An spatiotemproal modeling for video summarization by key frames extraction
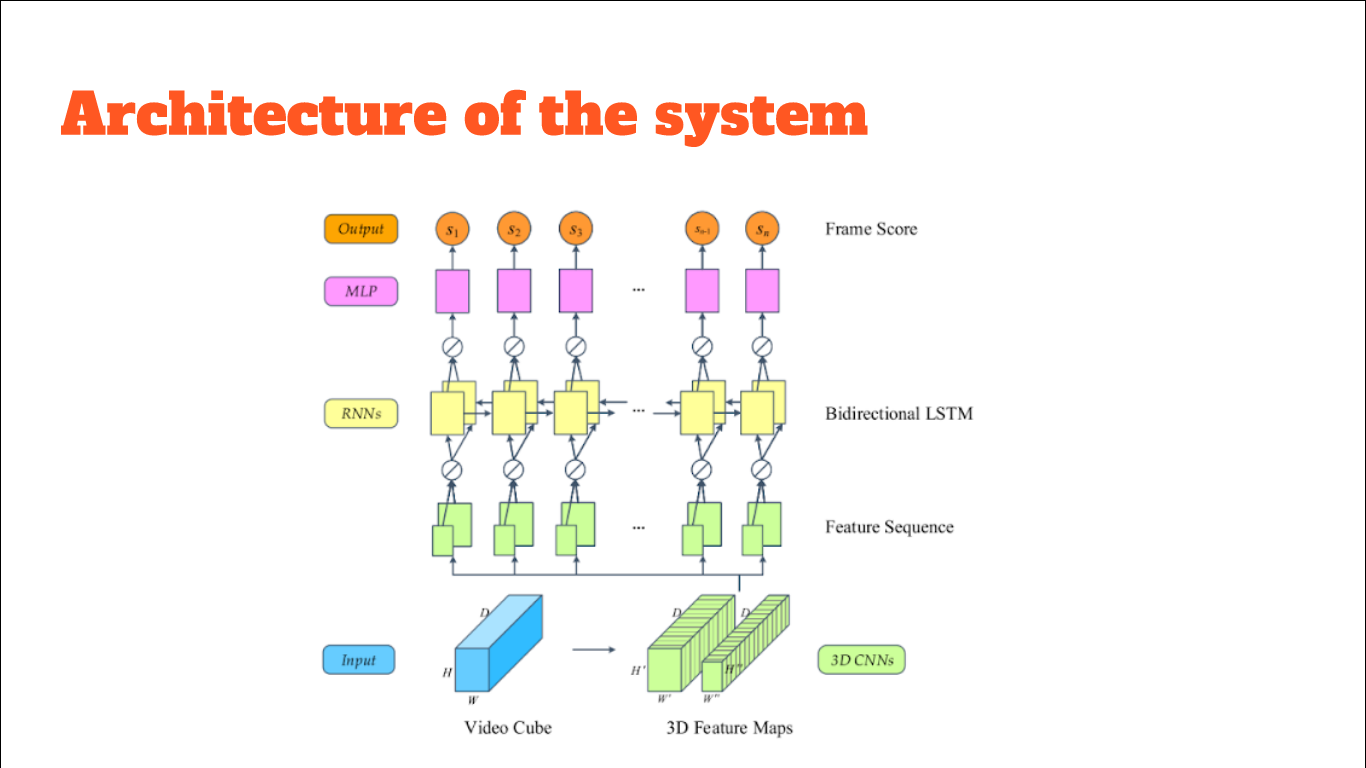
In hospitals, medical videos are recorded which are huge and consume lot of space. These videos are generally stored for diagnosis, treatment or research purposes. But due to increasing number of videos it becomes difficult to manage them. A video contains only a few frames which actually contains valid and useful information. Hence in order to reduce the redundant frames, Video Summarization is needed. Video summarization can be done by extracting key frames or by shot segmentation. Summarization of these medical videos helps to save space and time. In this work, deep learning neural networks such as Convolutional Neural network (CNN) and Recurrent Neural network (RNN) are used to extract the spatiotemporal features of the videos. CNNs take the video frames as input and the features of video are generated as output. Bidirectional long short term memory (LSTM), a special type of RNN, is used to process the sequential structure of video. Multilayer Perceptron is used to generate importance scores or frame scores ranging from 0 to 1 based on which key frames are extracted.
