This repo contains terraform templates and scripts for provisioning a E2 Databricks Workspace on AWS with PrivateLink. It includes all the AWS VPC infrastructure provisioning.
The following diagram describes E2 Databricks deployment architecture for these Terraform templates
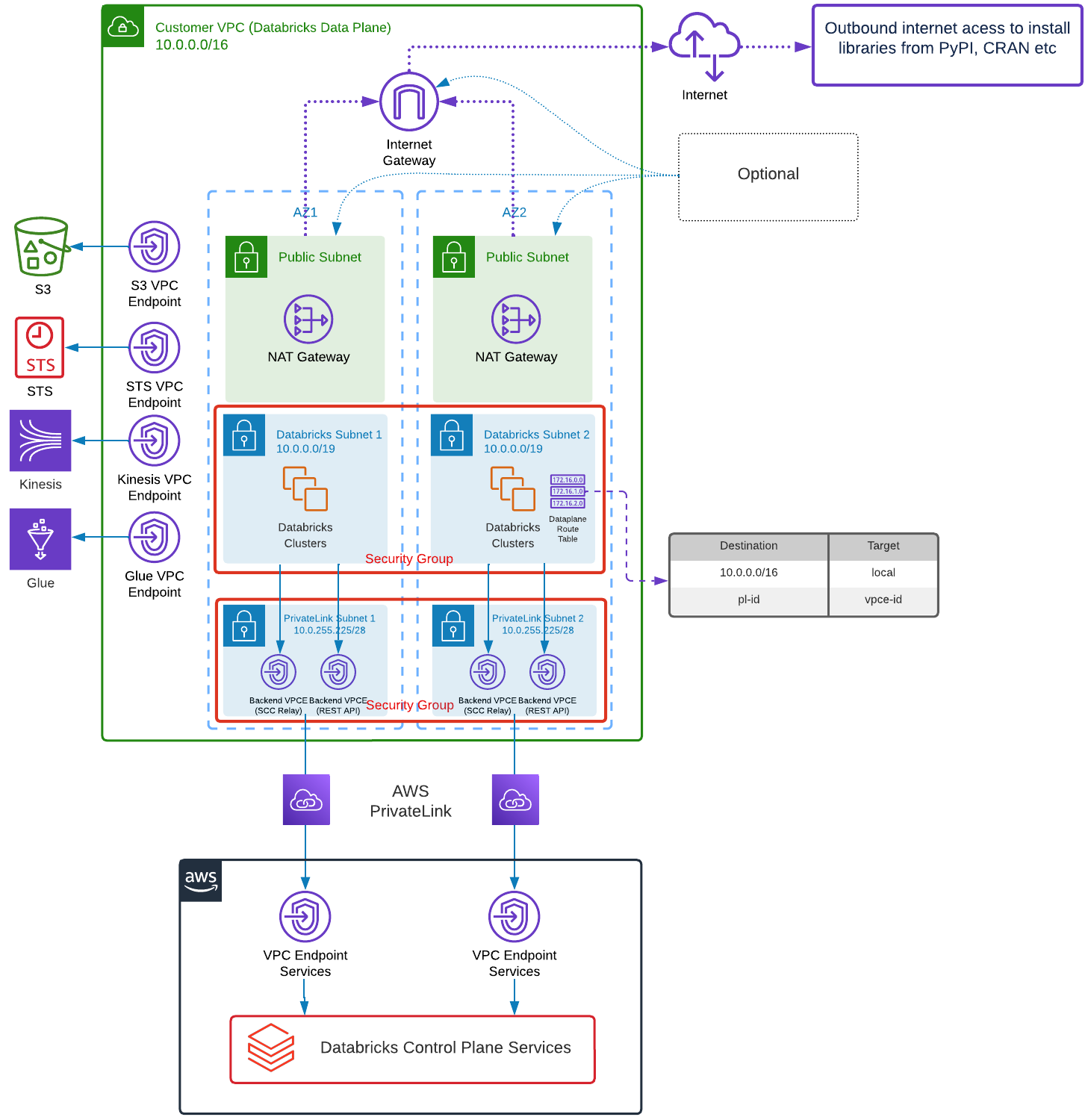
Running the templates will do the following:
- Provision AWS VPC in ap-southeast-2 region with 2 subnets in different AZs for the Workspace and 2 subnets in different AZs for PL (for redundancy). AWS Region can also be specified with -r argument, see Usage section below.
