📌 프로젝트 개요
Problem Type : 사진에서 쓰레기 Segmentation 및 11 종류(Background,General trash, Paper, Paper pack, Metal, Glass, Plastic, Styrofoam, Plastic bag, Battery, Clothing) 의 쓰레기 분류
Metric : mIoU
Data : 총 3,272장의 train image, 819장의 test image (512 x 512), annotation file (coco format)
📌 개발환경 & 협업툴
-
개발환경
개발환경 버전 VSCode 1.60.0 segmentation-models-pytorch 0.2.0 mmsegmentaion -
협업 Tool GitHub, Notion
📌 팀 구성 및 역할
-
김기태 : segformer, hrnet, gcnet 실험 및 segmentation_models로 efficientnet 계열 실험
-
박기련 : UperNet 기반 Swin-T로 실험 및 Swin-L, BeiT-L로 모델 학습
-
김창현 : Swin-L & UperNet으로 학습, oversampling 코드 제작
-
강소망 : Deeplabv3plus, hrnet/resnet 기반의 ocrnet 실험
-
박민수 : ConvNeXt 기반 UperNet 실험, 내부 평가 지표 Set 제작, Ensemble
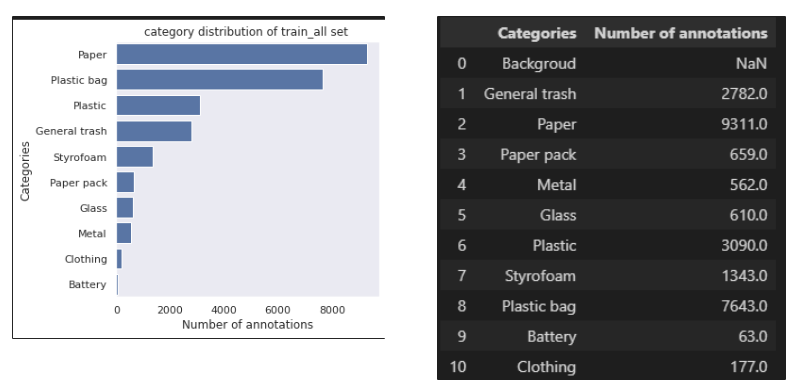
- Class별 분포 : 불균형으로 인한 문제가 발생할 여지가 있음
- Augmentation, Sampling, Loss measurement 를 통해 해결할 필요가 있음
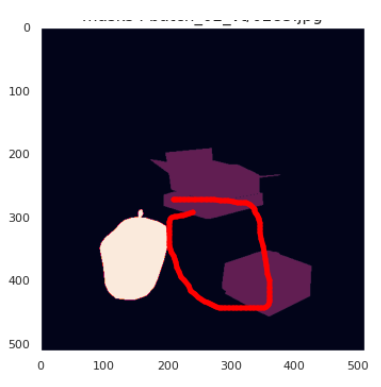
- 표시된 부분은 원본 이미지에서는 쓰레기통 부분이지만 전혀 labeling이 되어있지 않은 경우도 있어서 Noise가 존재함
📌 Validation Set 통일
-
하루 10회로 한정된 제출 기회를 효율적으로 사용하기 위해, 내부 평가 지표 설정
-
Stratified K-Fold 를 이용하여 Class 를 균등하게 나눈 후, Fold 별로 동일한 모델 학습
-
LB Score 와 가장 근사한 Validation mIoU 를 가지는 Dataset을 공통 평가 지표로 설정
📌 Over Sampling
- 가설
- EDA결과 train set 3,4,5,9,10번 카테고리의 데이터가 다른 클래스에 비해 적은 것을 확인하고 해당 카테고리의 데이터를 증강
- 클래스별 분포 :
[2217, 7503, 533, 481, 495, 2500, 1108, 6201, 57, 143]
- 결과
- 기존 데이터셋에서 위의 카테고리를 Over Sampling한 결과 LB상 0.02 상승
- 3,4,5,9,10번 카테고리를 6배로 상승
- 정리
- Over sampling을 적용한 후 LB의 mIoU의 유의미한 상승을 확인
- 9번 카테고리의 데이터가 다른 클래스의 데이터보다 현저히 적어 증강을 했음에도 mIoU가 낮았음 ⇒ 좀 더 증강했으면 mIoU가 상승하지 않았을까 하는 아쉬움이 있음
📌 Albumentation
- RandomRotate90 , RandomFlip ( Horizion, Vertical )
- Rotate 를 시켜도 Object 의 형태는 동일하므로 데이터 증강의 목적으로 사용
- HueSaturationValue, RandomGamma, CLAHE [One of]
- 여러가지 밝기에 따른 일반화 성능 향상 도모
- Blur, GaussianNoise, MotionBlur [One of]
- 초점이 흐린 Image가 들어올 것을 대비
Result
Augmentation 적용 전 : ConvNeXt_L UperNet (0.6881) Augmentation 적용 후 : ConvNeXt_L UperNet (0.7114) → 약 0.04 상승
📌 Hard Voting
- 모델별로 클래스의 mIoU가 크게 차이나는 상황이 발생
- ex) 어떤 모델은 배터리의 mIoU가 20%인 반면 어떤 모델은 배터리의 mIoU가 60%
- 따라서 차이가 크게 나는 클래스에 대해 Hard Voting을 진행
| BackBone | Model | Val mIoU | LB Score | |
|---|---|---|---|---|
| 1 | Swin_T | UperNet | 0.6368 | 0.6162 |
| 2 | ConvNeXt_XL | UperNet | 0.7200 | 0.7114 |
| 3 | ConvNeXt_L | UperNet | 0.6493 | |
| 4 | Swin_L | UperNet | 0.7039 | 0.7111 |
| 5 | Beit_L | UperNet | 0.7114 | 0.7081 |
| 6 | ResNet101 | GCNet | 0.5992 | |
| 7 | HRNetv2_W48 | HRNet | 0.5643 | |
| 8 | HRNetv2_W48 | OCRNet | 0.6218 | 0.6262 |
| 9 | Efficientnet_B4 | Unet++ | 0.5606 | |
| 10 | MixVisionTransformer | SegFormer | 0.3 | |
| 11 | ResNet | Deeplabv3+ | 0.6012 |
📌 Ensemble
-
선정 기준
- LB Score 0.7 ↑
-
선정 모델 (LB Score)
-
- ConvNeXt_XL(22K) - UperNet (0.7114)
-
- Swin_L(22K) - UperNet (0.7111)
-
- Beit_L(22K) - UperNet (0.7081)
-
-
최종 LB Score
Public : 0.7337 Private : 0.7455 (9등 / 19 team)
📌 분석
- TTA (Flip) 와 Augmentation 을 모든 실험에 적용
- BackBone 을 ResNet → Swin 및 ConvNeXt 로 키워나감으로써 성능 ↑
- 전체적으로 Swin, ConvNeXt 기반 Model 성능이 압도적
- LB Score 를 끌어올리기 위해, Class 별 mIoU 를 분석 후, 서로 시너지를 낼 수 있는 모델끼리 Ensemble 진행