyecto de ML es necesario considerar tres pasos importantes y las herramientas que nos ayuden a soportar y tener un flujo optimo de datos y de modelo estas son:
- Ingesta de datos
- Manejo de datos
- Entrenamiento de modelo
- Evaluación de modelo
- Empaquetado y serialización de modelo
- Servicio de modelo
- Monitoreo del rendimiento del modelo
El modelo que vamos a proponer es una arquitectura sencilla que cumpla con los estandares para un modelo aceptable , que cumpla los pasos que vimos anteriormente pero que a su vez facil incorporar nuevas herramientas y procesos
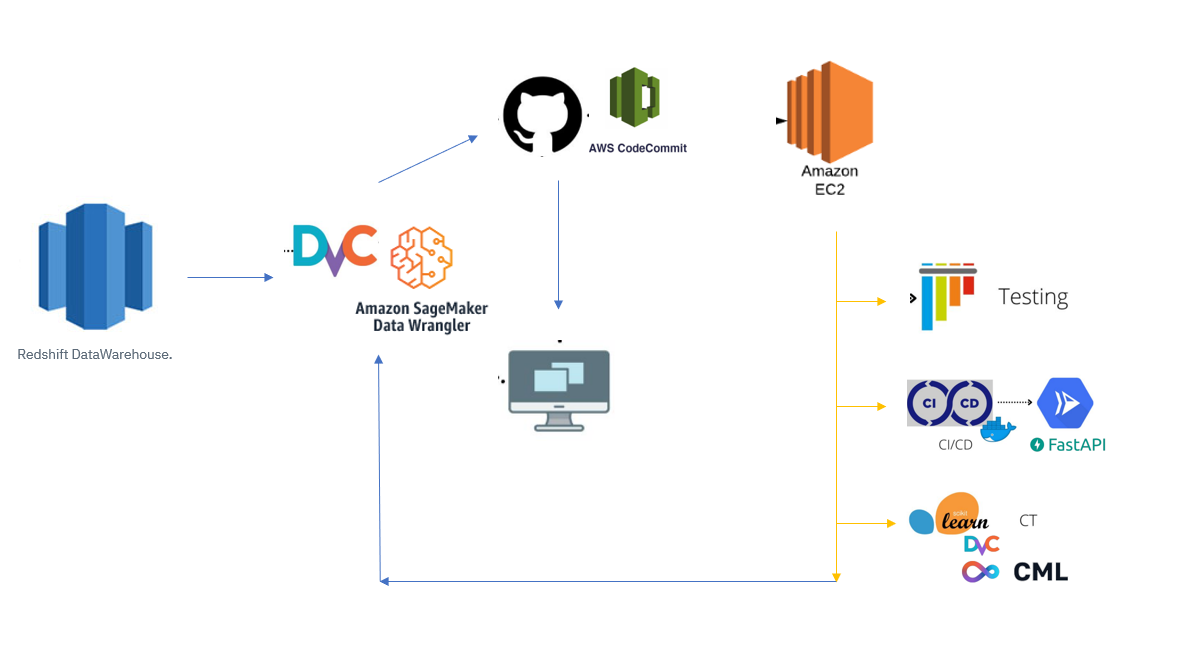
Iniciamos con una base de datos en amazon donde nos serviremos continumente , para hacer nuevas ingestas y versionamientos a traves de data version control o en este caso un producto de amazon que cumpla las caracteristicas. Luego llevar los codigos de un modelo a un repositorio que nos permita hacer un seguimiento a los cambios se podria utilizar el popular git o alguna privado de amazon como codecommit que cumpla las mismas caracteristicas. Luego nos codigo es necesario volcarlos la maquina que realizara el procesamiento para eso tenemos multiples opciones una es configurar un servicios en instancia EC2 que me servivirá para ejecutar todas las activaciones de procesos estas se podrian trabajar a travez de gighub action o traves de diversos pipeline. Para esto se pueden utilizar muchas herramientas es necesario revisar para cada caso, si se necesita una en particular.
Lo importante es que de aqui se cobija la integracion o ejecucion de tres servicios o flujos
- El Testing
- La integracion continua y el despliegue , podria ser en un contenedor para activar un microservicio en FASTAPI
- Entrenamiento continuo que va a utilizar las librerias y modelos en python revisar el performance con continuos machine learning las metricas de nuestro modelo
Existen herramientas como

Machine Learning flow que nos ayudan a optimizar y tener cada parte del proceso de una formas mas facil, facilitando muchos de los pipelines, se podria acudir a una instancia y permitir una orquestacion mas facil mediante usos de opensource.
Adicionalmente se recomienda
- Implementación de un sistema escalable para manejar las solicitudes de inferencia en producción.
- Uso de herramientas como Kubernetes o servicios en la nube para escalar automáticamente la infraestructura según la demanda.
- Diseño de arquitecturas de inferencia distribuidas para manejar cargas de trabajo pesadas y mejorar el rendimiento.
Ya que tenemos la libertad de usar herramientas privadas podriamos tambien usar Amazon SageMaker o Azure Machine Learning que ofrecen toda una experiencia de principio a fin en el modelado pero a un mayor costo, algunas he tenido la oportunidad de probar como databrick o azure machine learning pero los mas importante es saber la finalidad del modelo y de esta forma planear una arquitectura ideal, sin descuidar nunca los elementos clave para el desarrollo.
No genero un codigo de ejemplo debido a que creo que es necesario conocer un caso especifico, aun asi existen muchos codigos base en herramientas como Mlflow para iniciar un trabajo y hacer un despliegue casi inmediato de nuestros modelos.