PyTorch implementation of Image-to-Image Translation with Conditional Adversarial Nets (pix2pix)
- Image size: 256x256
- Number of training images: 400
- Number of test images: 106
- Adam optimizer is used. Learning rate = 0.0002, batch size = 1, # of epochs = 200:
| GAN losses ( |
Generated images (Input / Generated / Target) |
|---|---|
 |
 |
-
Generated images using test data
1st column: Input / 2nd column: Generated / 3rd column: Target 







- Image size: 256x256
- Number of training images: 2,975
- Number of test images: 500
- Adam optimizer is used. Learning rate = 0.0002, batch size = 1, # of epochs = 200:
| GAN losses ( |
Generated images (Input / Generated / Target) |
|---|---|
 |
 |
-
Generated images using test data
1st column: Input / 2nd column: Generated / 3rd column: Target 







- Image is resized to 256x256 image (Original size: 600x600)
- Number of training images: 1,096
- Number of test images: 1,098
- Adam optimizer is used. Learning rate = 0.0002, batch size = 1, # of epochs = 200:
| GAN losses ( |
Generated images (Input / Generated / Target) |
|---|---|
 |
 |
-
Generated images using test data
1st column: Input / 2nd column: Generated / 3rd column: Target 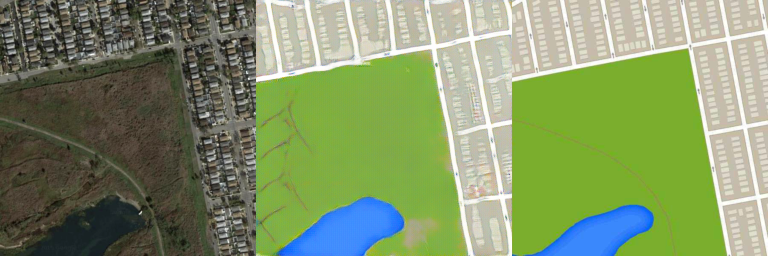
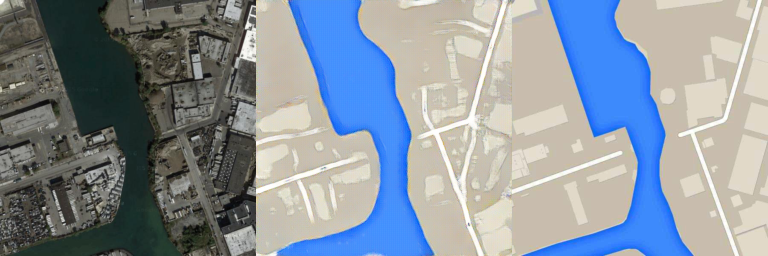
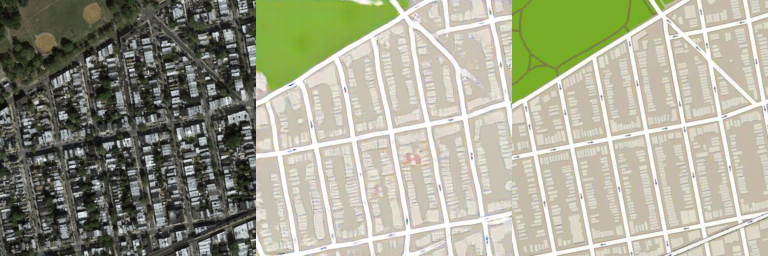




- Image size: 256x256
- Number of training images: 49,825
- Number of test images: 200
- Adam optimizer is used. Learning rate = 0.0002, batch size = 4, # of epochs = 15:
| GAN losses ( |
Generated images (Input / Generated / Target) |
|---|---|
 |
 |
-
Generated images using test data
1st column: Input / 2nd column: Generated / 3rd column: Target 







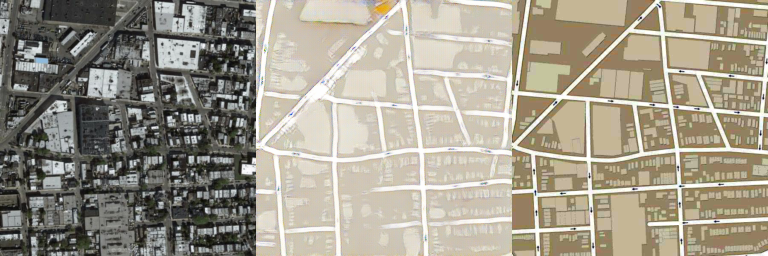
- Image size: 256x256
- Number of training images: 138,567
- Number of test images: 200
- Adam optimizer is used. Learning rate = 0.0002, batch size = 4, # of epochs = 15:
| GAN losses ( |
Generated images (Input / Generated / Target) |
|---|---|
 |
 |
-
Generated images using test data
1st column: Input / 2nd column: Generated / 3rd column: Target 






