Hierarchy decomposition pipeline is a supervised machine learning tool that constructs random forest ensembles from data sets with hierarchical class.
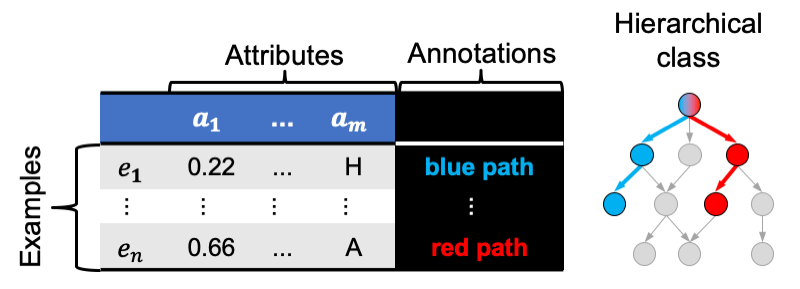
Suitable data sets have:
- Class labels organised in a hierarchy
- Hierarchy in the shape of a tree or directed acyclic graph
- Examples annotated with one or several paths from the hierarchy
- Five algorithms that construct ensemble models from data sets with hierarchical class
- Tool that estimates models' predictive performance using cross-validation
- Tool for predicting paths from the hierarchy that best describe unlabelled examples
- Tool that computes data set properties
- Prerequisite to run the pipeline is Java 8
- Download the JAR file
- Download a data set from the repository or use your own data set in HARFF format
- Create settings file
- Assuming that the JAR file and settings file (e.g., named settings.s) are in the same folder, run the pipeline by typing:
java -jar hierarchy-decomposition-pipeline-0.0.1.jar settings.s
The pipeline is based on ideas presented in the following paper:
Vidulin V., Džeroski S. (2020) Hierarchy Decomposition Pipeline: A Toolbox for Comparison of Model Induction Algorithms on Hierarchical Multi-label Classification Problems. In: Appice A., Tsoumakas G., Manolopoulos Y., Matwin S. (eds) Discovery Science. DS 2020. Lecture Notes in Computer Science, vol 12323. Springer, Cham. https://doi.org/10.1007/978-3-030-61527-7_32
If you find the pipeline useful, please cite that reference.
If you have a data mining problem with hierarchical class and are interested in cooperation, feel free to contact me.
The pipeline is described in more detail on the project website.
This project is a work in progress. If you have any problems with the code or documentation please report as issues.