The Sliced Word Embedding Association Test (SWEAT) is a statistical measure of relative semantic polarization for pairs of textual corpora. SWEAT appears in the proceedings of EMNLP2021 (Preprint).
The measure relies on aligned distributional representations for the elements of each corpora vocabulary, specifically aligned Word2Vec gensim models such as those obtained through TWEC are assumed in this implementation. While any pair of Word2Vec models can be used, alignment is necessary to ensure that the two distributional representations are comparable.
The SWEAT is an extension of the Word Embedding Association Test (WEAT) proposed by Caliskan et al. (2017): while the WEAT measured the comparative polarization for a pair of topical wordsets (e.g. insects and flowers) against a pair of attribute wordsets (e.g. pleasant and unpleasant) in a single-corpus distributional model (e.g. 1950 american newspaper articles) the SWEAT measures the relative polarization for a single topical wordset (e.g. parenting) against a pair of stable attribute wordsets (e.g. positive and negative sentiment valence) in a pair of aligned distributional models from two different corpora (e.g. r/childfree and r/BabyBumps).
@inproceedings{bianchi2021sweat,
title={SWEAT: Scoring Polarization of Topics across Different Corpora},
author={Federico Bianchi and Marco Marelli and Paolo Nicoli and Matteo Palmonari},
year={2021},
booktitle={EMNLP},
}
First it is necessary to load the aligned Word2Vec models and, using an annotated lexicon, select the possible polarization attribute wordsets through the Lexicon Refinement Pipeline (LRP).
The LRP is implemented in the lexicon_refinement function of the utils module, taking as arguments a lexicon dictionary and both a tuple of modules and corpora; its output is a pandas Series having the stable lexicon elements (e.g. words) as index and the associated polarity as values.
NB: from the LRP output it is necessary to manually select two polarity wordsets A and B of equal cardinality.
# load aligned models
model_slice_one = Word2Vec.load.("path/to/slice_one.model")
model_slice_two = Word2Vec.load.("path/to/slice_two.model")
models = [model_slice_one, model_slice_two]
corpora = [ "path/to/slice_one_corpus.txt", "path/to/slice_two_corpus.txt"]
with open("path/to/lexicon.json") as fin:
lex_dict = json.load(fin)
stable_lexicon = lexicon_refinement(lex_dict, models, corpora)Once the polarization wordsets are selected from the LRP output it is possible to istantiate the SWEAT class and test the polarity of topical wordsets
# istantiate SWEAT class
swt = SWEAT(slice_one, slice_two, A, B)
# optionally it is possible to specify wordsets and slice labels using the names argument
swt = SWEAT(slice_one, slice_two, A, B, names = {"X1": "slice_one", "X2" : "slice_two", "A":"positive", "B":"negative"} )Having instantiated the class it is now possible to apply the relative polarization test to a topical wordset X; two explorative visualizations are implemented to aid result investigation. The test results are returned as a dictionary with keys "score", "eff_size" and "p-val" containing the SWEAT score, its effect size and p-value respectively.
# test topical wordset X
print(swt.test(X))>>> {'score': 0.2973, 'eff_size': 2.0709, 'p-val': 0.0003}
The two explorative visualizations illustrate are called using the plot_cumulative and plot_details methods respectively.
The first is a breakdown of the cumulative differences in polarizations for the two corpora, each represented as a colored barcharts where the colored areas represent the sums, over all elements of the topic wordset X, of the single-word associations to the two polarity wordsets. The black dot represent the cumulative association, i.e. one of the two sums over X of the SWEAT score formula.
# plot cumulative visualizations
swt.plot_cumulative(X)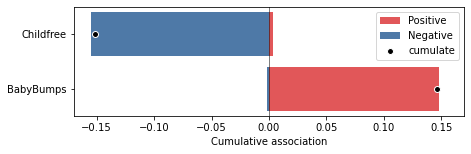
The second is a detailed breakdown of the single-word associations for the elements of the topic wordset X: for each topic word two pairs of boxplots are represented, one pair for each corpora. The two boxplots in the pair illustrate the distribution of the cosine similarity scores for the given topic word to all the elements of the two polarization wordsets. The offset bewteen the respective distribtion means is color-coded to indicate the "dominant" association which will in turn contribute to the cumulative score.
# plot details visualizations
swt.plot_details(X)