- By default VPC CIDR is 10.0.0.0/16 and subnets 10.0.0.0/19. This gives you over 8000 IP addresses per subnet/AZ, so over 4000 cluster nodes. If you want to adjust these ranges you can modify cidr_block_prefix and subnet_offset variables in provision/variables.tf file before running the template. Keep in mind that subnet netmask must be between /17 and /26 and you need to fit at least 2 Workspace subnets in different AZs. In addition, you need smaller subnets for PL and NAT, if choosing that option. This means subnet_offset should not be less than 2 (so 2 bits to allow space for 2 Workspace subnets and space for additional small subnets). You only need to specify cidr_block_prefix and subnet_offset variables, the template works out cidr for small subnets out of available space.
- Provision Databricks PL for REST API and Relay integration and S3, STS, Kinesis, Glue PL for AWS
- By default the templates will create and configure Customer Managed Keys for encryption of managed services (i.e. Notebooks, Metastore in Control Plane etc) and root S3 bucket storage. These can be individually turned off using script arguments described in Usage section below.
- Provision Usage and Audit Log Delivery bucket and related AWS resources. Note, Usage and Log Delivery is provisioned independently of Workspaces because this is Databricks Account level configuration across Workspaces. Once provisioned destroying Workspaces will not also destroy Usage and Audit Log Delivery bucket and infrastructure. If you really want to destroy those, run destroy.sh script with --account-level argument.
- Provision E2 Databricks Workspace objects through Account API
- Provision initial IAM Role with access to Glue Catalog
- Create a Test cluster with access to Glue Catalog and a Test Notebook to test the setup
Note, by default, the templates provision Back End Data Plane to Control Plane VPC Endpoints and allow public access for the Workspace UI. If you wish to also configure Front End VPC Endpoint you can pass --front_end_pl_subnet_ids and --front_end_pl_source_subnet_ids arguments to configure.sh script. Each of these arguments takes a comma separated list of AWS Subnet ids for existing subnets. If you are reusing the same VPC as Data Plane Workspace VPC for Front End VPC Endpoint don't pass --front_end_pl_subnet_ids, it will use the one it will create for Back End Workspace VPC. More details in Usage section below. You may also want to disable public access to the Workspace. You can do this by passing --front_end_access private argument to configure.sh script. Beware, if you do turn off public access, Workspace configuration template in workspace subdirectory would then need to be run from a VPN or VM that can reach the Workspace, since with public access off the Workspace APIs will be unreachable except where network routing to Front End VPC Endpoint is possible. In that scenario you may choose to run provision.sh script to only provision Databricks Workspace and run workspace.sh separately. These are described below.
There are 2 subdirectories, provision and workspace. Each contains individual terraform templates. provision will provision AWS VPC infrastructure and configure Databricks Workspace with Account API. After this template is run succesfully, the Workspace should be accessible through its url. workspace will use PAT created by provision step to configure a Cluster and a Notebook in the newly created Workspace. The whole thing is executed by running ./configure.sh script from root directory.
- Install Terraform. For Mac, this is described in https://learn.hashicorp.com/tutorials/terraform/install-cli.
- Clone this repo to your machine.
- Make sure you've configured your AWS CLI credentials with the AWS Account you want to deploy to.
- Create a file called secrets.tfvars in directory you will be calling configure.sh or the other scripts from. You can put secrets.tfvars in any directory of your choice, just make sure you are in that directory when calling configure.sh or other scripts. This file should have the following variables:
databricks_account_id = "<databricks account id>"
databricks_account_name = "<databricks account name>"
databricks_account_username = "<databricks account owner username>"
databricks_account_password = "<databricks account owner password>"
These are your Databricks Account Id that you can get from Databricks Account Console, your Databricks Account Name which will be used to prefix the name of Log Delivery S3 bucket and related AWS resources since these are account wide resources, your Databricks Account Owner User Name and Databricks Account Owner Password. If you don't have Databricks Account Id you can sign up for a 14 free trial in https://databricks.com/try-databricks to get it. Be careful with password as secrets in Terraform are stored in plain text. This is why secrets.tfvars file is in .gitignore
- Once you have created secrets.tfvars file, run configure.sh script and pass to it -w parameter. So for example, if you want to create a Databricks Workspace called demo, you would run ./configure.sh -w demo on command line.
