The project aim is to deploy Flink Server and submit batch job to Flink server instead of Dataflow server.
I don't find any comprehensive tutorial thus I write one.
- Enable the default service account to watch, create, delete pod
kubectl apply -f yaml/minikube-native-flink/access.yaml - Bind the role to default service account
kubectl create clusterrolebinding flink-role-pod \
--clusterrole=flink-role \
--serviceaccount=default:default- Download Flink 1.14 https://flink.apache.org/downloads.html#apache-flink-1150
- Extract and cd into Flink folder
./bin/kubernetes-session.sh -Dkubernetes.cluster-id=my-first-flink-cluster- Proxy the Web interface by
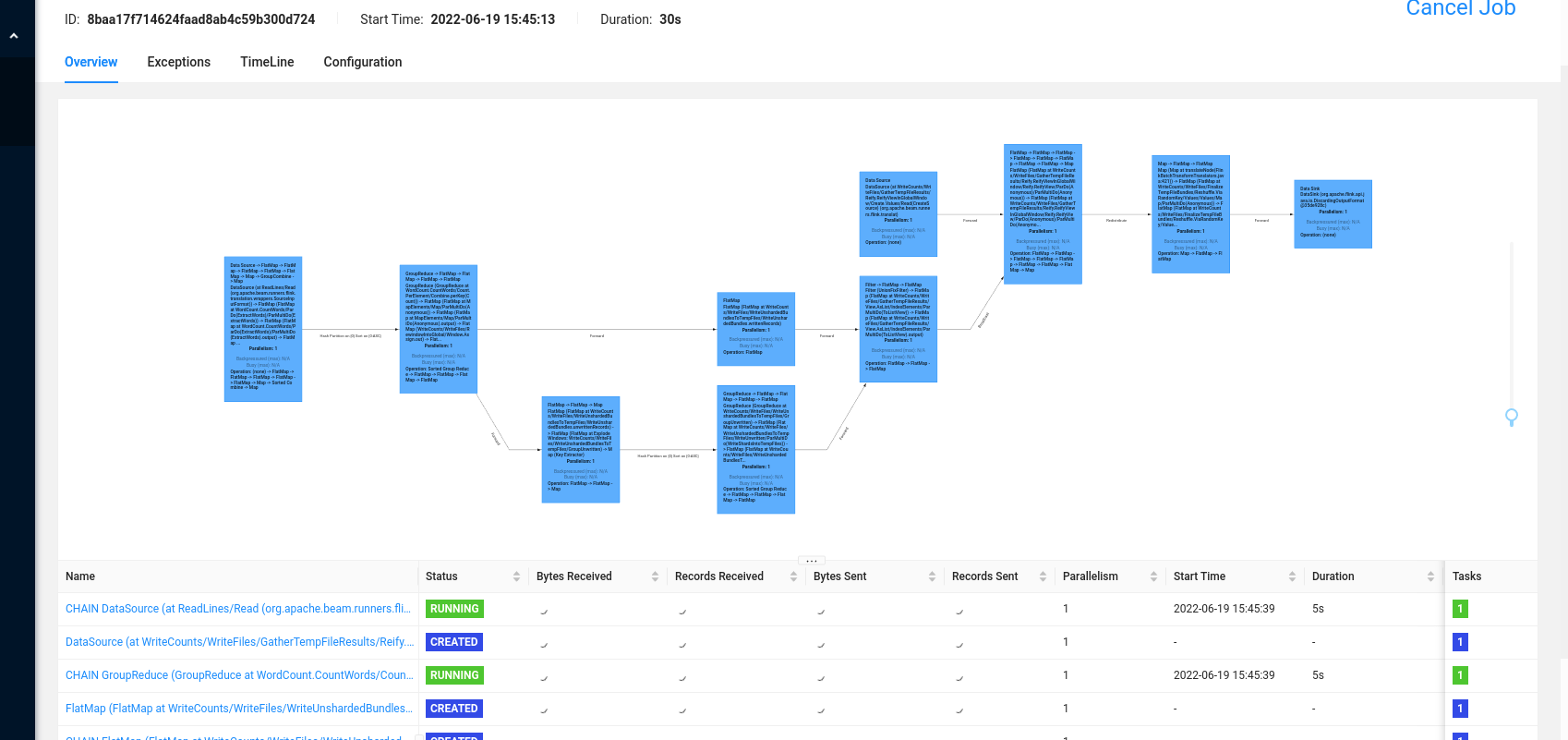
kubectl port-forward service/my-first-flink-cluster-rest 8081:8081 - Open http://localhost:8081 to view the Native Flink service
- Clone Apache word count project
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.39.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false && cd word-count-beam- Submit to Flink job
mvn package exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=FlinkRunner --flinkMaster=localhost:8081 --filesToStage=target/word-count-beam-bundled-0.1.jar \
--inputFile=gs://apache-beam-samples/shakespeare/* --output=/tmp/counts" -Pflink-runner- To Flink server http://localhost:8081, see result