전체적인 진행과정은 블로그에서 확인할 수 있습니다: https://pearlluck.tistory.com/notice/572
완성된 카카오톡 음악추천챗봇입니다, 카카오톡 친구추가를 하여 확인할 수 있습니다.: https://pf.kakao.com/_LKGCs
Spotify(음원서비스)API의 아티스트와 음원데이터를 이용하여
아티스트를 입력하면 유사한 아티스트의 노래를 추천해주는 Serverelss기반 카카오톡 챗봇 개발
2021.05.30 ~ 20201.06.30
- Language : Python 3.6
- DB : AWS RDS(MySQL), AWS DynamoDB, AWS S3
- Infra : AWS Lambda, API Gateway, AWS Athena
- API : 음악데이터(Spotify API), 카카오톡 챗봇(Kakao i)
데이터 수집부터 저장과 처리 그리고 데이터분석까지 AWS를 사용하여 데이터파이프라인 개발
- Python을 이용하여 Spotify API를 통해 아티스트의 데이터수집
- 데이터 전처리 후 AWS RDS 및 AWS DynamoDB에 데이터저장
- raw 데이터와 Spotify의 음악메타데이터를 AWS S3에 저장하여 DataLake 구현
- AWS Athena를 통해 유사도를 계산하고, Mysql에 저장하여 DataMart로 활용
- 입력한 아티스트의 정보 뿐만 아니라 유사한 음악을 추천할 수 있는 Serverless 카카오톡 챗봇 서비스 개발
AWS API Gateway와 AWS Lambda기반의 Serverless 구조

- 사용자가 챗봇에게 아티스트를 입력하면 API Gateway가 트리거가 되어 lambda 함수가 호출
- 챗봇이 API Gateway를 거쳐 POST 방식으로 보낸 request 메세지를 lambda가 받아 처리한다.
- 사용자의 Request가 있을때만 동작하여 저렴한 비용으로 서비스 운영가능
- 별도의 서버를 관리할 필요 없이 lambda에 코드작성 및 배포
S3,EMR,Athena 등을 활용한 AWS기반의 데이터파이프라인

- rawdata인 SpotifyAPI와 RDS, DynamoDB에 흩어져 저장되어 있던 데이터를 분산스토리지인 S3로 모아 DataLake 구현
- 대화형쿼리엔진인 Athena를 사용하여 쿼리수행 후 유사도결과를 별도로 저장하여 데이터마트 구현
- 빅데이터 플랫폼인 EMR 클러스터를 구성하여 S3에 저장된 데이터를 Hadoop 및 Spark로 분석, Zeppelin에서 시각화
Spotify API를 기반으로 데이터를 수집하고, 저장하여 카카오톡 메세지 형태로 응답해주는 로직처리


- 기존 아티스트를 받았을 경우, DynamoDB와 RDS에서 데이터를 조회하여 카카오톡 메세지 형태로 응답
- 신규 아티스트를 받았을 경우, Spotify API를 통해 관련 데이터 수집 및 저장
- 예를 들어,아티스트 데이터(artists) AWS RDS, 아티스트의 음악정보 데이터(top_track) AWS DynamoDB
raw data를 parquet 포맷으로 압축하여 S3에 저장하는 로직처리

- AWS RDS에 저장된 artist_id 로 Spotify API를 통해 raw data 수집
- S3에 저장하기 위해 계층형 구조의 raw data를 flat하게 변형
- 컬럼기반 포맷(parquet)으로 압축된 데이터를 S3 저장 → DataLake 구현
Athena 쿼리수행 및 아티스트 간 유사도를 계산하여 RDS에 저장하는 로직처리