- The script will apply the template in provision subdirectory and then run the template in workspace subdirectory.
- If the script runs successfully it will output the url of the newly created workspace that you can access. The Workspace will have a Test cluster and a Test Notebook, created by the templates. You can run Test Notebook on Test cluster to verify that everything is working as it should.
./configure.sh [-igw] [-nopl] [-nocmk all | managed | storage] [-w <workspace name>] [-r <aws region name>] [--front_end_access private|public] [--front_end_pl_subnet_ids <subnet_id1>,<subnet_id2>] [--front_end_pl_source_subnet_ids <subnet_id1>,<subnet_id2>]
| Argument | Description |
|---|---|
| -igw | - optional, if specified will still deploy with PL but also with NAT and IGW. Default is to deploy without NAT and IGW. |
| -nopl | - optional, PrivateLink Workspace is created by default, if you don't want a PrivateLink Workspace specify this argument. No Databricks VPC Endpoints will be provisioned as a result and NAT and IGW will also be provisioned for outbound traffic. STS, Kinesis, S3 and Glue VPC Endpoints will still be provisioned. |
| -w <workspace name> | - optional, deployment artefacts will have specified <workspace name> prefix and the Workspace will be named <workspace name>. If not specified will default to terratest-<random string> |
| -r <aws region name> | - optional, if not specified default region is ap-southeast-2, otherwise specify appropriate aws region here e.g. ap-southeast-1 |
| ‑nocmk all | managed | storage | - optional, Customer Managed Keys are created and configured for both managed services and root S3 bucket storage. This can be turned off. If you specify all, no CMK keys will be configured at all and default encryption in Control Plane will be used. If you specify managed, no managed services CMK encryption will be provisioned and default Control Plane encryption will be used instead. If you specify storage, no storage root S3 bucket CMK encryption will be provisioned and default Control Plane encryption will be used instead |
| ‑‑front_end_pl_subnet_ids <subnet_id1>,<subnet_id2> | - optional, Specify AWS Subnet ids, 1 or more, where Front End Databricks Workspace VPC Endpoint will be provisioned. If the subnets are the same as the Workspace subnets omit this argument |
| ‑‑front_end_pl_source_subnet_ids <subnet_id1>,<subnet_id2> | - optional, Specify AWS Subnet ids, 1 or more, which will route Databricks Front End Workspace traffic to the Front End VPC Endpoint. This could be your Direct Connect Transit VPC Subnet. If this is the same as the subnets used for --front_end_pl_subnet_ids above, omit this argument. Note if these subnets are in a different VPC to where you deploying Front End VPC Endpoint i.e. subnets of --front_end_pl_subnet_ids argument above, the traffic must be routable from this VPC to the Front End VPC |
| --front_end_access private | public | - optional, Specify whether you still wish to allow public Internet access to your Workspace URL or not. If you deny public access and you are running these templates from a VM that is not routable to Front End VPC Endpoint subnets specified in --front_end_pl_subnet_ids, the workspace templates will not be able to access the Workspace APIs |
| -no-al | --no-account-level | - optional, Specify whether you want to bypass deploying any Account Level resources (Audit/Usage/Billing logging). By default, if these are already deployed and terraform state is available the deployment will be bypassed anyway, but sometimes it's useful to explictly bypass |
| -al | --account-level | - optional, Specify whether you only want to deploy Account Level resources (Audit/Usage/Billing logging). By default, if these are not already deployed or terraform state is not available the deployment will be done for Account Level resources anyway. However if you want to only deploy Account Level resources and nothing else, specify this option |
| -ap <profile name> | --aws-profile <profile name> | - optional, if not specified default profile is used, Specify which profile configured by aws cli to use for interacting with AWS Account |
| -razt <total number of AZs or all> | --required-az-total <total number of AZs or all> | - optional, defaults to 2 if not specified, Specify how many AWS Availability Zones to configure for the Databricks Workspace VPC infrastructure. Minimum value is 2, cannot be higher than number of AWS Availability Zones in the region. If all is specifiied will configure infrastructure for all AWS Availability Zones in region |
| -nodp | --no-deployment-prefix | - optional, if deployment prefix is not configured for Databricks Account, specify this option for Databricks to generate a random Workspace url and avoid an error complaining about deployment prefix not being configured |
