📌 프로젝트 개요
Problem Type. 마스크 착용 여부(Wear, Incorrect, Not Wear) , gender(Male, Female)나 이(<30, ≥30 and < 60, ≥ 60)를 기준으로 18개 class 분류
Metric. Macro F1 Score
Data. 총 2,700명의 384 x 512 이미지. 한 명당 7장(마스크 착용 x 5, 미착용 x 1, 불완전 착용 x 1)
📌 개발환경 & 협업툴
-
개발환경
개발환경 버전 VSCode 1.60.0 PyTorch (GPU) 1.7.1 Python 3.8.5 GPU V100
- 공통 : 가설실험 및 학습
- Dataset Part → 김창현, 손정균
- Model Part → 김규리
- Engineering Part → 박정현, 석진혁
📌 Workspace file & directory
├── input
│ └── data
│ ├── eval
│ └── train
├── output
│ └── output.csv
└── code
├── dataset.py
├── loss.py
├── model.py
├── train.py
└── inference.py
Train
Python train.py —criterion 'label_smoothing' --optimizer 'AdamW' --valid_batch_size 3780 --model "Model" --name "EfficientNet" --epoch 10

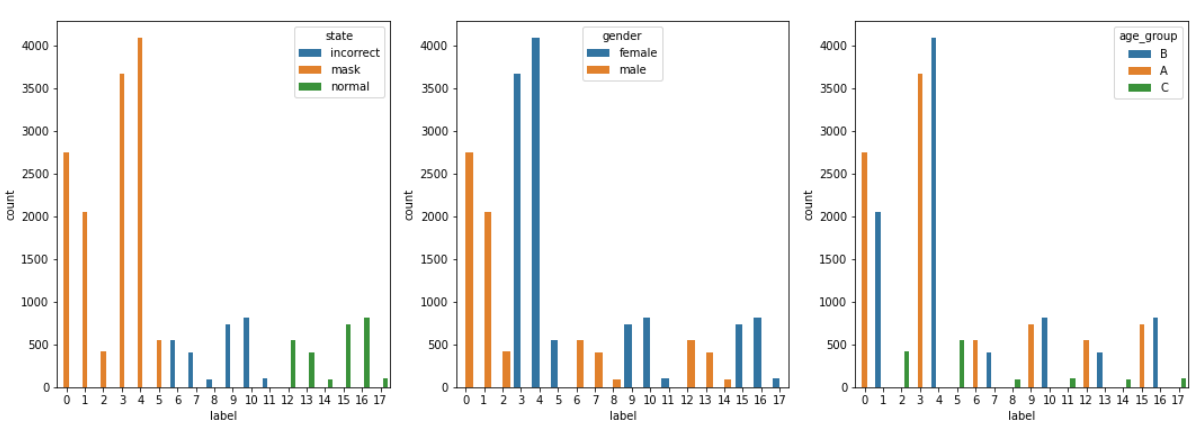
- Mask, Gender, Age에 대한 전체 Class 분포
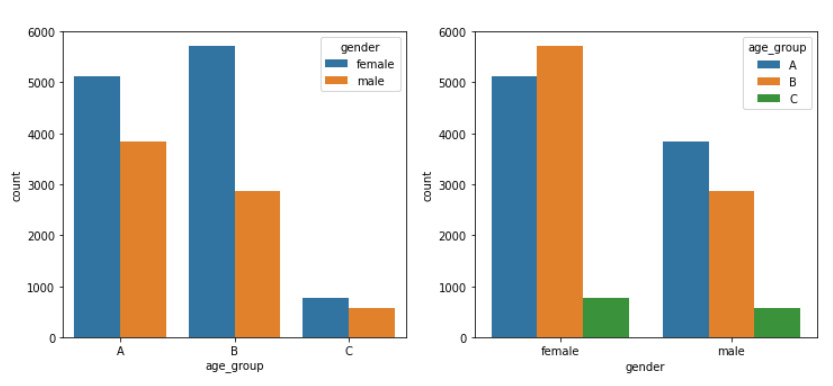
- Age와 Gender간의 관계
📌 Efficientnet b4
- optimizer : AdamW
- img_size : 224 x 224
- scheduler : cosine_annealing_warm_restart
- batch_size : 128, val_batch_size : 128
- epochs : 10, lr : 1e-3
- loss : label_smoothing(class=18, smooth=0.1)
초기 베이스라인 구축을 위해 선택할 모델로 적은 Parameter대비 성능이 좋고 효율적인 Efficientnet을 사용. b0를 사용해 빠르게 기본성능을 테스트하고 b4로 변경해 성능 향상 확인 이후 b6, b7을 사용하여 봤으나 파라미터터 증가로 인해 학습시간은 증가하고 성능은 오히려 하락해 Efficientnet b4을 채택
📌 Input Image Size
빠른 학습을 위해 Efficientnet-b0의 input size인 (224, 224)를 사용 후반부에 b4모델의 input_size인 (380, 380)을 사용하여 학습진행시 train, val에서 좋은 지표를 보였으나 실제 LB에서는 유의미한 결과를 얻지 못하였음
📌 optimizer
일반적으로 만능이라 알려진 Adam의 경우 CV에서는 momentum을 포함한 SGD에 비해 일반화가 뒤쳐진다는 연구결과가 있음, 이 문제점을 극복한 AdamW를 사용해 일반화 성능을 높이기 위해 AdamW를 선택
📌 loss
val acc, f1와 LB의 점수차이가 많이 나는 현상과 라벨링이 잘못된 일부 데이터를 확인결과 over-confidence문제로 확인하여모델 보정(calibration)을 위해 label_smoothing을 선택
📌 Over Sampling
- 가설
- EDA결과 여러 연령대 중에서 30,40,60대의 수가 다른 연령대에 비해 상당히 적음. 이 연령대에 속하는 사람들에 대해서만 Over sampling을 진행하면 좀 더 균형있는 학습을 진행할 수 있을거라 가정
- 결과
- 기존 데이터셋 에서 위의 연령대를 Over sampling한 결과 Public Score가 약 0.02 상승(0.7261 -> 0.7466)
- 기존 데이터셋 에서 위의 연령대를 두번 Over sampling한 결과 Public Score가 약 0.04 상승(0.7466 -> 0.7667)
- 기존 데이터셋 에서 위의 연령대를 세번 Over sampling한 결과 Public Score가 하락(0.7667 -> 0.7223)
- 정리
- Over sampling을 적용한 후 model의 f1-score가 상승함. 하지만 이 Over sampling을 단순히 여러번 적용 한다고 해서 성능이 계속해서 상승되는건 아님. Over sampling 특성상 동일한 입력데이터에 대해 여러번 학습하게 되면 overfitting의 문제점이 생기게 되는데, 이러한 약점 때문에 특정 기준이상의 Over sampling은 오히려 모델 성능에 방해가 되었다고 생각됨.