- S3에 저장된 데이터를 대상으로 AWS Athena 쿼리를 수행하여 구조화된 데이터로 변환
- 아티스트별 평균 음악메타 데이터를 Euclidean Distance 알고리즘 기반으로 유사도 계산
- 아티스트간의 거리가 가까운 (유사도가 높은) 아티스트를 RDS에 저장 → DataMart 구성
- 신규 아티스트 입력결과 : 데이터처리 및 분석이 이뤄지지 않아 입력한 아티스트와 노래정보 전달
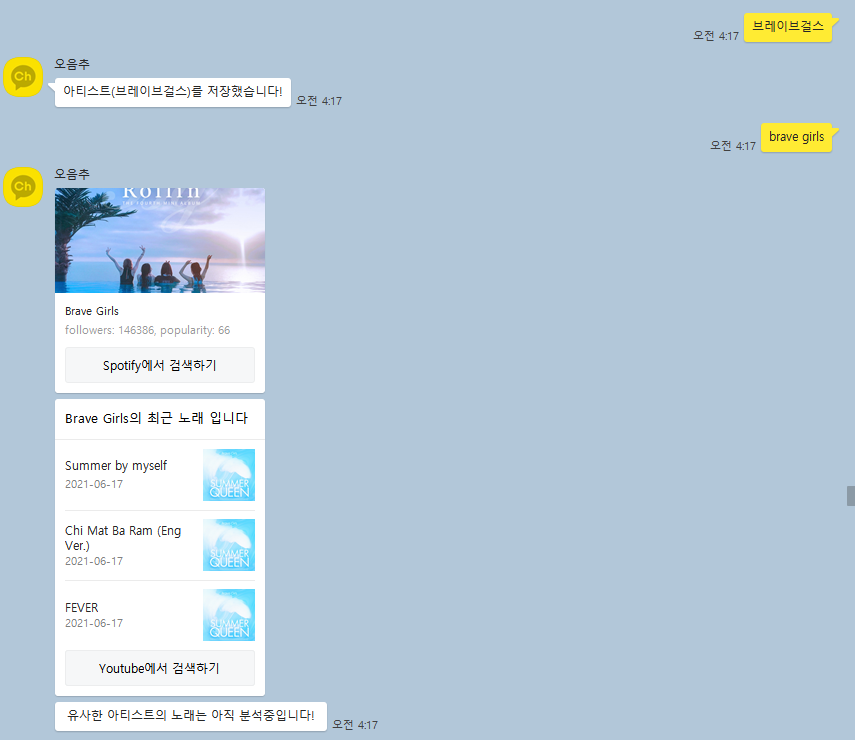
- 기존 아티스트 입력결과 : 데이터처리 및 분석결과 (입력한 아티스트와 가장 유사한 아티스트의 노래정보) 전달
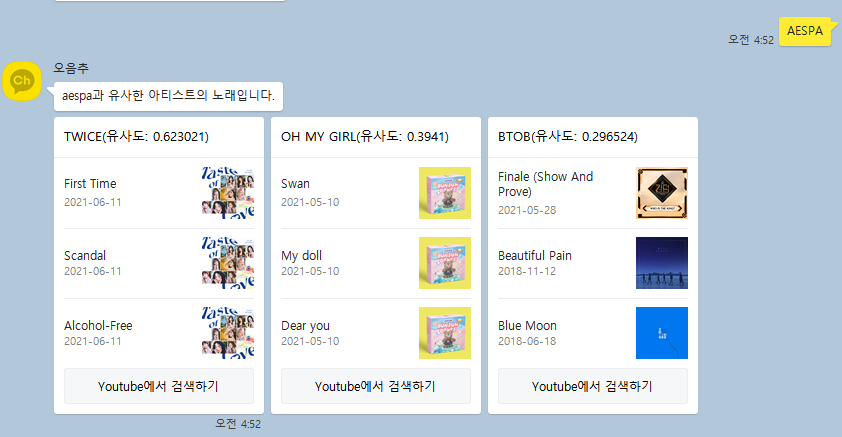
- S3,Athena 스트립트 처리 자동화를 위한 crontab 또는 airflow 적용
- 유사도 정확성을 높이기 위한 알고리즘 변경고려
- EMR 클러스터로 쉽게 구축한 빅데이터 분석환경을 Docker기반으로도 구축해보기