The dataset of the endoscopy medical videos is hard to get , so for now we annotated the manually the existing endoscopy videos,butfor different video summarization related problem this repository will work well,
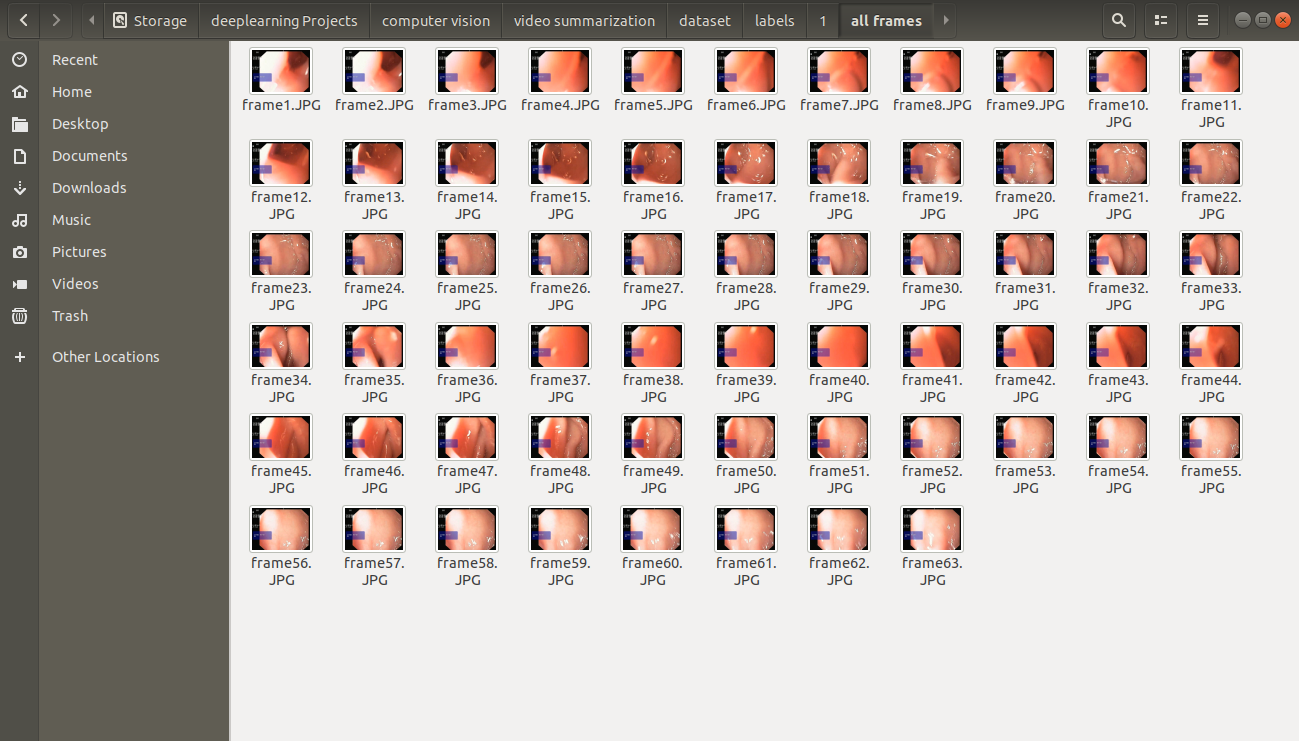
Here is the sample data details Orignal video's frames after extracting
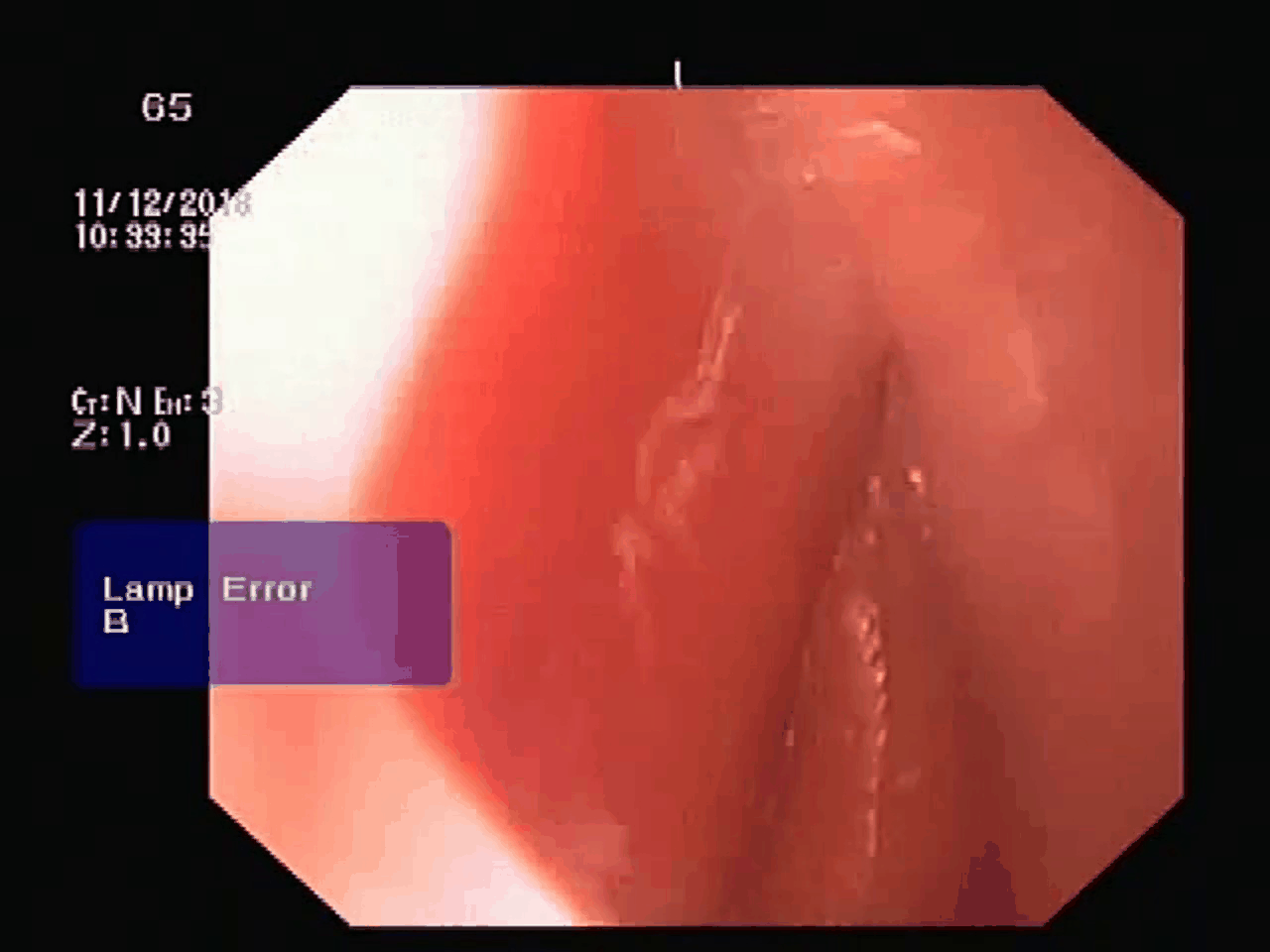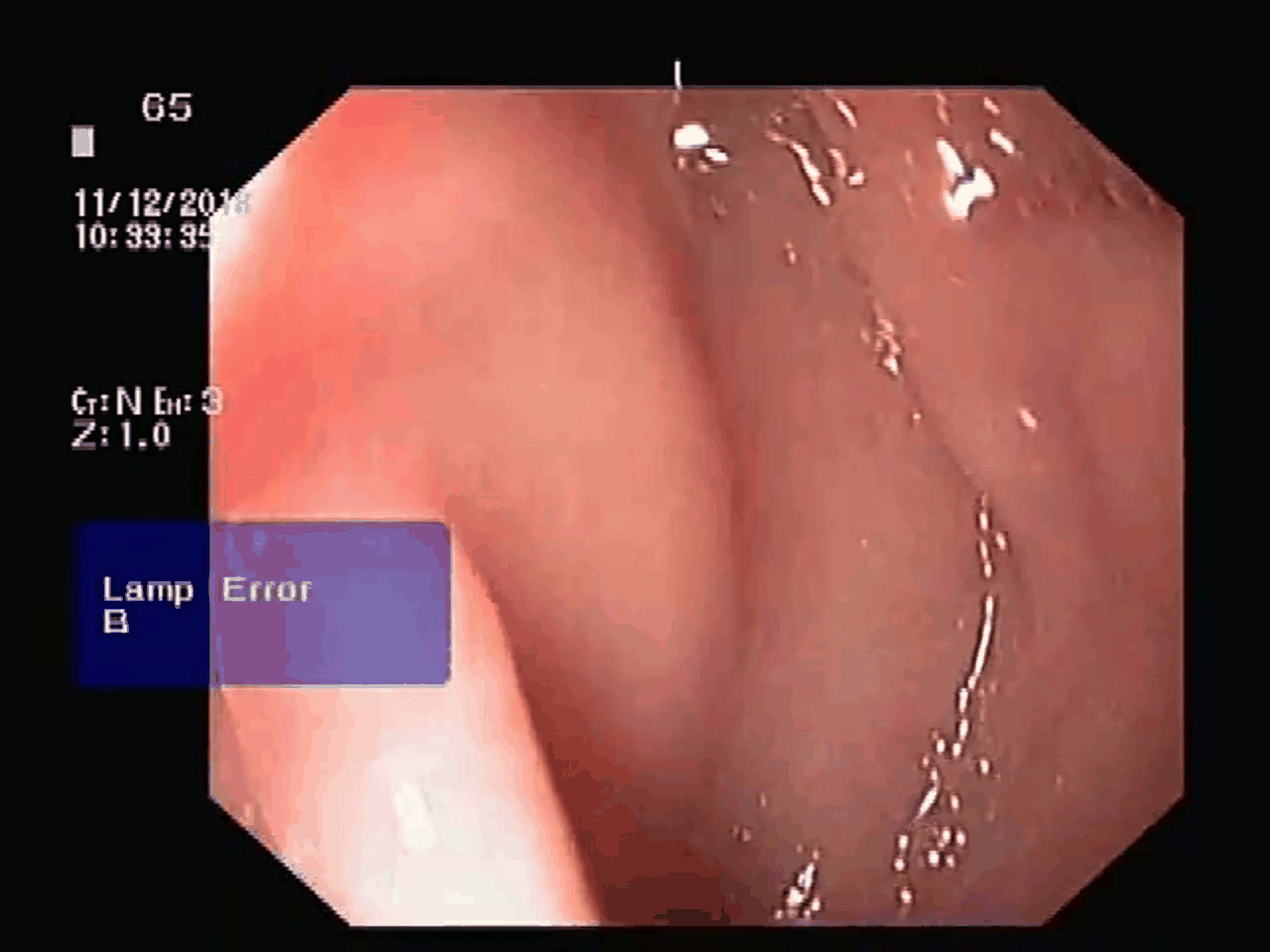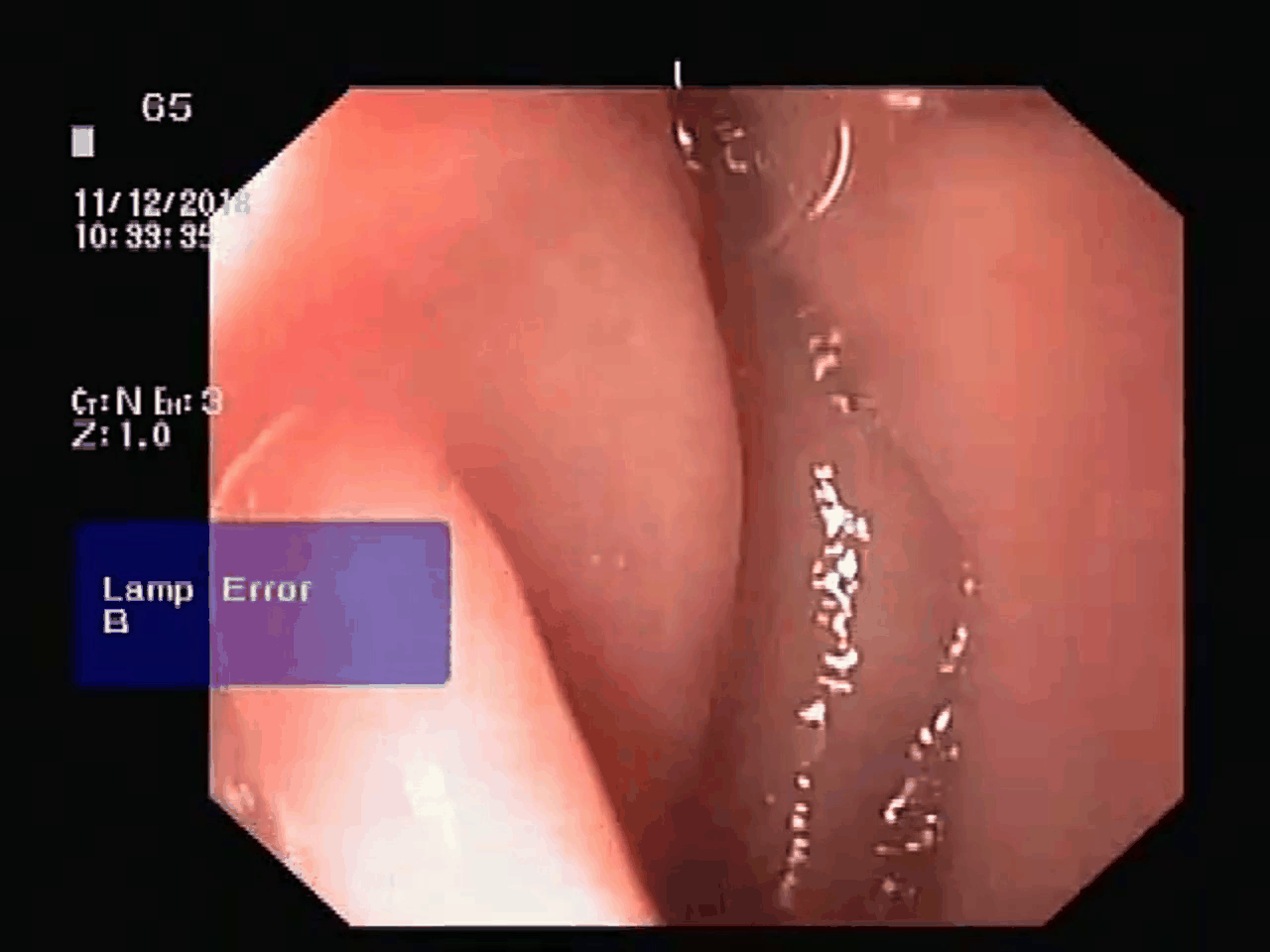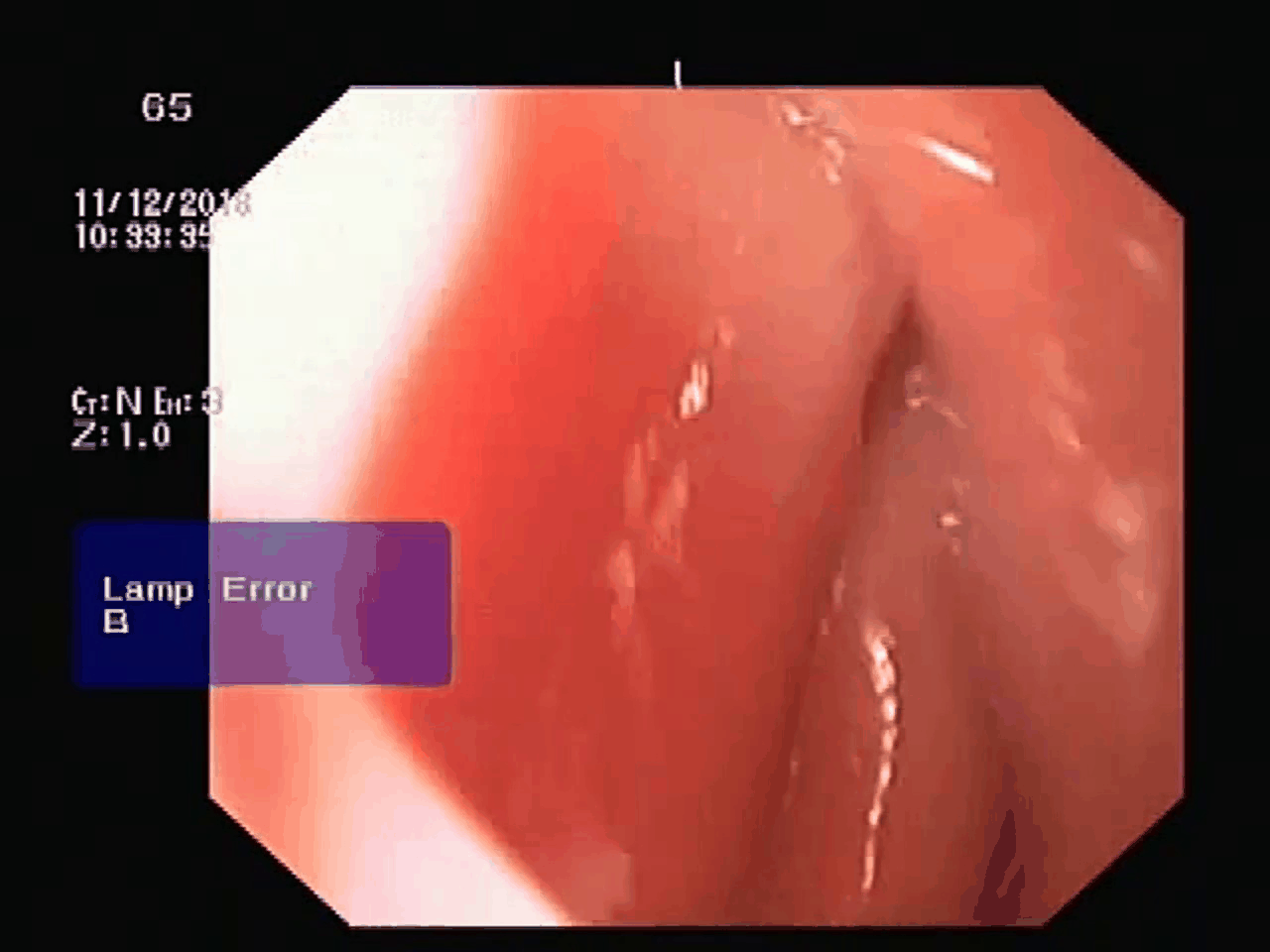