📌 나이 라벨링 기준 수정
- 가설
- 기존의 데이터 셋에서 60대 이상에 속하는 사람의 수는 다른 연령에 비해 현저하게 적음. 60대에 대한 정보를 더 얻어내기 위해 58세 이상인 사람은 모두 60대라고 가정하고 학습을 해볼 것. 이로인해 모델이 60대에 대해서 좀 더 강건한 성능을 보여줄 것이라 가정
- 결과
- 60대의 라벨링의 기준을 60에서 58으로 줄인 결과 f1-score가 상승 (0.7622→ 0.7647)
- 정리
- 연령 문제를 Classification이 아닌 Regression의 관점으로 풀어보면 어떨까 하는 아쉬움이 있음. 넓게 퍼진 나이에 대한 분포를 3개의 class로 분류하는 것보다 회귀의 문제로 모델에 학습시키면 모델이 각 사람의 나이에 대한 특징을 더 잘 찾아낼 수 있지 않을까 궁금해 졌음.
📌 stratified K fold
-
상황
- 18900장 input data중 4번 label의 data가 4085장, 8번 label의 data가 109장으로 label 분포가 매우 불균형한 상황.
-
가설
- 여기서 dataset을 무작위로 train_set, val_set으로 분리해서 특정 label이 train_set에 분배되지 못하는 상황이 나오면 특정 라벨에 대한 성능이 떨어질 것으로 가정.
- Stratified K fold X : 0.7667 Stratified 5 fold : 0.7653 Stratified 10 fold : 0.7622
- Public + Private set 에서의 결과는 일반성 검증인 skf를 적용한 것이 성능이 더 좋을 것으로 예상
-
결과
-
예상과는 다르게 Public + Private에서의 f1 score는 다음과 같이 계산됐음. skf x : (0.7667 -> 0.7629) skf 5 : (0.7653 -> 0.7556) skf 10 : (0.7622 -> 0.7434) 일반성검증 후 (Public + Private data)에서 성능이 안 좋아진 것을 확인
soft voting으로 앙상블 적용
-
📌 Split by Profile
- 상황
- 2700명의 profile에서 1장의 Not Wear, 5장의 Wear, 1장의 Incorrect
- 가정
- 한 사람의 Not Wear가 train set과 val set에 나눠서 분배되면 학습과정에서 cheating이 일어날 것으로 가정. 일반적 성능을 위해 profile로 나눠야한다고 가정
- 결과
- Public set에 대해 f1 score : 0.7434로 떨어졌으므로 적용 X 여러 사람의 mask wear 대신 한사람의 wear가 입력되면 학습과정에서 다양한 패턴의 마스크 쓴 사람을 입력 받지 못하고 한 장의 mask쓴 사진이 여러번 입력된 것과 같은 상황이라고 생각됨.
📌 MixUp / TTA
- 가설
- Mixup/TTA를 적용하면 f1 score가 조금 올라갈 것으로 예상을 하고 Mixup/TTA를 적용
- 결과
- TTA 적용 하기 전 : 0.6654 → 0.6514
- TTA 적용 후 : 0.6630 → 0.6567
- MixUp 적용 하기 전 : 0.7519 → 0.7416
- MixUp 적용 후 : 0.7637 → 0.7532
- 정리
- MixUp을 적용한 결과는 예상대로 f1 score가 조금 높아짐.
- TTA는 시간이 부족하여 여러 시도를 해보지는 못하고 Horizontal Flip을 적용해본 결과 오히려 f1 score가 조금 낮아짐. 큰 의미는 없을 것으로 판단하고 더 이상 TTA는 적용시켜보지 않았는데 private에서는 처음 예상했던 대로 0.005정도 높게 나옴. Horizontal Flip만이 아니라 다른 augmentation들도 적용해보면서 실험을 더 많이 해봤으면 하는 아쉬움이 남음..
최종 LB Score
Public : 0.7667(8등 / 48 team) Private : 0.7556 (8등 / 48 team)