Let's assume you want to deploy a workspace called 'my-workspace' and you don't want to provision Customer Managed Keys for encryption of Managed Services objects and Root S3 Storage, and you want to deploy Front End Workspace VPC Endpoint into a VPC Subnet separate from the Workspace VPC which will be created by the template, let's assume the AWS Subnet Id in this VPC Endpoint is 'subnet-0c00ac0320cba6d93' and you want to route traffic to this subnet from another subnet in a different VPC, let's assume that subnet's AWS Subnet Id is 'subnet-ad00ac0320cba6e00'. Then the command line to configure the Workspace would be:
./configure.sh ‑w my‑workspace ‑nocmk all ‑‑front_end_pl_subnet_ids subnet‑0c00ac0320cba6d93 ‑‑front_end_pl_source_subnet_ids subnet‑ad00ac0320cba6e00
You may also run provision script independendently from workspace script. There is provision.sh script which is also called from configure.sh script that you can run which will only provision the Workspace. The arguments to provision.sh script are the same as configure.sh script described above. Subsequently, workspace.sh script can be run separately to configure the provisioned Databrticks Workspace objects such as Clusters, Notebooks etc. workspace.sh script only takes an optional -w <workspace name> argument to execute for workspace which has already been created. If no arguments are passed it will execute for active workspace i.e. terraform workspace that is currently active or workspace for which configure.sh or provisionn.sh was last executed. workspace.sh will access terraform state that was created as part of running provision.sh for a specified terraform workspace. However it only needs databricks_host (Worlspace URL) and databricks_token (PAT Token to authenticate to Workspace REST API), hence these can also be specified directly in workspace/main.tf template.
If there are some AWS resources, created outside of Terraform, you don't wish to be created by the template, but instead would like to reuse when creating AWS infrastructure for the Workspace, you can run provision.sh script with -import argument. Import accepts the name of the AWS resource as specified in terraform templates and the AWS Id of the resources. For example, if you want to import already created S3 bucket as root bucket called rootbucket-my-workspace for your workspace called workspace you can run:
./provision.sh ‑w my-workspace ‑import aws_s3_bucket.root_storage_bucket rootbucket-my-workspace
Running ./configure.sh script for my-workspace workspace after this will not create the bucket and will use the imported bucket instead for root S3 bucket.
NOTE, be careful running destroy.sh. By default destroy.sh will tear down Databricks Workspace and all provisioned infrastructure Databricks and AWS. To tear down deployment after you've run configure.sh script, there is a destroy.sh script. Running destroy.sh only takes an optional -w <workspace name> argument to execute for workspace which has previously been created. Executing destroy.sh without arguments will execute for active terraform workspace or workspace for which configure.sh was last executed. Terraform maintains state of deployment in a state file as deployment steps are executed and it simply reverses the steps that were executed when deploying and cleanly deletes all the resources that were previosly deployed. By default, destroy.sh will not destroy Account level resources like Usage and Audit Log Delivery bucket and infrastructure. To destroy those, run destroy.sh script with --account-level or -al argument. You can also pass --workpace-content-only or -wco argument to destroy.sh. This will not tear down provisioned Databricks Workspace and only tear down any resources created in workspace module, so any Databricks objects like Clusters, Notebooks etc.
- If you are creating a PL Databricks Workspace the S3 VPC Gateway prevents access to global S3 url. Access to regional one only is allowed. For PL Workspaces with newly created S3 buckets sometimes it may take a bit of time to gain access to regional root S3 bucket, bypassing S3 global url. It may happen that running Test Notebook hangs due to trying to resolve S3 root bucket for DBFS mounts. In that case leaving the Workspace for an hour or so resolves the issue eventually. Alternatively you can run with configure.sh with additional -igw flag. This will still deploy PrivateLink but also deploy NAT and IGW to allow outbound Internet access for any IPs not going via PrivateLink. In this case global S3 url is resolvable and everything works as expected.
- Feel free to use these templates as you see fit. If you wish to alter them to suit your needs please fork this repo and add your changes there.