Clarification of binary and multi class cross entropy interface in pytorch
torch.nn.functional.binary_cross_entropy takes logistic sigmoid values as inputs
torch.nn.functional.binary_cross_entropy_with_logits takes logits as inputs
torch.nn.functional.cross_entropy takes logits as inputs (performs log_softmax internally)
torch.nn.functional.nll_loss is like cross_entropy but takes log-probabilities (log-softmax) values as inputs
Week 8
Self-information: Number of bits required to convey an event x, given by -log(p(x)).
Self-entropy: Average uncertainity in whole probability distribution, given by E_{x~p(x)}[-log(p(x))]
KL divergence: Measures distance between two distribution P and Q over same random variable X, given by E_{x~P}[log(P(x)/Q(x))]
KL divergence provides extra bits of info sampled from P but using the codes designed to encode info sampled from Q.
The characteriscs of forward KL (zero spreading) and backward KL (zero inducing) is described here
(Advanced) Density ratio estimation in KL divergence in tensorflow here
Cross-entropy: Uncertainity in a distribution Q averaged over samples from another (cross) distribution P, given by E_{x~P}[-log(Q(x))].
Cross entropy is also equal to Self-entropy of P and KL divergence between P and Q. So, minimizing Cross entropy with respect to Q minimizes forward KL divergence between P and Q.
Empirical distribution: Since real distribution is not available and we only get the data points sampled from real distribution, empirical distribution replaces the real distribution by putting equal probabilities on each data samples (with IID assumption).
So cross entropy minimization often means minimizing E_{x~P_hat}[-log(Q(x))] where P_hat(x_i) = 1/N (N is the number of samples).
Point estimators: To estimate the parameters, a point estimator is a function of random variables (signifying the data observations). For example, in neural networks, the point estimator funtion is gradient calculation plus addition.
Bias: It is distance of estimated parameter from real parameters (which is unknown), given by E[theta] - real_theta.
Variance: It represents the variation in parameters for small perturbation in observed data (and hence point estimation).
When pytorch? (cheap, easy code, not fast), when tensorflow? (production level code, very fast, established infra)
Start with pytorch, once proof-of-concept is ready, migrate code to tensorflow.
Structure code: refer framework test directory, ready to do a lot of hyper-parameter search (but not blindly).
Debugging through visualization is very very very important. Eg. distribution plot of floats out of a layer, weights.
Week 11
Vector space and sub-spaces. Sub-spaces should have zero element and should follow clouser property.
Generating set is a set of vectors that spans the vector space. Basis of a vector space are linearly independent vector set that spans the vector space.
Rank is the number of linearly independent rows or linearly independent columns.
Linear mapping (and its properties such as homo-morphism) and linear transformation matrix.
Kernels (with relation to matrix transformation) are all vectors that are zero vectors in original vector space.
Norms and inner-product maps V or VXV to R, where V is the vector space. They measure the length and distance.
Orthonormal/orthogonal basis and orthogonal projection. Gram Smidt process to find such basis.
Week 12
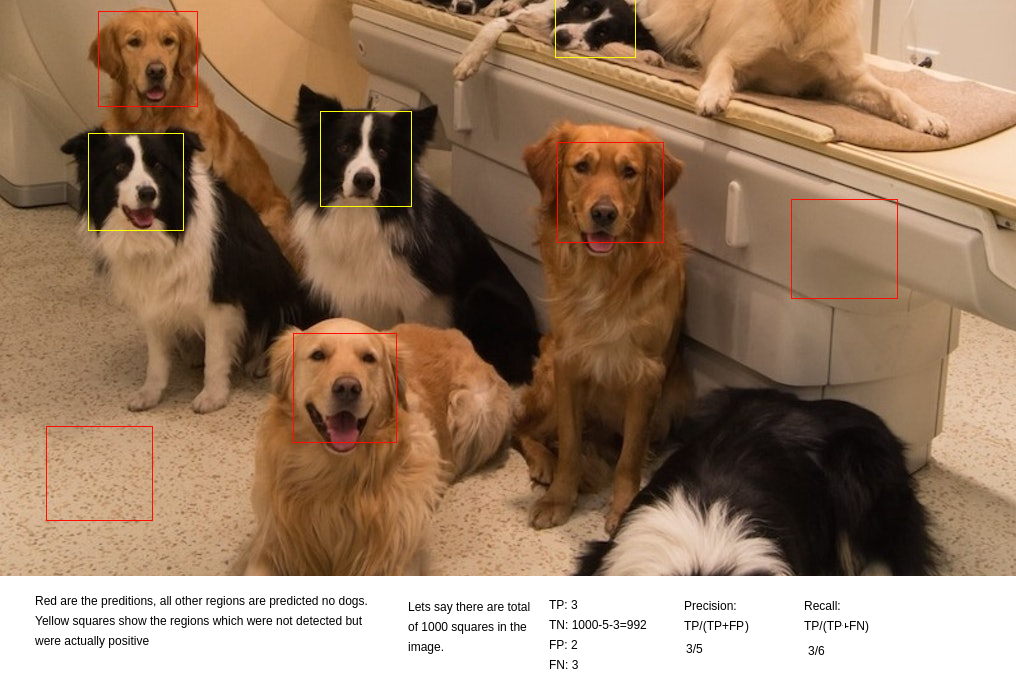
True positive: hit, Red squres with dog face.
False negative: miss, Yelow squares with dog face.
False positive: Low skill model, Req squares without dog face.
True negative: All regions other red and yellow squares.
Precision: Out of positive predictions, how many were actually correct.
Recall: Out of all actual postitive labels, how many we got.
AUC curve measure the models skill for balanced data as we vary the probability threshold.
Precision-recall curve summarizes the model's skill for un-balanced data where positive examples are the real concern.