
Predicting the quality of wine through classification. Source: 'mirofoto', freeimages.com
In this repo I will use classification models to try and predict the quality of wine. The 1600 data samples comes from the UCI machine learning repository (that's a lot of wine!).
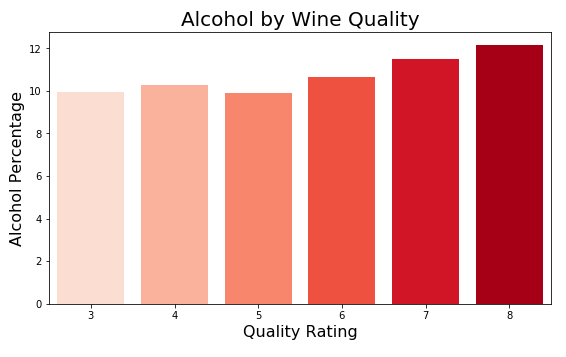
Alcohol seems to be related to the quality of wine.
- Introduction
- Project Summary
- Repo Contents
- Prerequisites
- Feature and Definitions
- Results
- Future Work
- Built With, Contributors, Authors, Acknowledgments
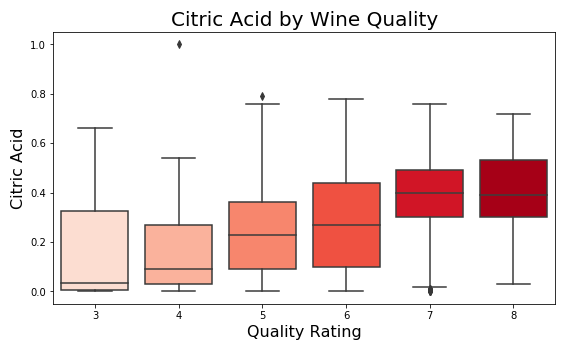
Citric Acid boxplot demonstrating the correlation with Quality and showing a few outliers.
This repo contains the following:
- README.md - this is where you are now!
- Notebook.ipynb - the Jupyter Notebook containing the finalized code for this project.
- LICENSE.md - the required license information.
- Blog Post - the link to my Medium blog post pertaining to this project.
- winequality-red.csv - the file containing the dataset in csv.
- CONTRIBUTING.md
- Images
These are the libraries that I used in this project.
- numpy as np
- pandas as pd
- matplotlib.pyplot as plt
- %matplotlib inline
- seaborn as sns
- folium
- datetime as dt
- from sklearn.model_selection import train_test_split
- from sklearn.model_selection import cross_val_score
- from sklearn.model_selection import GridSearchCV
- from sklearn.metrics import accuracy_score
- from sklearn.metrics import f1_score
- from sklearn.metrics import confusion_matrix
- from sklearn.metrics import classification_report
- from sklearn.metrics import confusion_matrix
- from sklearn.linear_model import LogisticRegression
- from sklearn.ensemble import RandomForestClassifier
- import xgboost as xgb
For more information, read [Cortez et al., 2009].
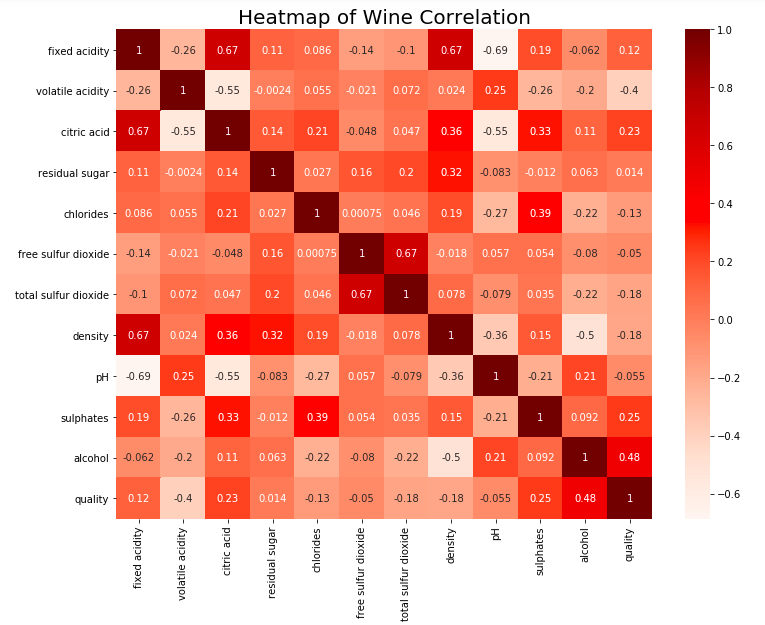
Input variables (based on physicochemical tests): 1 - fixed acidity 2 - volatile acidity 3 - citric acid 4 - residual sugar 5 - chlorides 6 - free sulfur dioxide 7 - total sulfur dioxide 8 - density 9 - pH 10 - sulphates 11 - alcohol Output variable/target (based on sensory data): 12 - quality (score between 0 and 10)
These are the models that I tried in this project:
- LogisticRegression
- Random Forest
- XGBoost
- K-Nearest Neighor (KNN)
- Support Vector Model (SVC)
- Stochastic Gradient Decent
All models had pretty similar accuracy scores, with the XGBoost validation accuracy coming out a bit on top at 89.71%. I only wish I had these statistics available (along with my model) to help me purchase my next bottle of wine!
I could use Grid Search to modify the parameters and try improve the performance of my models. I also could use Cross Validation Score to assess the effectiveness of my model, particularly in order to avoid over-fitting.

Which wine would you choose? Source: Carlos Sillero, freeimages.com
Jupyter Notebook Python 3.0 scikit.learn
Please read CONTRIBUTING.md for details
Thomas Whipple
Please read LICENSE.md for details
This dataset is also available from the UCI machine learning repository, https://archive.ics.uci.edu/ml/datasets/wine+quality , I just shared it to kaggle for convenience. (I am mistaken and the public license type disallowed me from doing so, I will take this down at first request. I am not the owner of this dataset.
Please include this citation if you plan to use this database: P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.