Written for this pattern(from wikipedia):
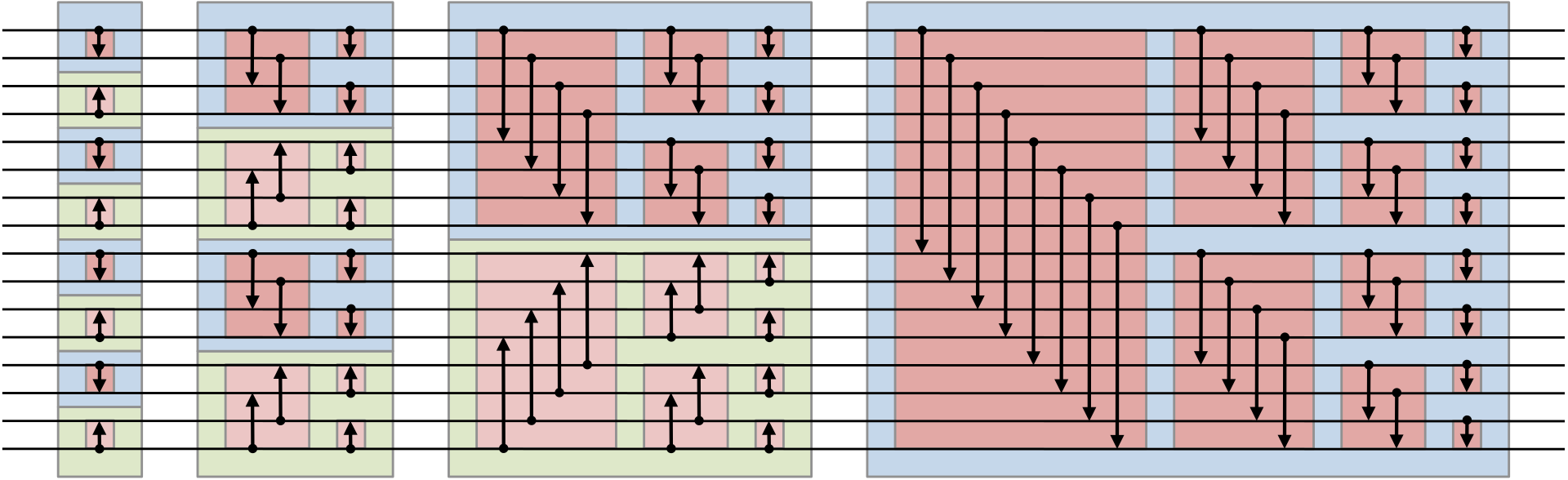
-test codes for sorting 64M float keys -only kernel codes. uses 1 float array to sort in-place. -uses dynamic parallelism feature of cuda -array size needs to be integer power of 2 and at least 8192
benchmark data:
Array elements GT1030 std::sort GTX1080ti
(benchmark) (1 core ) (guesstimate)
(no overclock)
1024 not applicable -
2048 not applicable -
4096 not applicable -
8192 363 µs 114 µs -
16k 463 ms 248 µs -
32k 746 µs 536 µs -
64k 1.23 ms 1.15 ms -
128k 2.32 ms 2.46 ms -
256k 4.87 ms 5.4 ms ~1.5+ 0.3 ms
512k 8.72 ms 11.7 ms ~3 + 0.5 ms
1M 18.3 ms 22 ms ~6 + 1.2 ms
2M 39 ms 48 ms ~12 + 2.7 ms
4M 86 ms 101 ms ~23 + 6.3 ms
8M 187 ms 211 ms ~47 + 14 ms
16M 407 ms 451 ms ~95 + 32 ms
32M 883 ms 940 ms ~190+ 70 ms
64M 1.93 s 2.0 s ~380+ 150 ms
(float keys) (copy+kernel ) (copy + kernel)
(using same pcie)
pcie v2.0 4x: 1.4GB/s
fx8150 @ 3.6GHz
4GB RAM 1333MHz
(single channel DDR3)