original video with 70 frames after summarizing
To use this repository you need to follow the following steps
create virtual environment if you wish
pip install --user virtualenv
python -m venv <environment_name>
- On windows
.\<environment_name>\Scripts\activate
- On linux or mac
source envoronment_name>/bin/activate
Then install the all required packages from requirement.txt after setting this repo as current directory
pip install -r requirement.txt
scikit-video package that was used here to read videos in quick manner , to use the scikit video ,your system should have the ffmpeg library for skvideo reading by streaming the video , so if you dont have that one dont worry follow the guidlines
- on linux or mac
sudo apt-get install --no-install-recommends ffmpeg && pip install ffmpeg scikit-video
*on Windows
Permanent Solution
on windows download the ffmpeg library using this ffmpeg widows stable version build link
unzip the folder and place it on any disk you want
copy the path of its bin folder and set environment variable
Temproary solution place this code at begining of whereever you use skvideo package
import skvideo
import skvideo.io
skvideo.setFFmpegPath(<path to the bin folder of ffmpeg>);
python get_frames.py
this will extract all frames of each video and put it in the ./dataset//allframes directory
python data_generator.py
this will generate meta information for your videos in data.csv file in ./dataset folder for your videos
Note
if you want to add data in train set then put video in ./dataset/videos/.mp4 directory and if you want add ground >truth keyframe then add that ./dataset//keyframes/frames.jpg directory path
python feature_extractor.py
python train.py
model structure and trained weights will be saved in saved_model directory
python predict.py
you can change the path of test video in the predict.py file ,path variable
I ve added the note book of vgg activation visualization in the visualization folder to show how the encoder pass the >necessary info to the decoder by eliminating portions